
本文の内容は、2022年4月14日にCarlos Arillaが投稿したブログUnderstanding Kubernetes pod pending problems(https://sysdig.com/blog/kubernetes-pod-pending-problems/)を元に日本語に翻訳・再構成した内容となっております。
Kubernetes ポッドのPendingは、成熟度が異なっても、どのクラスターにも偏在しています。
Kubernetesを使用している任意のDevOpsエンジニアに、彼らの悪夢を苦しめる最も一般的なエラーを特定するように尋ねると、PendingのPodを持つデプロイはリストのトップに近いです(おそらくCrashLoopBackOffに次ぐものです)。
アップデートをプッシュしようとして、それが止まっているのを見ると、DevOpsは不安になります。解決策がかなり簡単な場合でも、PodがPendingになっている原因を見つけ、適用すべき変更を理解することは重要です(Kubernetesのトラブルシューティングが些細なことであることはほとんどありません)。
この記事では、この問題を引き起こすさまざまな状況に光を当て、DevOpsチームが迅速に解決策を見つけ、何よりも可能な限り回避できるようにすることを目指します。
Kubernetes Pod Pendingの意味とは?
KubernetesのPodには、いくつかの異なるフェーズで構成されるライフサイクルがあります。- Podが作成されると、Pendingフェーズで開始されます。
- Podがスケジュールされ、コンテナが開始されると、PodはRunningフェーズに変更されます。
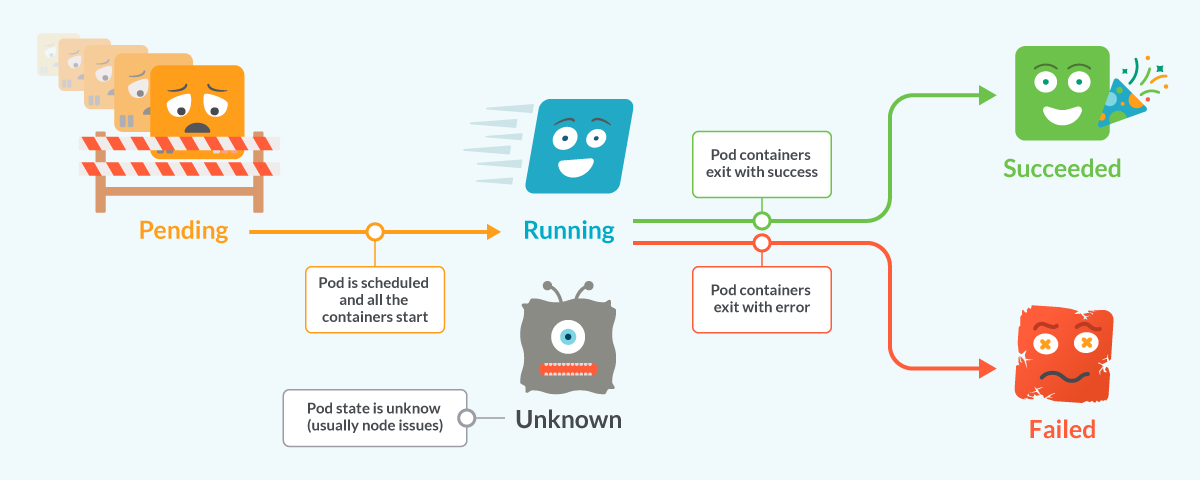 KubernetesのPodの状態、Pending、Running、Started、Failed、Unknown
KubernetesのPodの状態、Pending、Running、Started、Failed、Unknownここまでで、PodはKubernetesクラスターに受け入れられています。しかし、1つ以上のコンテナがセットアップされ、実行可能な状態にはなっていない。これには、Podがスケジュールされるのを待っている時間や、ネットワーク経由でコンテナイメージをダウンロードしている時間などが含まれます。
PodがPendingからRunningの段階に進めない場合、ライフサイクルは停止し、進行を妨げている問題が修正されるまでPodは保持されます。
kubectlでPodをリストアップすると、Kubernetes PodのPending状況を示す出力が表示されます。
$ kubectl -n troubleshooting get pods NAME READY STATUS RESTARTS AGE stress-6d6cbc8b9d-s4sbh 0/1 Pending 0 17s
Podが動かなくなり、問題を解決しない限り実行されません。
Kubernetes Pod Pendingの一般的な原因におけるトラブルシューティング
Podが実行できなくなる原因はいくつかありますが、主な3つの問題について説明します。- スケジューリングに問題がある: どのノードでもPodをスケジュールできない。
- イメージの問題:コンテナイメージのダウンロードに問題がある。
- 依存関係の問題:ポッドを実行するには、ボリューム、シークレット、またはconfig mapが必要です。
スケジューリングの問題でKubernetes PodがPendingになった場合
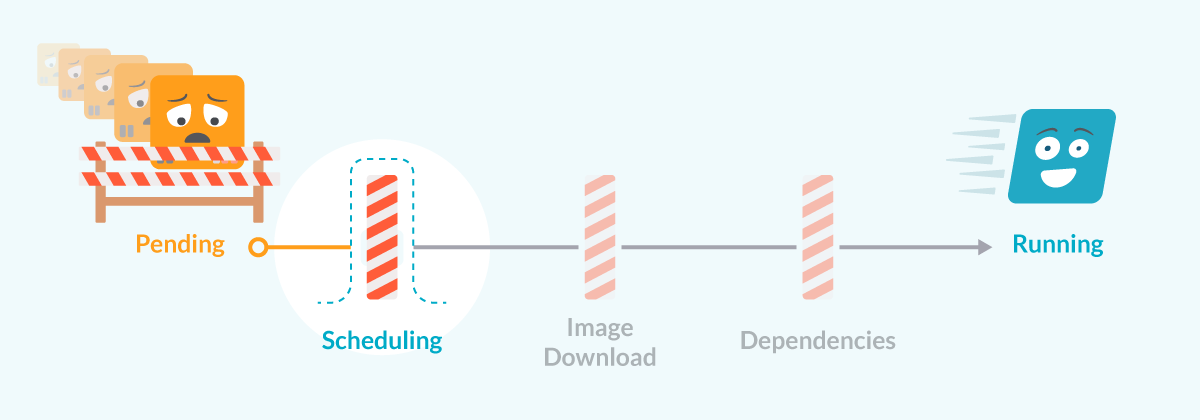 PendingからRunningへの道:スケジューリングの問題に注目
PendingからRunningへの道:スケジューリングの問題に注目Podが作成されると、Kubernetesクラスターが最初に行うことは、いずれかのノードでPodを実行するようにスケジューリングしようとすることです。このプロセスは多くの場合、実に高速で、Podはそれを実行するのに十分なリソースを持つノードに迅速に割り当てられます。
スケジュールするために、クラスターはPodの有効なリクエストを使用します(詳しくはPod evictionに関するこちらの投稿をご覧ください)。通常、Podは要求されていないリソースをより多く持つノードに割り当てられ、SLOに準拠した要求への返信に満ちた、幸せで素晴らしい人生を歩みます。
しかし、このプロセスが毎回うまくいくなら、この記事を読んでいないでしょう。クラスターがPodを割り当てられないようにする要因はいくつかあります。
最も一般的なものを確認してみましょう。
どのノードにも、Podを割り当てるのに十分なリソースがない
Kubernetesはスケジューリングのリクエストを使って、Podがノードに収まるかどうかを判断しています。リソースの実際の使用量は問題ではなく、他のPodによってすでにリクエストされたリソースのみが問題です。メモリとCPUに対するPodの有効な要求に応じるのに十分な要求可能なリソースがある場合、Podはノードにスケジューリングされます。もちろん、そのノードが実行可能なPodの最大数に達していないことが条件です。
 3つのkubernetesノードでは、すべてのリソースが要求されているため、Podをスケジュールすることはできず、Kubernetes Pod Pendingとして残ります。
3つのkubernetesノードでは、すべてのリソースが要求されているため、Podをスケジュールすることはできず、Kubernetes Pod Pendingとして残ります。Podからすべての要件を満たすノードが存在しない場合、いくつかのリソースが解放されるまでKubernetes Pod Pendingの状態で保持されます。
スケジューリング不能なノード
さまざまな問題(ノードの圧力)または人間の行動(ノードのcordoned)により、ノードはスケジュール不可能な状態に変わることがあります。これらのノードは、その状態が変化するまで、どのPodもスケジュールしません。 3つのkubernetesノード、すべてが整合性に問題があるため、Podはスケジュールできず、Kubernetes Pod Pendingのままです。
3つのkubernetesノード、すべてが整合性に問題があるため、Podはスケジュールできず、Kubernetes Pod Pendingのままです。Taintとtoleration
Taintは、異なるノードに割り当てられるPodを制限することができるKubernetesの仕組みのことです。ノードにTaintがある場合、そのノードではtolerationが一致するPodのみが実行できるようになります。この仕組みにより、ワークロードごとに異なるタイプのノード(GPU搭載ノード、CPU/メモリ比率の異なるノードなど)を用意するなど、Kubernetesの特殊な使い方ができるようになります。
 スケジュールできるのは1つのKubernetesノードだけですが、そのノードにはTaintがあり、Taintを満たすPodのみがスケジュール可能です。残りはKubernetes Pod Pendingとして残ります。
スケジュールできるのは1つのKubernetesノードだけですが、そのノードにはTaintがあり、Taintを満たすPodのみがスケジュール可能です。残りはKubernetes Pod Pendingとして残ります。すべての理由を個別に説明しても、スケジューリングの問題は、これらの問題の組み合わせで発生することが多いのです。通常、あるノードが満杯で、他のノードがTaintされているためにスケジュールできない、あるいはあるノードがメモリ圧迫のためにスケジュールできない、といったところでしょうか。
スケジューリングの問題が何であるかを調べるには、スケジューラーから生成されるPodに関するイベントを確認する必要があります。イベントには、ノードを割り当てられない理由の詳細が記述されています。イベントは、例えばkubectl describeで確認することができます。
$ kubectl -n troubleshooting describe pod stress-6d6cbc8b9d-s4sbh
Name: stress-6d6cbc8b9d-s4sbh
Namespace: troubleshooting
Priority: 0
Node: <none>
Labels: app=stress
pod-template-hash=6d6cbc8b9d
Annotations: <none>
Status: Pending
IP:
IPs: <none>
Controlled By: ReplicaSet/stress-6d6cbc8b9d
Containers:
stress:
Image: progrium/stress
Port: <none>
Host Port: <none>
Args:
--cpu
1
--vm
2
--vm-bytes
150M
Limits:
cpu: 300m
memory: 120000Mi
Requests:
cpu: 200m
memory: 100000Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-snrww (ro)
Conditions:
Type Status
PodScheduled False
Volumes:
kube-api-access-snrww:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 4m17s (x41 over 34m) default-scheduler 0/5 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 4 Insufficient memory.出力では、メッセージにある正確な理由を見ることができます:
0/5 nodes are available: 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate, 4 Insufficient memory.- 1つのノードがTaintされています。
- 4つのノードは十分な要求可能なメモリを持っていません。
- Pod specのリクエストを減らす(この記事で、リクエストのサイズを適切に設定する方法に関する非常に優れたガイドを見つけることができます。)。
- ノードを追加するか、各ノードのサイズを大きくして、クラスタの容量を増やす。
このポリシーにより、Kubernetesは、更新の進行中にワークロードが通常よりも多くのPodを作成することを許可し、新しいPodを作成する間、古いPodをしばらく維持することができます。これは、ワークロードがしばらくの間、予想以上のリソースを要求できることを意味します。クラスターに十分な予備のリソースがない場合、更新はブロックされ、プロセスがブロック解除されるまで(またはロールバックタイムアウトによって更新が停止されるまで)、一部のPodがPendingのままになります。
イメージの問題でPod pending
ノードにPodが割り当てられると、kubeletはPod specのすべてのコンテナを起動しようとします。そのために、イメージをダウンロードして実行しようとします。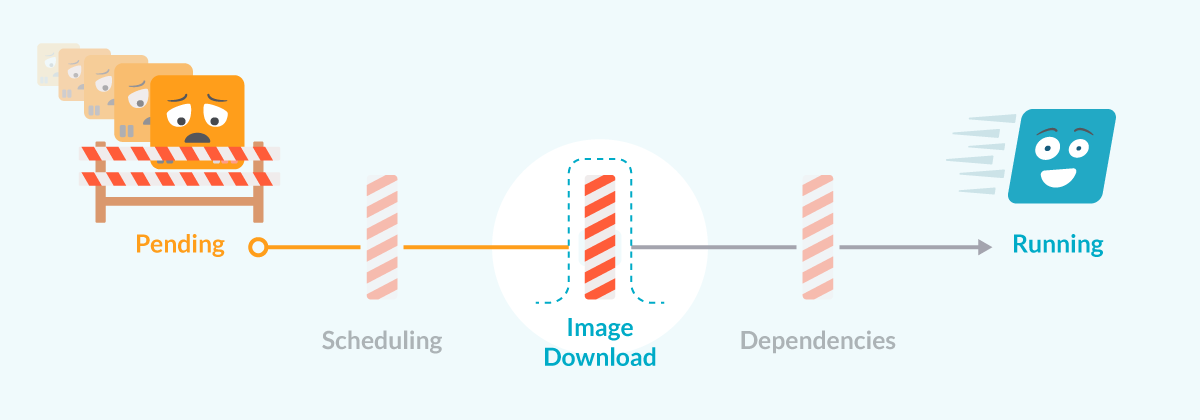 PendingからRunnningへの道:イメージダウンロードの問題に注目
PendingからRunnningへの道:イメージダウンロードの問題に注目イメージのダウンロードを妨げるエラーはいくつかあります。
- イメージの名前が間違っている。
- イメージのtagが間違っている。
- リポジトリが間違っている。
- リポジトリに認証が必要である。
この問題は通常、独立した問題として扱われるため、近日中に公開予定の別の記事でさらに説明します。
Kubernetes Podが依存関係の問題でPendingになっている
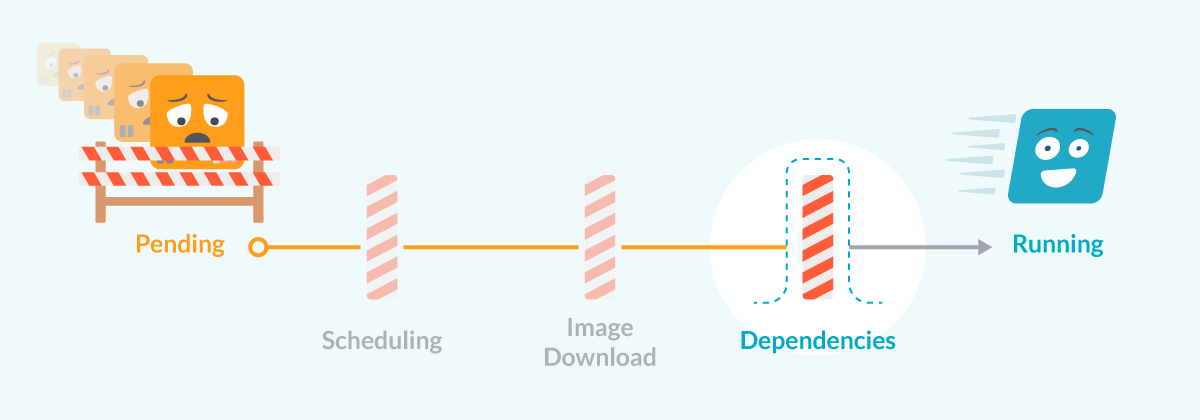 PendingからRunnningへの道:依存性の問題に注目
PendingからRunnningへの道:依存性の問題に注目Podが起動する前に、kubeletは他のKubernetes要素との依存関係をすべて確認しようとします。これらの依存関係のうち1つでも満たすことができない場合、依存関係が満たされるまでPodはpending状態になります。
 Podの依存関係の例:必要なPersisten Volumeが利用できないため、Podはpending状態のままとなります。
Podの依存関係の例:必要なPersisten Volumeが利用できないため、Podはpending状態のままとなります。この場合、kubectlではこのようにPodが表示されます:
$ kubectl -n mysql get pods NAME READY STATUS RESTARTS AGE mysql-0 0/1 ContainerCreating 0 97s
そして、イベントにおいては、次のようなものが確認できます:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 3m19s default-scheduler Successfully assigned mysql/mysql-0 to ip-172-20-38-115.eu-west-1.compute.internal Warning FailedMount 76s kubelet Unable to attach or mount volumes: unmounted volumes=[config], unattached volumes=[kube-api-access-gxjf8 data config]: timed out waiting for the condition Warning FailedMount 71s (x9 over 3m19s) kubelet MountVolume.SetUp failed for volume "config" : configmap "mysql" not found
メッセージ列には、不足している要素を特定するのに十分な情報が記載されています。通常の原因は以下の通りです。
- config mapまたはシークレットが作成されていないか、提供された名前が正しくない。
- ボリュームが他のノードからまだリリースされていないため、そのノードにマウントできない。マウントされるボリュームは古いポッドと同じでなければならないため、これは特にステートフルセットを更新する処理で発生します。
まとめ
Kubernetesでワークロードを安全にデプロイし、アップデートするためには、PodがPendingフェーズに留まる理由を理解することが重要です。問題を素早く特定し、デプロイを進行させることができれば、頭痛の種を減らし、ダウンタイムを短縮することができます。Sysdigを使用すると、この情報をすぐに利用できるため、Kubernetesのトラブルシューティングがさらに簡単になります。 今すぐ無料のSysdigMonitorトライアルに登録して、業界をリードするKubernetesモニタリング製品ですぐに詳細情報を入手してください。