

 これは、システムで監視を開始するために必要なシグナルのセットに過ぎません。言い換えれば、どのシグナルをモニターすべきか悩んだら、まずこの4つを見る必要があります。
ゴルディロックスと4つのモニタリング・シグナル…
これは、システムで監視を開始するために必要なシグナルのセットに過ぎません。言い換えれば、どのシグナルをモニターすべきか悩んだら、まずこの4つを見る必要があります。
ゴルディロックスと4つのモニタリング・シグナル…
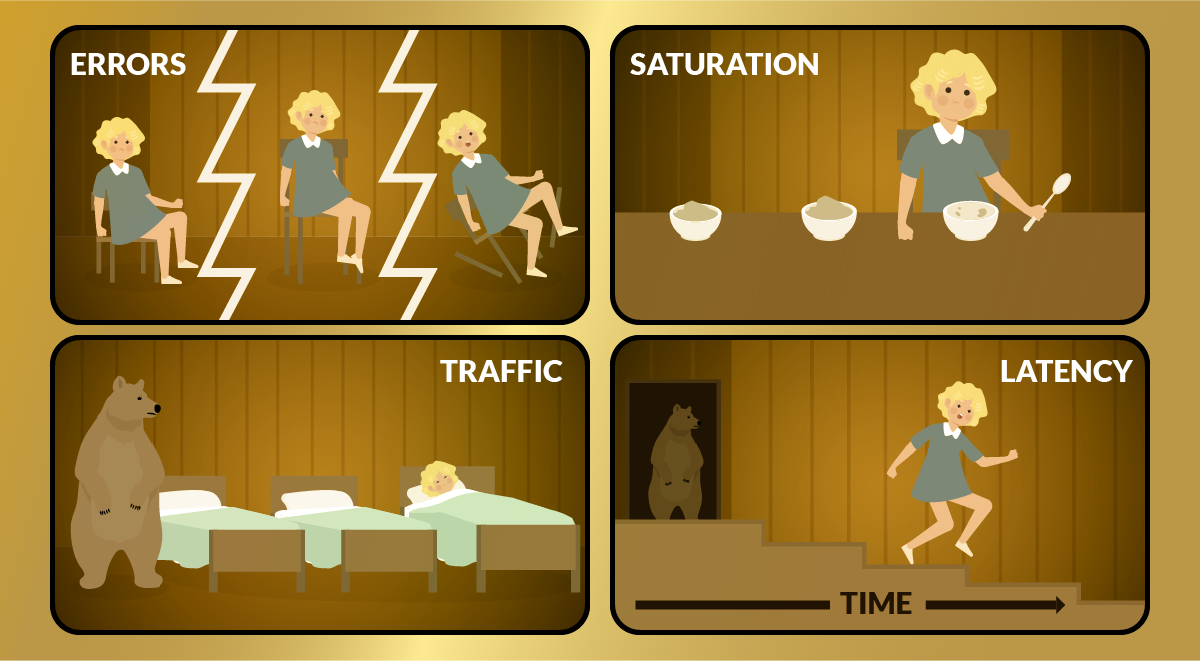
昔々、ゴルディロックスという女の子がいました。森の向こう側に住んでいて、お母さんに使いに出されて、その家の前を通りかかり、窓を覗くと…
エラー
そこでゴルディロックスは、小熊の持っていた小さな椅子を試してみたところ、ちょうどよかったのですが、強く座りすぎて、椅子を壊してしまいました。

Kubernetesにおけるエラーの測定
Kubernetesで起きているエラーの温度計の1つにKubeletがあります。PrometheusではいくつかのKubernetes State Metricsを利用して、エラーの量を計測することができます。 最も重要なのはkubelet_runtime_operations_errors_totalで、コンテナランタイムの問題など、ノードの低レベルの問題を示しています。
操作ごとのエラーを可視化したい場合は、kubelet_runtime_operations_totalを使用して分割することができます。
エラーの例
Kubelet Prometheusの指標として、Kubernetesクラスタにおけるエラー率を示します。sum(rate(kubelet_runtime_operations_errors_total{cluster="",
job="kubelet", metrics_path="/metrics"}[$__rate_interval]))
by (instance, operation_type)

サチュレーション
ゴルディロックスは、可愛らしい小さなボウルに入ったお粥を味見しました。

- CPU使用率
- ディスク容量
- メモリ使用量
- ネットワーク帯域幅
- リソースが枯渇した場合、どのような結果になるのか?リソースが枯渇した場合、どのような影響が出るのか?あるいは、システムが飽和状態にならなくなるまで、さらなるリクエストはスロットルされるかもしれません。
- サチュレーションとは、常にリソースが枯渇することを意味するわけではありません。過剰なリソース、つまり必要以上のリソースを割り当てることもあります。こちらはコスト削減のために重要です。
Kubernetesにおけるサチュレーションの測定
サチュレーションは観測するリソースに依存するため、Kubernetesのエンティティに対して異なるメトリクスを使用することができます。node_cpu_seconds_totalは、マシンのCPU使用率を測定します。container_memory_usage_bytesは、コンテナレベルのメモリ使用率を測定します(container_memory_max_usage_bytesと対になっています)。- Nodeが格納できるPodの量もKubernetesのリソースとなります。
サチュレーションの例
以下は、KubernetesノードのCPU使用率パーセントを測定する、PromQLのSaturationシグナルの例です。100 - (avg by (instance) (rate(node_cpu_seconds_total{}[5m])) * 100)

トラフィック
そして、中型のクマは言いました。”誰かが私のベッドを使ったんだ!” そして、小熊も言いました。”誰かが私のベッドを使ったんだ” “あっ、誰かがここで寝てる!”

トラフィックは、単位時間当たりのサービスの使用量を測定します。
要するに、これは現在のサービスの使用量を表すことになります。これはビジネス上の理由だけでなく、異常を検出するためにも重要です。 リクエストの量が多すぎないか?これは、ユーザーの数がピークに達しているか、設定ミスで再試行が発生していることが原因である可能性があります。 リクエストの量が少なすぎないか?これは、システムのいずれかに障害が発生していることを反映している可能性があります。 トラフィックシグナルは常に時間的な基準で測定する必要があります。例として、このブログは火曜日から木曜日にかけてより多く訪問されています。 アプリケーションによっては、次のような方法でトラフィックを測定することができます。- Web アプリケーションの場合、1 分あたりのリクエスト数
- データベースアプリケーションの場合、1分間あたりのクエリー数
- API の場合、1 分間あたりのエンドポイントリクエスト数
トラフィックの例
Google Analyticsのチャートで、時間ごとのトラフィックを表示してみました。

レイテンシー
その時、ゴルディロックスは驚いて目を覚まし、窓から飛び出して足の続く限り逃げ出し、二度と三匹のくまの小さな家に近寄らなくなりました。

レイテンシーとは、リクエストを処理するのにかかる時間のことです。
平均レイテンシー
レイテンシーを扱うとき、最初の衝動は平均レイテンシーを測定することかもしれませんが、 システムによっては、それは最良のアイデアではないかもしれません。非常に速いリクエストや非常に遅いリクエストがあり、結果を歪めている可能性があります。
代わりに、p99、p95、p50(中央値ともいう)のようなパーセンタイルを使用して、それぞれ最速の99%、95%、50%のリクエストが完了するまでにかかった時間を測定することを検討してください。
失敗と成功
遅延を測定する場合、失敗したリクエストと成功したリクエストを区別することも重要です。失敗したリクエストは正しいリクエストよりも感覚的に短い時間で済むかもしれないからです。
Apdexスコア
上記のように、レイテンシー情報は十分な情報量とは言えない場合があります。
- ユーザーが行う動作によっては、アプリケーションの動作が遅く感じられることがあります。
- ユーザーによっては、業界のデフォルトのレイテンシーに基づいて、アプリケーションが遅く感じられるかもしれません。
そこで登場するのがApdex(アプリケーションパフォーマンスインデックス)です。以下のように定義されています。
ここで、tは私たちが妥当と考える目標レイテンシーです。
- Satisfiedは、目標レイテンシー以下のリクエストを持つユーザーの量を表します。
- Tolerantは、目標レイテンシーの4倍以下のリクエストを持つ非満足ユーザーの量を表します。
- Frustratedは、許容遅延を超えるリクエストを持つユーザーの量を表します。
この式の出力は、0から1までのインデックスとなり、レイテンシーの観点から見たシステムの性能の高さを表します。
Kubernetesのレイテンシーを測定する
Kubernetesクラスタのレイテンシーを測定するには、http_request_duration_seconds_sumのようなメトリクスを使用することができます。
apiserver_request_duration_secondsのようなPrometheusのメトリクスを使用して、api-serverのレイテンシを測定することもできます。
レイテンシーの例
以下は、Prometheusで最もパフォーマンスの高い95%のHTTPリクエストに対するLatency PromQLクエリの例です。
histogram_quantile(0.95, sum(rate(prometheus_http_request_duration_seconds_bucket[5m])) by (le))

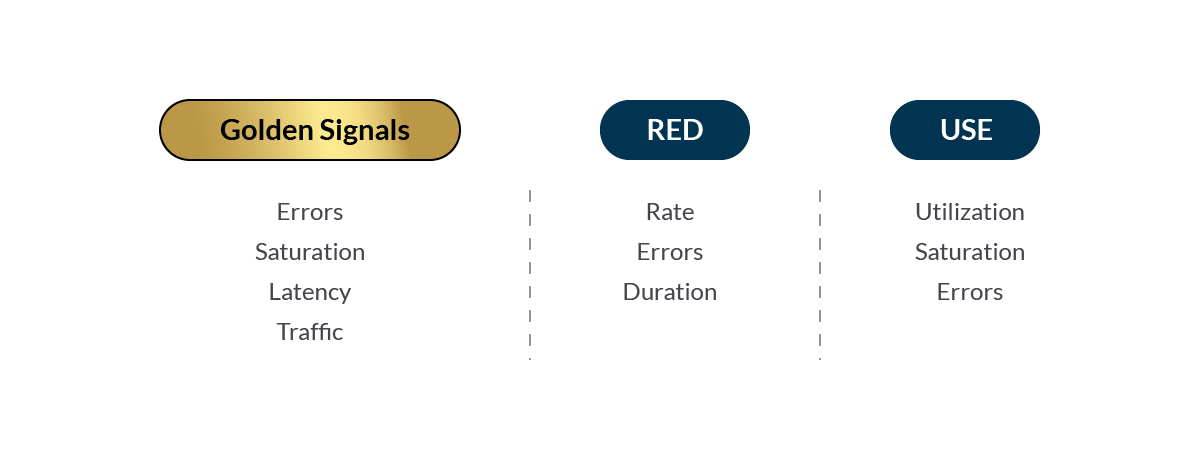
REDメソッド
REDメソッドはWeaveworksのTom Wilkie氏によって作られました。ゴールデンシグナルに大きく影響を受け、マイクロサービスアーキテクチャにフォーカスしています。
REDは、以下の略です。
- Rate:レート
- Error:エラー
- Duration:期間
Rateは、1秒あたりのリクエスト数(ゴールデンシグナルのトラフィックに相当)を測定します。
Errorは、失敗したリクエストの数を測定します(ゴールデンシグナルのエラーと同様です)。
Durationは、リクエストの処理にかかる時間を測定します(ゴールデンシグナルのレイテンシーに似ています)。
USEメソッド
USEメソッドはBrendan Gregg氏が考案したもので、インフラを測定するために使われています。
USEは、以下の略です。
- Utilization:使用率
- Satulation:サチュレーション
- Errors:エラー
つまり、システム内のすべてのリソース(CPU、ディスクなど)に対して、上記の3つの要素をチェックする必要があるのです。
Utilizationは、そのリソースの使用率として定義されます。
Satulationは、システム内の要求に対する待ち行列のことです。
Errorsは、システムで発生したエラーの数として定義されます。
直感的にはわからないかもしれませんが、ゴールデンシグナルのサチュレーションはUSEのSaturationとは似て非なるもので、Utilizationと呼ばれるものです。
Kubernetesにおけるゴールデンシグナルの実践例
ゴールデンシグナルの使い方を説明する例として、Prometheusのインスツルメンテーションを使った簡単なgoアプリケーションの例を示します。このアプリケーションでは、レイテンシーに関する有用な情報を提供するために、0秒から12秒の間でランダムな遅延を適用しています。トラフィックはcurlで生成され、いくつかの無限ループがあります。
ヒストグラムは、レイテンシーとリクエストに関連する指標を収集するために含まれています。これらのメトリクスは、レイテンシー、リクエストレート、エラーレートという最初の3つのゴールデンシグナルを得るのに役立ちます。Prometheusとnode-exporterで直接サチュレーションを得るには、ノードのCPUのパーセンテージを使用します。
File: main.go
-------------
package main
import (
"fmt"
"log"
"math/rand"
"net/http"
"time"
"github.com/gorilla/mux"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
func main() {
//Prometheus: Histogram to collect required metrics
histogram := prometheus.NewHistogramVec(prometheus.HistogramOpts{
Name: "greeting_seconds",
Help: "Time take to greet someone",
Buckets: []float64{1, 2, 5, 6, 10}, //Defining small buckets as this app should not take more than 1 sec to respond
}, []string{"code"}) //This will be partitioned by the HTTP code.
router := mux.NewRouter()
router.Handle("/sayhello/{name}", Sayhello(histogram))
router.Handle("/metrics", promhttp.Handler()) //Metrics endpoint for scrapping
router.Handle("/{anything}", Sayhello(histogram))
router.Handle("/", Sayhello(histogram))
//Registering the defined metric with Prometheus
prometheus.Register(histogram)
log.Fatal(http.ListenAndServe(":8080", router))
}
func Sayhello(histogram *prometheus.HistogramVec) http.HandlerFunc {
return func(w http.ResponseWriter, r *http.Request) {
//Monitoring how long it takes to respond
start := time.Now()
defer r.Body.Close()
code := 500
defer func() {
httpDuration := time.Since(start)
histogram.WithLabelValues(fmt.Sprintf("%d", code)).Observe(httpDuration.Seconds())
}()
if r.Method == "GET" {
vars := mux.Vars(r)
code = http.StatusOK
if _, ok := vars["anything"]; ok {
//Sleep random seconds
rand.Seed(time.Now().UnixNano())
n := rand.Intn(2) // n will be between 0 and 3
time.Sleep(time.Duration(n) * time.Second)
code = http.StatusNotFound
w.WriteHeader(code)
}
//Sleep random seconds
rand.Seed(time.Now().UnixNano())
n := rand.Intn(12) //n will be between 0 and 12
time.Sleep(time.Duration(n) * time.Second)
name := vars["name"]
greet := fmt.Sprintf("Hello %s \n", name)
w.Write([]byte(greet))
} else {
code = http.StatusBadRequest
w.WriteHeader(code)
}
}
}
このアプリケーションは、KubernetesクラスタにPrometheusとGrafanaでデプロイされ、ゴールデンシグナルでダッシュボードを生成しています。ダッシュボードのデータを取得するために、PromQLのクエリを以下に示します。
レイテンシー:
sum(greeting_seconds_sum)/sum(greeting_seconds_count) //Average histogram_quantile(0.95, sum(rate(greeting_seconds_bucket[5m])) by (le)) //Percentile p95
リクエストレート:
sum(rate(greeting_seconds_count{}[2m])) //Including errors
rate(greeting_seconds_count{code="200"}[2m]) //Only 200 OK requests
1秒あたりのエラー数:
sum(rate(greeting_seconds_count{code!="200"}[2m]))
サチュレーション:
100 - (avg by (instance) (irate(node_cpu_seconds_total{}[5m])) * 100)
すべてのゴールデンシグナルが表示されたダッシュボードがこちらです。

結論
ゴールデンシグナル、RED、USEは、システムを見るときに何を重視すべきかのガイドラインになります。しかし、これらは何を測定すべきかの最低ラインでしかありません。
システム内のエラーを理解してください。それらは異常な動作を指し示すので、他のすべての測定基準の温度計となります。そして、リクエストを正しくエラーとしてマークする必要があることを忘れないでください。ただし、例外的に不正確であるべきものだけをマークしてください。さもなければ、あなたのシステムはフォールスポジティブ(偽陽性)やフォールスネガティブ(偽陰性)になりやすいでしょう。
リクエストのレイテンシーを測定してください。ボトルネックを理解し、レイテンシーが予想以上に高い場合、どのようなネガティブな体験になるかを把握するようにします。
サチュレーションを視覚化し、ソリューションに関わるリソースを理解してください。リソースが枯渇した場合、どのような結果になるのでしょうか?
トラフィックを測定して、使用率のカーブを把握してください。アップデートのためにシステムを停止する最適なタイミングを見つけることができますし、予想外のユーザー数が発生したときにアラートを出すことも可能です。
測定基準を設定したら、これらの測定基準のいずれかが特定の閾値に達した場合に通知するアラートを設定することが重要です。
Sysdig Monitorでゴールデンシグナルを簡単に追跡
Sysdig Monitorを使えば、すぐにシステムのゴールデンシグナルを確認することができます。
クラスタ内のPodのレイテンシー、エラー、サチュレーション、トラフィックを簡単にレビューすることができます。また、eBPFによるコンテナ監視機能により、アプリやコードのインスツルメンテーションを追加することなく、このようなことが可能です。
Sysdig Advisorは、ライブログ、パフォーマンスデータ、推奨される修復ステップにより、平均解決時間(MTTR)を短縮し、Kubernetesのトラブルシューティングを支援します。

30日間、無料でお試しいただけます。