
本文の内容は、2022年6月23日にCarlos Adiegoが投稿したブログ(https://sysdig.com/blog/fluentd-monitoring/)を元に日本語に翻訳・再構成した内容となっております。
Fluentdは、Kubernetesのログアグリゲーションに広く使われているオープンソースのデータコレクターです。PrometheusでFluentdを監視し、トラブルシューティングを行うことは、ログ収集や監視システムに影響を与える潜在的な問題を特定するために、本当に重要なことです。
この記事では、Fluentd のドキュメントにある監視の推奨事項に従って、Prometheus を使って Fluentd の監視を開始する方法を学びます。また、Fluentd の最も一般的な問題と、そのトラブルシューティングの方法についても説明します。
Prometheusのメトリクスを公開するためのFluentdのインストールと設定方法
Fluentd のドキュメントにあるように、Fluentd はさまざまな方法でインストールすることができます。KubernetesにFluentdを導入する場合は、Helmのチャートを使って導入することをお勧めします。helm repo add fluent https://fluent.github.io/helm-charts helm repo update helm install fluentd fluent/fluentd
Fluentdがメトリクスを公開するためには、いくつかのFluentd Prometheusプラグインを有効にする必要があります。しかし、これらはHelmのチャートですでに有効になっているので、Fluentdをそのようにインストールしたのであれば、心配は要りません。
PrometheusでFluentdを監視する:入力
Incoming records
Fluentd は多くのソースからデータを収集することができます。それぞれのデータ(例えばログのエントリー)はレコードで、Fluentd はfluentd_input_status_num_records_total メトリクスを公開し、各ソースから収集したレコードの総数を数えています。以下の PromQL クエリーをダッシュボードで使用すると、すべての Fluentd インスタンスにおけるincoming recordsの割合を表示することができます。
sum(rate(fluentd_input_status_num_records_total[5m]))
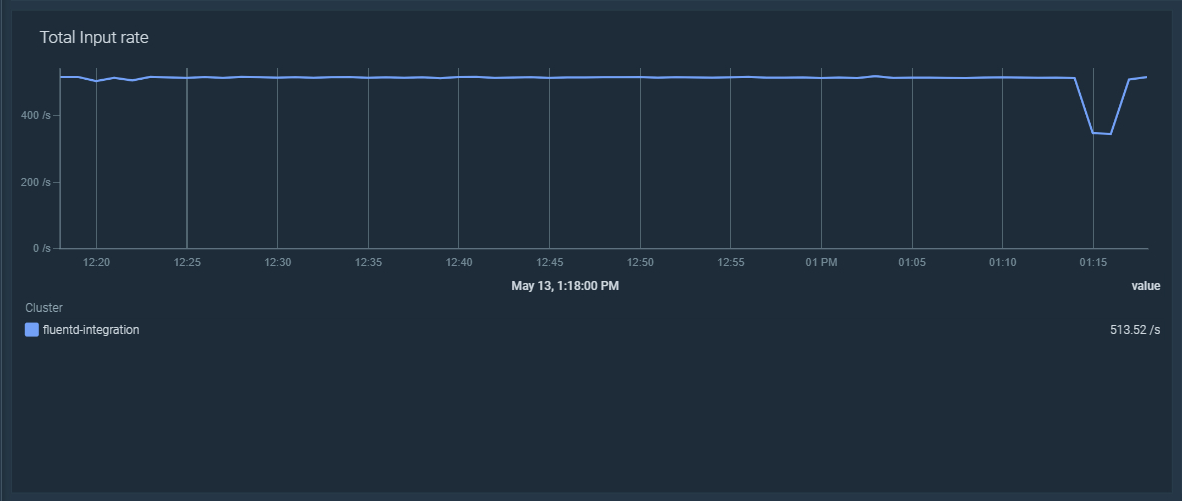
‘tag’ ラベルをリラベル化し、フィルタリングしやすくする
fluentd_input_status_num_records_total というメトリクスには、レコードのソース、通常はノード内のログファイルへのパスを含むtagと呼ばれるラベルがあります。問題は、Kubernetesでは、これらのファイル名が、ポッド名、コンテナ、ネームスペースなど、複数の文字列を連結した名前になる傾向があることです。これを活用するために、Prometheusのメトリクスリラベリングを利用する方法を見てみましょう。ここでは、FluentdがKubernetesのCoreDNSポッドからログを収集する例を紹介します:
fluentd_input_status_num_records_total{tag="kubernetes.var.log.containers.coredns-56dd667f7c-p9vbx_kube-system_coredns-72d2ba9bae8f73e32b3da0441fbd7015638117e37278d076a6f99c31b289e404.log",hostname="fluentd-lks8v"} 4.0Prometheusのジョブでは、メトリクスリラベリングを使用して、他のラベルから新しいラベルを作成することができます。この場合、ネームスペース、ポッド名、コンテナについて、正規表現を用いて新しいラベルを作成することができます:
metric_relabel_configs: - action: replace source_labels: - __name__ - tag regex: fluentd_input_status_num_records_total;kubernetes.var.log.containers.([a-zA-Z0-9 \d\.-]+)_([a-zA-Z0-9 \d\.-]+)_([a-zA-Z0-9 \d\.-]+)-[a-zA-Z0-9]+.log target_label: input_pod replacement: $1 - action: replace source_labels: - __name__ - tag regex: fluentd_input_status_num_records_total;kubernetes.var.log.containers.([a-zA-Z0-9 \d\.-]+)_([a-zA-Z0-9 \d\.-]+)_([a-zA-Z0-9 \d\.-]+)-[a-zA-Z0-9]+.log target_label: input_namespace replacement: $2 - action: replace source_labels: - __name__ - tag regex: fluentd_input_status_num_records_total;kubernetes.var.log.containers.([a-zA-Z0-9 \d\.-]+)_([a-zA-Z0-9 \d\.-]+)_([a-zA-Z0-9 \d\.-]+)-[a-zA-Z0-9]+.log target_label: input_container replacement: $3
リラベリングの魔法をかけると、先ほどのCoreDNSのFluentdのサンプルメトリクスはこのようになります:
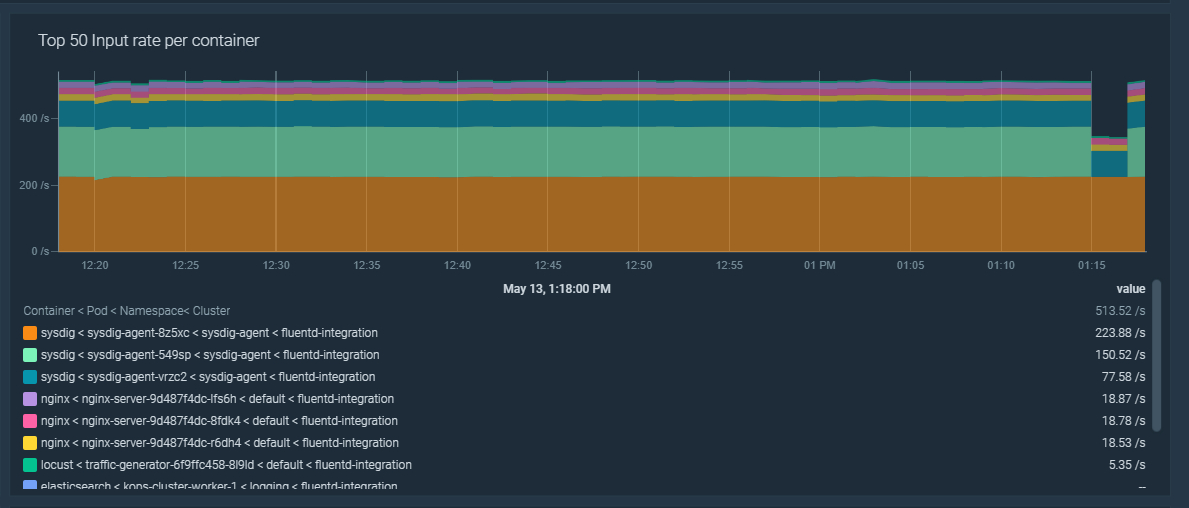
fluentd_input_status_num_records_total{input_pod="coredns-56dd667f7c-p9vbx",input_container="coredns",input_namespace="kube-system",tag="kubernetes.var.log.containers.coredns-56dd667f7c-p9vbx_kube-system_coredns-72d2ba9bae8f73e32b3da0441fbd7015638117e37278d076a6f99c31b289e404.log",hostname="fluentd-lks8v"} 4.0これらの新しいラベルを使用して、ネームスペース、ポッド、またはコンテナによってincoming recordsの割合をフィルタリングすることができます。これは、ダッシュボードを作成するときに非常に便利です。
sum by (input_namespace, input_pod, input_container)(rate(fluentd_input_status_num_records_total[5m]))
PrometheusでFluentdを監視する:出力
Outgoing records
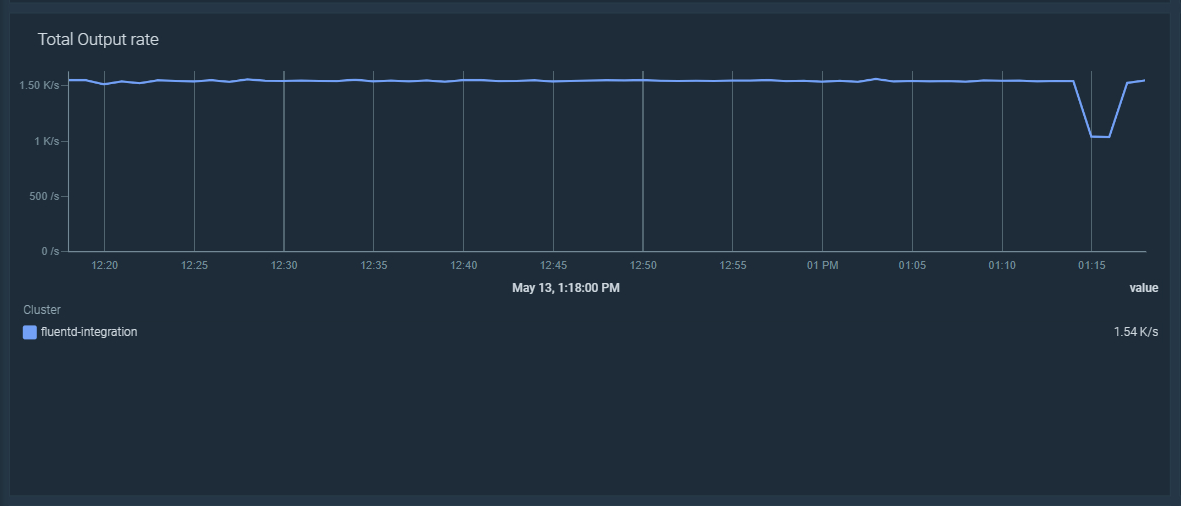
Fluentdは、複数のアウトプットプラグインタイプを使用することで、以前に収集したincoming recordsを異なる宛先に出力することができます。これはフラッシュとも呼ばれます。出力されたレコードは、fluentd_output_status_emit_records メトリクスでカウントされます。以下の PromQL クエリーをダッシュボードで使用すると、すべての Fluentd インスタンスで排出されたレコードの割合を表示することができます。
sum(rate(fluentd_output_status_emit_records[5m]))
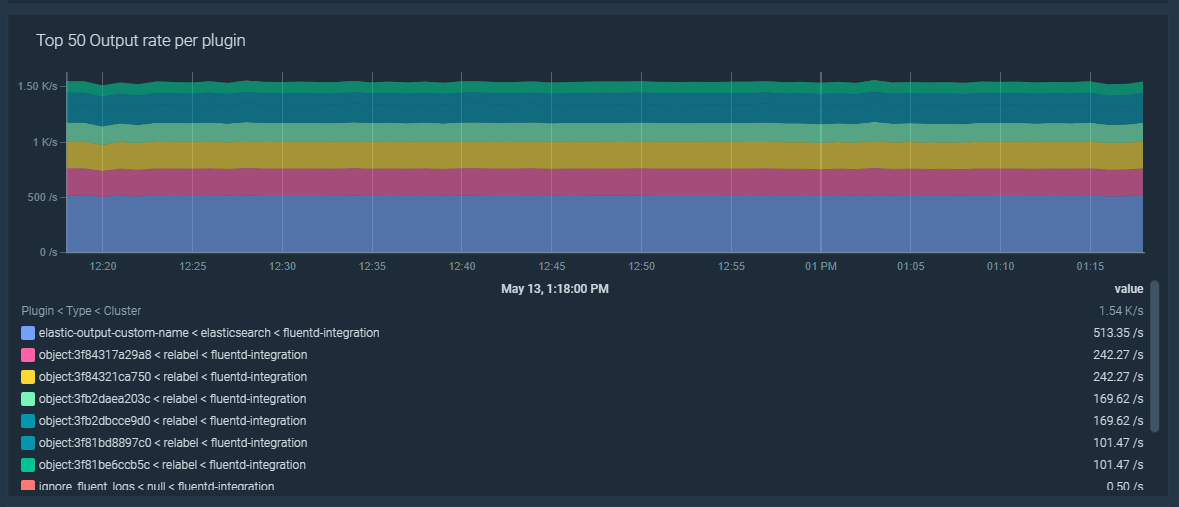
fluentd_output_ で始まるすべての Fluentd メトリクスには、以下のラベルが含まれています。- type: 出力するプラグインの種類を表します。
- plugin_id、設定にあるカスタムプラグインのID、または指定されていない場合はランダムなID。
sum by (type, plugin_id)(rate(fluentd_output_status_emit_records[5m]))
Fluentdを監視するためのトラブルシューティングの主要な場面
Fluentd のエラー、再試行、ロールバックのトラブルシューティング
Fluentd は、設定された出力先にレコードをフラッシュしようとしたときに問題に直面することがあります。これらの問題は、恒久的なものであれ一時的なものであれ、ネットワークの問題や、出力先のシステムがダウンしている場合などがあります。Fluentd のフラッシュエラーの比率が5%より高い場合に発動するアラートを作成してみましょう:
100 * sum by (type, plugin_id)(rate(fluentd_output_status_num_errors[5m])) / sum by (type, plugin_id)(rate(fluentd_output_status_emit_count[5m])) > 5
リトライやロールバックについても、同様のアラートを作成することができます。エラーに対するアラートは問題を発見するのに十分なはずですが、これらの新しいアラートは原因を特定するのに役立ちます。それらのアラートは次のようなものです。
100 * sum by (type, plugin_id)(rate(fluentd_output_status_retry_count[5m])) / sum by (type, plugin_id)(rate(fluentd_output_status_emit_count[5m])) > 5
100 * sum by (type, plugin_id)(rate(fluentd_output_status_rollback_count[5m])) / sum by (type, plugin_id)(rate(fluentd_output_status_emit_count[5m])) > 5
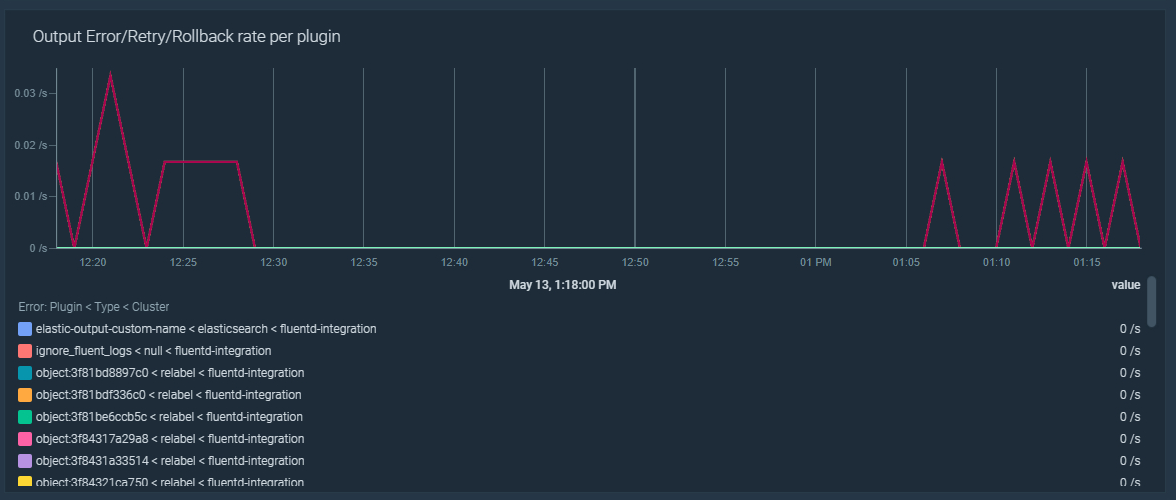
Fluentd はフラッシュに失敗すると、数秒待ってから再試行します。再試行するたびに、この待ち時間は長くなります。最大の待ち時間に達すると、Fluentd はフラッシュする必要があるデータを破棄してしまうので、データが失われてしまいます。リトライの待ち時間が60秒を超えたら発動するアラートを作ってみましょう。
sum by (type, plugin_id)(max_over_time(fluentd_output_status_retry_wait[5m])) > 60
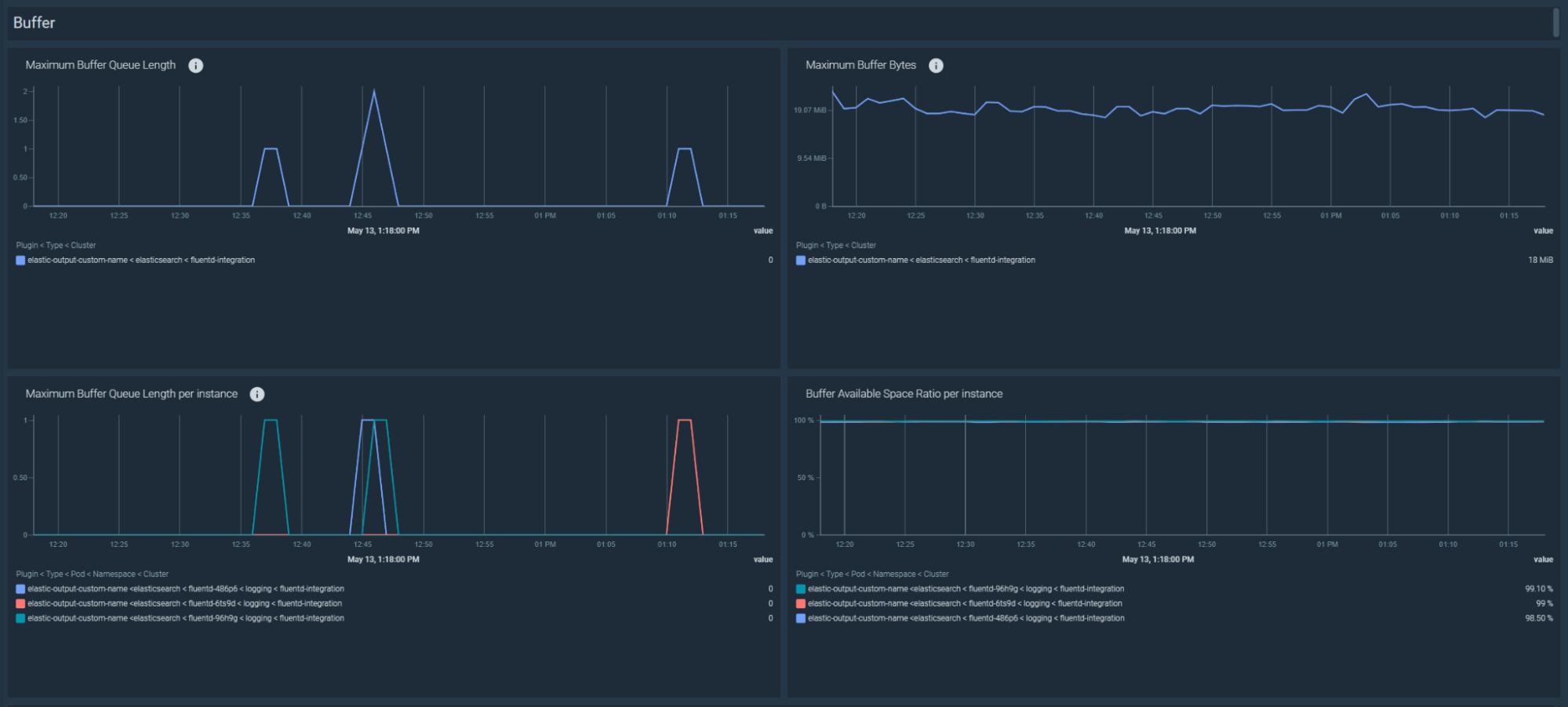
Fluentd でバッファキューがフラッシュされないトラブルシューティング
Fluentd は収集したレコードをバッファーに格納し、設定された出力先にフラッシュします。Fluentd がフラッシュに失敗すると、バッファーのサイズとキューの長さが増加します。その結果、バッファーがいっぱいになると、データを失うことになります。これらは、バッファの容量に関する推奨アラートです:
バッファの空き容量が少ない
Fluentd のバッファーの使用可能領域が 10% 未満になりました:fluentd_output_status_buffer_available_space_ratio < 10
バッファーのキューの長さが増加している
過去5分間にキューに入れられたレコードが増加しました:avg_over_time(fluentd_output_status_buffer_queue_length[5m]) - avg_over_time(fluentd_output_status_buffer_queue_length[5m] offset 5m) > 0
バッファーの総バイト数の増加
過去 5 分間にバッファーのサイズが増加しました:avg_over_time(fluentd_output_status_buffer_total_bytes[5m]) - avg_over_time(fluentd_output_status_buffer_total_bytes[5m] offset 5m) > 0
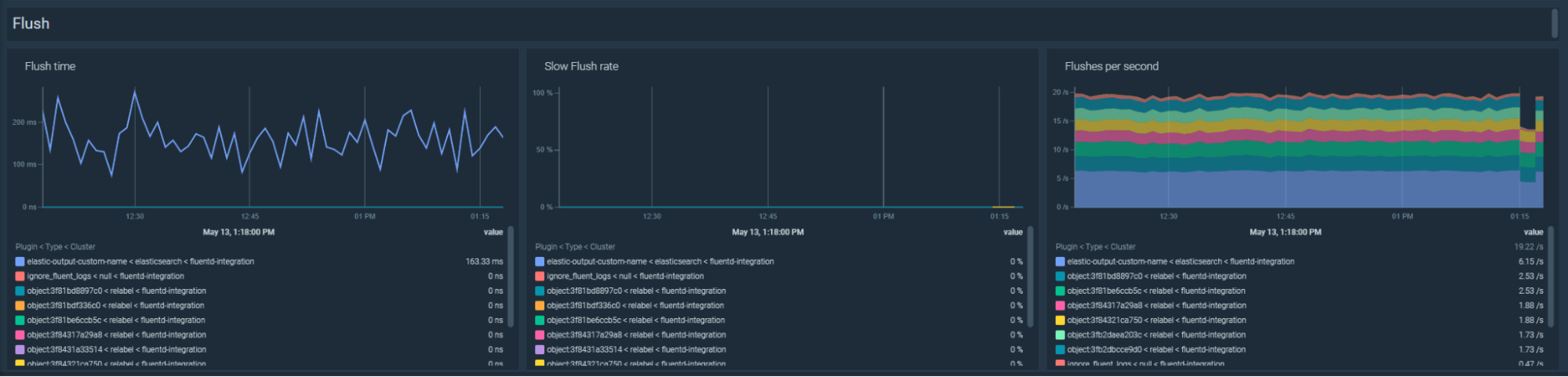
Fluentd のフラッシュが遅い場合のトラブルシューティング
Fluentdのフラッシュに時間がかかりすぎる場合、ネットワークの問題や宛先システムの問題の指標となることもあります。Fluentdのフラッシュが遅い比率が5%を超えた場合に発動するアラートを作成してみましょう:100 * sum by (type, plugin_id)(rate(fluentd_output_status_slow_flush_count[5m])) / sum by (type, plugin_id)(rate(fluentd_output_status_emit_count[5m])) > 5
ダッシュボードでは、以下のPromQLでフラッシュ時間のトラブルシューティングが可能です:
sum by(kube_cluster_name, type, plugin_id)(rate(fluentd_output_status_flush_time_count[5m]))
また、1秒あたりのフラッシュ量が増えたか減ったかは、以下のPromQLで確認することができます:
sum by(kube_cluster_name, type, plugin_id)(rate(fluentd_output_status_emit_count[5m]))
トラブルシューティング Fluentdがフラッシュを停止した
Fluentdが過去5分間にどのレコードもフラッシュしませんでした:rate(fluentd_output_status_emit_records[5m]) == 0
PrometheusでFluentdを監視するには、これらのダッシュボードを使用します
Fluentd アプリケーションを監視するためのオープンソースのダッシュボードをお見逃しなく。すでにセットアップされているので、すぐに使うことができます!以下のものがあります。
- Input/Output
- Buffer
- Flush