

本文の内容は、2025年6月24日にFlavio Mutti が投稿したブログ(https://sysdig.com/blog/introducing-sysdig-sage-for-search)を元に日本語に翻訳・再構成した内容となっております。
AIベースのグラフ検索アシスタントであるSysdig Sage for Searchを発表できることを嬉しく思います。これは、 Sysdig Sage for Cloud Detection and Responseのリリースに続き、SysdigのAI機能を強化するものです。サイバーセキュリティの専門家を支援するために設計されたSysdig Sage for Searchは、複雑なセキュリティデータとのやり取りとそこから得られる洞察の抽出方法を再構築します。
従来のサイバーセキュリティツールは、現代の環境の複雑さが増す中で、対応が追いつかないことがよくあります。課題は、膨大なデータを理解し、実用的な洞察をリアルタイムで提供することです。SysdigのAI検索エンジンは、まさにこの点で際立っています。
Sysdig Sage for Searchのご紹介
Sysdig Sage for Searchの中核を成すのは、最先端のAIテクノロジーと深い専門知識を組み合わせた強力な検索エンジンです。サイバーセキュリティ向けに特別に設計されたこのエンジンは、専門家が複雑なインフラストラクチャーやセキュリティデータとやり取りするプロセスを簡素化します。
Sysdig Sage for Searchを使用すると、ユーザーは自然言語でセキュリティに関する質問を表現できます。これらの質問は自動的に解釈され、グラフベースのデータストアに対する正式なSysQLクエリに変換されます。これにより、セキュリティチームはクエリ構文を記述したり理解したりすることなく、関係性、エンティティ、イベントをシームレスに探索できます。
このシステムは、高レベルの調査目標と低レベルのデータ間のギャップを埋める直感的なインターフェースをアナリストに提供し、インシデント対応、ポリシー検証、振る舞い分析などのワークフローを加速させます。
キーとなるイノベーション
SysQL: 独自のクエリ言語
Sysdigは、サイバーセキュリティ分野に特化した新しいクエリ言語、SysQLを発表しました。一般的なクエリ言語とは異なり、SysQLはユーザーフレンドリーで直感的なため、高度な専門知識を必要とせずに複雑な質問を行うことができます。
SysQLは、Kubernetesやクラウドリソース、そしてクラウドセキュリティポスチャ管理(CSPM)に関連するリスクや調査結果を調査するために特別に設計されたクエリ言語です。クラウドインフラストラクチャー、セキュリティ状況、脆弱性、コンプライアンス管理に関連するエンティティをクエリする機能を提供します。
SysQL の利点:
1.クラウドとKubernetesに特化:
SysQL は、クラウド環境と Kubernetes セットアップ内のリソースと脆弱性をクエリするようにカスタマイズされており、汎用クエリ言語を使用するよりも CSPM 関連のオペレーションが効率的になります。
2.エンティティ・リレーションシップ構造:
SysQLは、エンティティとその関係性に基づいたクエリを可能にします。これは、インフラストラクチャー内のさまざまなコンポーネントがどのように相互作用し、影響し合うかを理解するのに特に役立ちます。
3.組み込み型セキュリティ機能:
SysQL は、セキュリティの検知結果、脆弱性、構成を対象としたクエリをサポートしているため、セキュリティ分析とポスチャー管理に役立つツールとなります。
4.使いやすさ:
SysQL の言語はユーザーフレンドリーに設計されており、オペレーターは対象またはフィルタリングするデータを簡単に指定できるため、複雑なクラウド セキュリティ運用のタスクが簡素化されます。
5.包括的なクエリ操作:
他のクエリ言語と同様に、SysQL は MATCH、WHERE、RETURN、ORDER BY などのさまざまな演算子を提供し、クエリ結果のフィルタリング、並べ替え、制限を強力にサポートします。
全体として、SysQL はクラウド ネイティブおよび Kubernetes リソース クエリをセキュリティおよびコンプライアンス分析と統合し、一般的なデータベース クエリ言語と比較して、より関連性の高いコンテキスト主導の探索を可能にします。
SysQL の詳細については、こちらのドキュメントを参照してください。
ファインチューニングされたLLM
SysdigのAIエンジンは、数十万ものドメイン固有の質問で綿密に訓練された大規模言語モデル(LLM)を搭載しています。このモデルはユーザークエリをSysQLに変換し、正確で実用的な結果を実現します。
セキュリティデータへの自然言語アクセスを可能にするため、セキュリティグラフに対する構造化クエリを理解・生成するために特別に設計されたカスタムLLMをファインチューニングしました。このモデルは単に文章を解析するだけでなく、クラウドとコンテナのセキュリティという文脈でユーザーの意図を解釈し、正確で意味的に豊かなクエリを生成して検索エンジンを強化します。LLMは、約34,000件のSysQLクエリと135,000件の自然言語による質問を含むデータセットで学習されています。
実際の例でモデルをトレーニングし、継続的な評価を通じて改良することで、最新のクラウド環境で実践者がリスクと露出を調査する方法と一致していることを実現します。
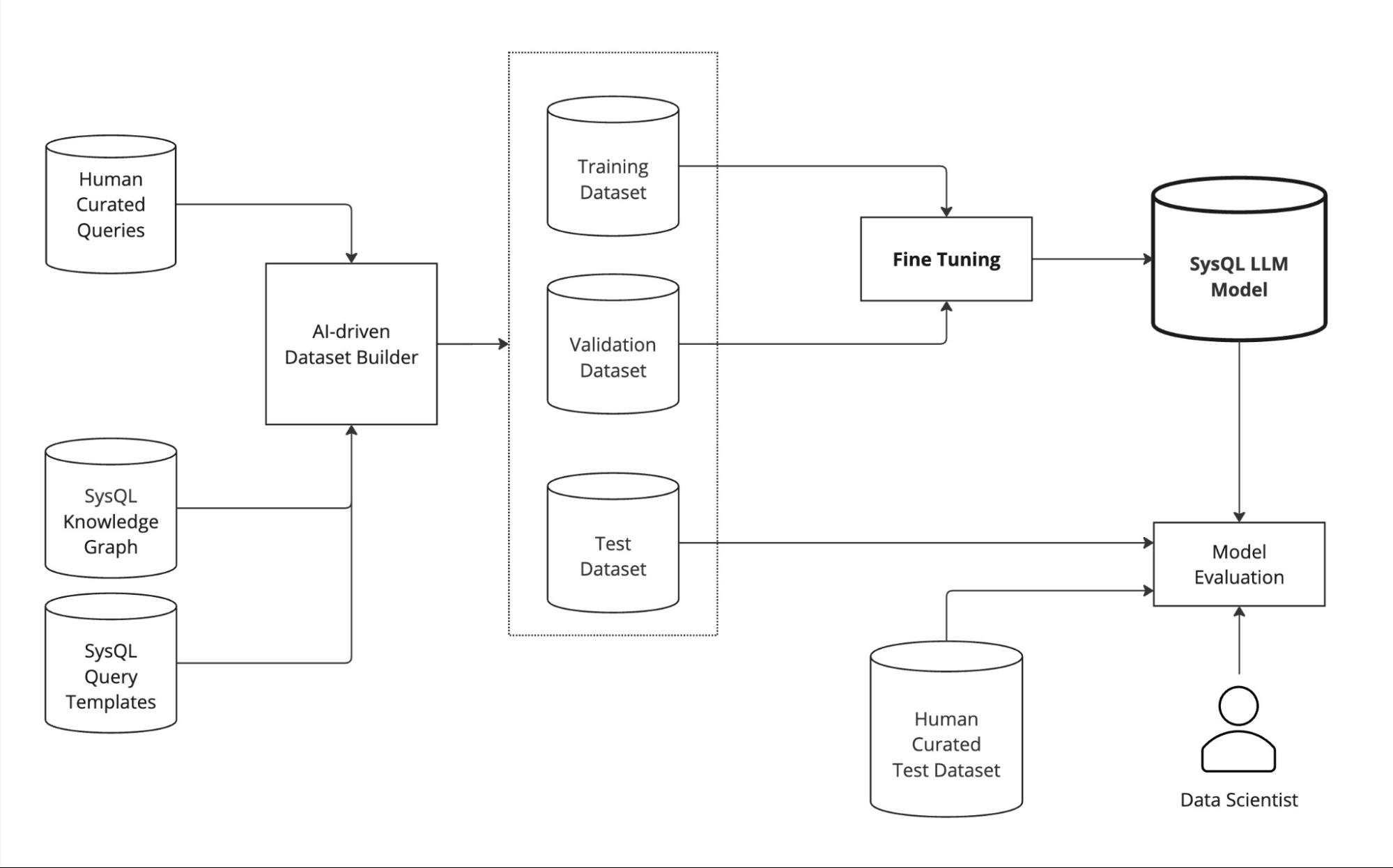
モデルの作成とトレーニングのプロセスには以下が含まれます。
- AI駆動型データセット生成:データセットは、AI駆動型ビルダーを用いて生成されます。このビルダーは、人間がキュレーションしたクエリ、SysQLクエリテンプレート、SysQLナレッジグラフを組み合わせ、現実的なテキストとSysQLクエリのペアを生成します。このプロセスにより、トレーニングセット、検証セット、テストセットに分割された大規模で多様なデータセットが作成され、モデルが実際のユーザーがセキュリティデータとどのようにやり取りするかを学習できるようになります。
- ファインチューニング:生成されたトレーニングデータセットと検証データセットを用いて、ドメイン固有の大規模言語モデルをファインチューニングします。約13万5千件の自然言語質問と3万4千件のSysQLクエリを用いて、モデルはユーザーの意図をSysQLナレッジグラフの構造とセマンティクスに適合した正確で実行可能なクエリに変換することを学習します。
- モデル評価:ファインチューニングされたモデルは、AI生成と人間がキュレーションしたテストデータセットの両方で評価され、品質、精度、そして実際のユースケースとの整合性が確保されます。データサイエンティストがモデルの出力をレビューし、継続的にパフォーマンスを改善し、クラウドおよびコンテナセキュリティ専門家の実用的なニーズを満たしていることを確認します。
主な利点:
- ドメイン特化:モデルをセキュリティ固有のクエリ言語で構築することにより、汎用モデルよりもはるかに優れた精度と関連性を確保できます。
- 高品質のトレーニング データ:人間の専門知識とテンプレートベースの生成を組み合わせることで、データセットを拡張しながら精度を確保します。
- テスト時の制御:厳選された「ゴールデン データセット」での評価により、反復全体にわたって一貫したパフォーマンスの追跡が可能になります。
- 説明可能性: SysQL の構造化された形式により、生成されたクエリの検査、デバッグ、検証が容易になります。これは、セキュリティ アプリケーションにおいて重要な機能です。
- スケーラビリティ:テンプレートおよびパターンベースのクエリ生成により、新しいスキーマやデータ モデルへの迅速な適応が可能になります。
これが重要な理由:
- より迅速な調査:アナリストはクエリ言語を学習することなく、迅速に洞察を得ることができます。
- セキュリティを考慮した結果:このモデルは、クラウド ネイティブの脅威と関係性を理解するために特別に構築されています。
- 構造による信頼:出力は説明可能かつ検査可能であり、リスクの高いセキュリティ ワークフローでは重要です。
- 進化するように構築:クラウドの脅威が変化すると、モデルが適応し、AI エンジンの回復力と将来性が向上します。
革新的な推論パイプライン
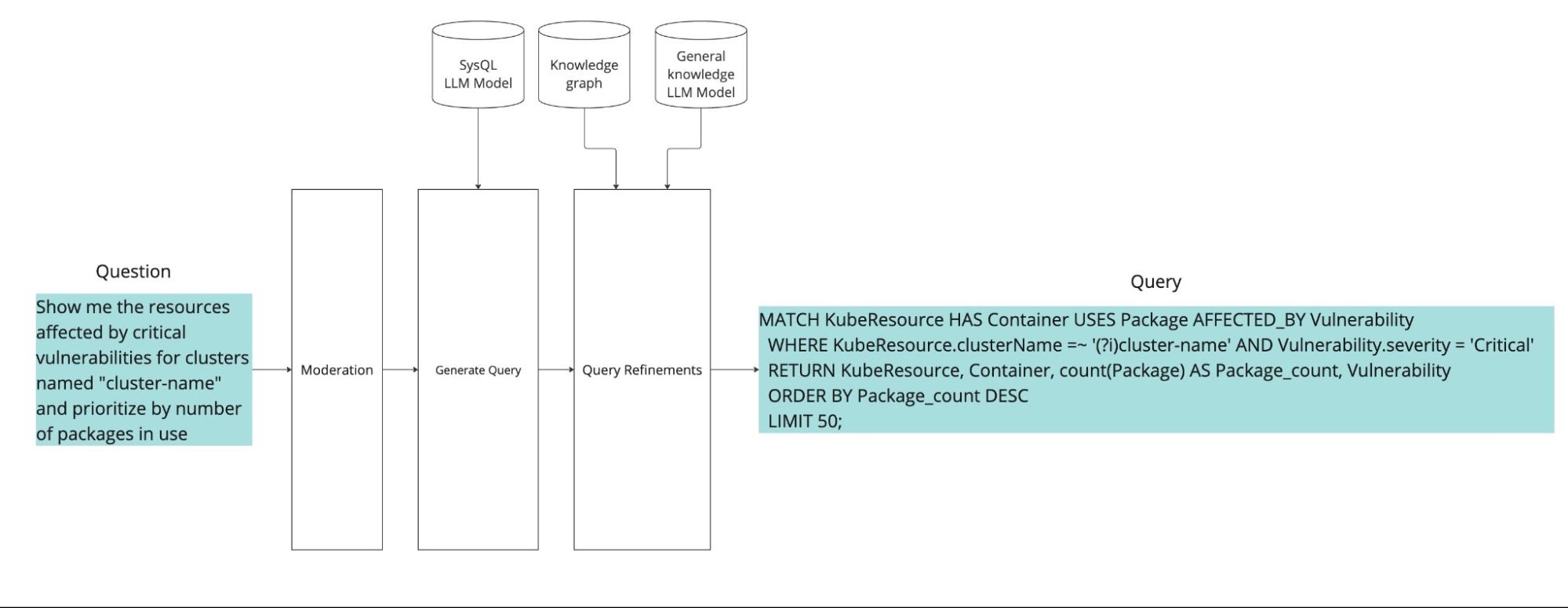
Sysdigの推論パイプラインは、カスタムLLMのパワーとサイバーセキュリティナレッジグラフを組み合わせます。この独自のアプローチにより、エンジンは複雑なユーザーリクエストに対応し、表面的な分析を超えた洞察を提供します。
一度トレーニングされたカスタムLLMは、自然言語を実行可能なセキュリティグラフクエリへと変換するリアルタイム推論パイプラインの中核となります。たとえばユーザーが「“cluster-name”という名前のクラスタに対して重大な脆弱性の影響を受けているリソースを表示し、使用中のパッケージ数で優先順位を付けてください」と尋ねると、システムはまず入力をモデレーションし、その後クエリジェネレーターに渡して意図を解釈し、有効なSysQLクエリを組み立てます。
私たちは、自然言語の質問を正式なSysQLクエリに変換するための堅牢なマルチステージ推論パイプラインを導入しました。このシステムは、曖昧さ、構文エラー、サポートされていないクエリパターンを処理するために、LLMによる生成、プログラムによるフィードバックループ、およびセマンティックな後処理を組み合わせて設計されています。
パイプラインの概要
- モデレーションとフィルタリング。生成されたクエリはモデレーションされ、以下の項目がフィルタリングされます。
- 現在のアプリケーションの範囲に関係のない、文脈外の質問。
- システムまたはスキーマの制限により、コンテキスト内だがサポートされていないクエリ。
- 初期クエリ生成。自然言語の質問がLLMに渡され、候補となるSysQLクエリが生成されます。
- 構文検証と修正ループ。クエリはSysQLインタープリタに送信されます。構文検証に失敗した場合:
- インタープリターのエラー メッセージと関連するスキーマ レベルの情報 (エンティティ、リレーションシップ) が LLM のプロンプトに再度挿入されます。
- LLM は、この強化されたコンテキストを使用して、クエリの修正バージョンを再生成しようとします。
- セマンティック後処理。構文的に有効なクエリが生成されると、セマンティック列挙の問題(列名のあいまいさなど)がAI駆動型の技術を使用して修正されます。
- 反復試行。ステップ2~6を最大K回繰り返して、複数の候補クエリを生成します。
- システムは相関する提案(言い換えやスキーマのヒントなど)を生成します。
- これらは、クエリ生成の次のラウンドのために、微調整された LLM を再度要求するために使用されます。
- クエリの絞り込み。最後の絞り込みステップでは、K 個の候補から上位 1 つのクエリを選択し、入力された質問とスキーマのコンテキストとの最適な整合性が得られるように最適化します。
推論パイプラインの主な利点
- 不完全な入力にも対応:階層化された修正メカニズムにより、不完全または不正確な質問から復元します。
- 正確なクエリ生成:生成されたクエリを検証および調整して、実行可能かつ関連性があることを確認します。
- ドメイン認識解釈:クラウド セキュリティ コンテキストを活用して、エンティティ、リレーションシップ、フィールドを正しく解決します。
- 反復的な改良:構造化されたフォールバックを適用して、ユーザーの介入なしに成功率を最大化します。
- シームレスな統合:バックエンドの検索エンジンに直接接続し、最小限の遅延で結果を提供します。
- 説明可能性:透明性があり検査可能なクエリを生成し、自動化された結果に対する信頼を実現します。
なぜこれが重要なのか
- 堅牢性:システムは、あいまいさや部分的に形成された入力を適切に処理できます。
- 大規模な精度:複数の検証および修正ステップにより、クエリの正確性と意味の一貫性を確保します。
- 適応性:新しいセキュリティ概念やクエリ パターンが出現するにつれて、パイプラインは時間の経過とともに改善されます。
- 低摩擦:ユーザーは質問を書き直す必要がなく、高品質の結果を得ることができます。
シームレスな統合
AI搭載の検索エンジンはSysdigのプラットフォーム、特にアシスタントチャットの体験に深く統合されています。この統合により、複雑なクラウドおよびKubernetesのデータが分かりやすい会話型インサイトに変換され、ユーザーの負担を軽減し、迅速なアクションを支援します。
重要な場所に埋め込まれる
Sysdig の検索 UI を操作する場合でも、アシスタント チャットとやり取りする場合でも、AI エンジンは常に次のことを行います。
- 自然言語の質問を理解する
- 正確なSysQLクエリに変換する
- 環境から直接、整理され構造化された回答を返します
この緊密な統合により、セキュリティ チームはクエリ言語を学習したり、複数のダッシュボードを調べたりすることなく、インフラストラクチャとリスク状況を調査できるようになります。
なぜこれが重要なのか
この統合により、生のクラウドデータと、それに基づいて行動を起こす必要がある人々との間のギャップが埋められます。検索可能、説明可能、そして実用的なインサイトを提供することで、チームのアプローチを変革します。
- クラウドとKubernetesのリソース検査
- 脆弱性のトリアージと修復
- セキュリティポスチャーの監視
- インベントリーと資産の可視性
AIアシスタントができること
アシスタントは静的なチャットボットではなく、次の機能を備えたドメイン対応のセキュリティ検索インターフェースです。
- AWS、GCP、Azure 全体のクラウドおよび Kubernetes リソースを分析
- 失敗したコントロール、リスキーな構成、公開された資産などのセキュリティに関する洞察を明らかにする
- SysQLクエリの実行と説明
- リソースタイプ、アカウント、リージョン別にインフラストラクチャーインベントリをまとめる
- フォローアップの提案と文脈理解を通じて調査を導く
つまり、セキュリティと運用に関する質問を、コンテキストと精度を備え、手作業による調査なしでアクションに変換します。
実際の使用例
シナリオ
アレックスは中規模企業で働くクラウドセキュリティアナリスト。月曜日の朝、彼女は毎週の脆弱性ステータスを確認しています。
アレックスは慣れ親しんだ検索バーにこう入力します:
「修正可能な使用中の脆弱性のうち、30日以上放置されているものを表示して」
すぐに、所定の期間内に修正されなかった既知の脆弱性一覧が表示されます。赤信号です。中でも、CVE-2025-22871 が目に留まります。
ツールを切り替えたり、ドキュメントを探したりすることなく、アレックスはSysdig Sageチャットにアクセスしてこう尋ねます:
「CVE-2025-22871 の影響を受けているワークロードは?」
アシスタントは影響を受けているワークロードの内訳を即座に返します。アレックスは提示されたリンクをクリックして詳細を確認。複雑なクエリを書く必要も、ダッシュボードを掘る必要もありません。
さらにこう尋ねます:
「coredns ワークロードについて詳しく教えて」
アシスタントは、使用中のバージョン、最近の変更、リスクの露出状況、デプロイのタイムラインなど、関連情報を引き出してくれます。
次に、より深く掘り下げます:
「このクエリの意味を説明してくれる?」
アシスタントはSysQLクエリを単に表示するのではなく、結果がどのように導き出されたかをステップバイステップで説明してくれます。これによりアレックスのデータへの信頼が高まります。
最後に彼女は尋ねます:
「このCVE、修正すべき?」
アシスタントは、悪用可能性、露出時間、修正パッチの有無などに基づいてリスクを評価し、明確な推奨を提示します。「はい。このCVEは実際に悪用されており、パッチも利用可能です。修正を遅らせるとリスクが高まる可能性があります。」
結果と価値
この短いやりとりの終わりまでに、アレックスは次のことを理解しました。
- 重大な脆弱性を特定
- ワークロード全体への影響を理解した
- クエリの技術的な詳細を解釈した
- 優先的な行動勧告を受けた
これらすべては、基礎となるクエリ言語を知らなくても実現されています。
競争相手を上回る
SysdigのAIを活用したグラフ検索を、クラウドおよびKubernetesセキュリティ分野における主要な競合ソリューション(CSPM/KSPM/VM/Inventory)と比較評価しました。どちらのシステムも、自然言語で表現されたユーザーの意図を、セキュリティグラフ上で構造化された実行可能なクエリに変換することを目的としています。
競合システムは、強力なエンジニアリングとドメインモデリングを明確に示しています。構文的に有効なクエリを生成し、多くの場合、ユーザーの意図の大部分を捉えています。しかし、当社の分析では、 Sysdig Sageは、セマンティック理解、エンティティモデリング、クエリ構築における重要な違いにより、根本的に正確で運用効率の高いソリューションを提供していることが示されています。
運用実態に合わせたエンティティモデリング
Sysdig Sage による検索は、ユーザーの質問に基づいて、常に正しいプライマリエンティティを識別し、モデル化します。例えば、「重大な脆弱性の影響を受けるワークロード」に関する質問の場合、Sysdig Sage はワークロードをメインの結果として返し、関連する脆弱性データを添付します。競合システムは、関連する概念(脆弱性、調査結果など)を認識できることが多いものの、調査結果やコンテナイメージなど、誤ったオブジェクトにクエリを向けてしまう傾向があり、意図と出力の不一致につながります。これは、私たちの独断的な概念モデリングに依存している可能性があると考えられます。
正確なグラフトラバーサルとコンテキストフィルタリング
Sysdig Sageによる検索は、ワークロードからコンテナ、イメージ、脆弱性に至るまで、実際の実行時における関係性に沿った正確なグラフトラバーサルパスを構築します。また、エクスポージャー、リージョン、修正の可用性、使用状況といったフィールドに基づくコンテキストフィルタリングもサポートしています。
対照的に、競合システムでは、意味的に曖昧な、あるいは不要な中間ステップがしばしば導入されます。これらのクエリは構文的には正しいものの、必ずしも実際のデプロイメントセマンティクス(レジストリ内のイメージと本番環境で実行されているコンテナの区別など)を反映しているわけではありません。
集計、並べ替え、制限機能が組み込まれています
セキュリティ調査では、リソースの一覧表示以上の情報が必要になることがよくあります。ユーザーは、集約されたサマリー、リスクの優先順位付け、またはスコープ指定されたサブセット(例:「上位5」、「地域別グループ化」など)を求めることがよくあります。Sysdig Sageは、これらの構成要素を最初のクエリで直接サポートします。
比較すると、競合システムでは GROUP BY、ORDER BY、または LIMIT ロジックが省略されることが多く、結果を使用可能にするには手動での編集や後処理が必要になります。
入力と出力のより良い整合
Sysdig Sageによる検索の主な強みの一つは、「意味の対称性(semantic symmetry)」を維持する点にあります。すなわち、出力される情報の構造と内容が、ユーザーの質問の意図と正確に一致するのです。ユーザーが特定のCVE、ワークロード、クラスタ、脆弱なイメージについて尋ねた場合でも、Sysdig Sageはクエリとその結果が常にその中心的な概念に即したものとなるようにします。
複数のテストケースにおいて、競合システムは期待される形式から逸脱した結果を返す傾向が見られました。たとえば、影響を受けたリソースを尋ねたにもかかわらず脆弱性IDのみを返したり、クラスタ名やネームスペース名といった重要な属性を欠落させたりするケースが確認されています。
一貫性と実行可能性
Sysdig Sageで生成されたクエリはすべてテスト済みで、即座に実行可能であり、有効で意味のある結果を返しました。これは重要な差別化要因を示しています。Sysdig Sageは正しい構文を生成するだけでなく、運用上正確なセマンティクスも生成するため、実際のセキュリティに関する質問に対して信頼性の高い回答を確実に提供します。
調査結果の要約
| 側面 | Sysdig Sage | 競合システム |
| 主なエンティティの焦点 | 正しくモデル化されている(例:ワークロード、リソース) | 時々ずれる |
| グラフトラバーサルセマンティクス | 正確かつ最小限 | 冗長または不正確な感じ |
| 集約とグループ化 | 完全にサポートされています | 欠落していることが多い、または編集が必要 |
| ソートとトップNクエリ | サポートされ正確 | 頻繁に行方不明 |
| 結果の形状 | ユーザーの意図に合致する | 部分的またはずれている |
| 手動での改良が必要 | めったに | 頻繁に |
最後に
競合システムの優れた機能には敬意を表します。このシステムは、セキュリティ分野における自然言語クエリの確固たる基準を確立し、この分野を前進させました。彼らの取り組みは、自然言語と構造化されたセキュリティインサイトの間のギャップを埋めることに大きく貢献しました。
そうは言っても、Sysdig Sage は根本的に優れたソリューションを提供すると考えています。つまり、ユーザーの意図をより正確に理解し、その意図を実行可能なグラフクエリに変換し、手動による修正や改良を必要とせずに、すぐに役立つ、スコープが設定された、実用的な結果を提供するソリューションです。
Sysdig Sageでクラウドの脅威に対抗
SysdigのAIベースの検索エンジンは、単なるツールではありません。サイバーセキュリティ業界に革命をもたらす存在です。最先端のAIと深い専門知識を組み合わせることで、Sysdigは専門家が脅威に先手を打って、よりスマートな意思決定を下せるよう支援します。Sysdig Sageでサイバーセキュリティ検索の未来を体感してください。ぜひ個別のデモをご依頼ください。