

本文の内容は、2025年8月22日に Alessandro Brucato が投稿したブログ(https://sysdig.com/blog/build-your-aws-incident-response-playbook-with-open-source-tools/)を元に日本語に翻訳・再構成した内容となっております。
イントロダクション
クラウドにおけるセキュリティ侵害は頻繁に発生しており、積極的な計画が不可欠です。しかし、あらゆる脅威を防ぐことはできません。
強力な予防的セキュリティ体制があればインシデントを免れると考える人も多いですが、実際にインシデントが発生すると不意を突かれることになります。むしろ侵害は避けられないという前提で行動し、それに備える方が賢明です。クラウド攻撃がより迅速かつ巧妙化し、脅威の状況が予測不可能になる中で、セキュリティリーダーは先手を打つために「侵害前提」の考え方を受け入れなければなりません。
AWS環境におけるインシデント対応は、クラウドベースのアプリケーションやインフラのセキュリティ、可用性、全体的な健全性を維持するために極めて重要です。クラウドインフラという動的な世界では、セキュリティインシデントからの復旧や、それを引き起こした脅威アクターの追跡には、明確に定義され、繰り返し訓練されたインシデント対応計画が必要となります。堅牢なインシデント対応能力がなければ、組織は深刻な金銭的損失、評判の失墜、法的影響、そして機密データの漏洩といったリスクにさらされます。
幸いなことに、インシデント対応を支援できるオープンソースツールは数多く存在します。本記事では、それらをどのように活用できるかを示し、さらに皆さんの取り組みを支援するために新たに公開されたMCPサーバーを紹介します。
AWS 責任共有モデル
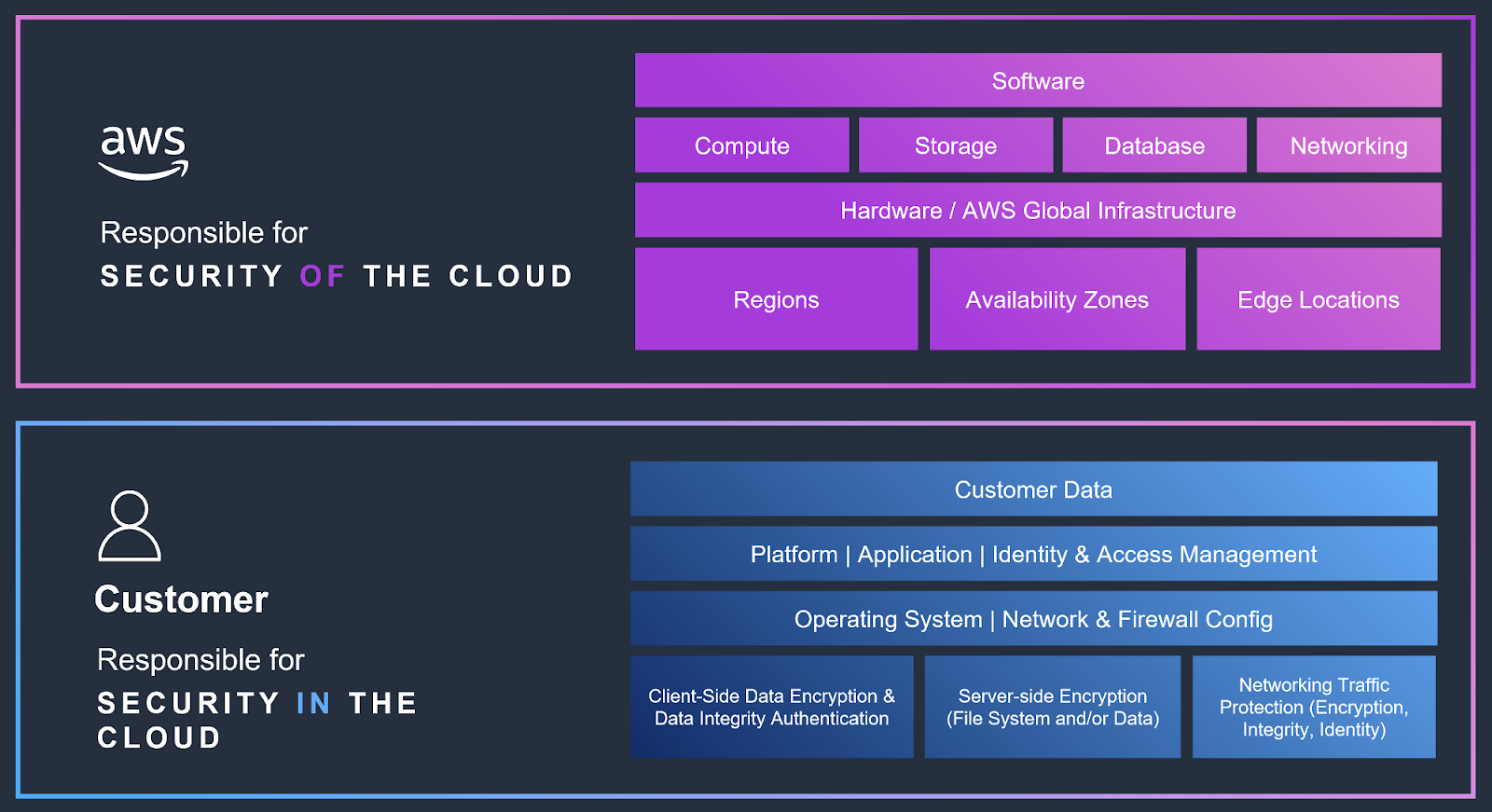
AWS環境におけるインシデント対応の基盤となるのが、責任共有モデルです。AWSとお客様の間のセキュリティ責任分担を明確に定義し、インシデントへの対応と管理方法に影響を与えます。AWSは、インフラストラクチャーと基盤サービスを含むクラウド自体のセキュリティに責任を負います。お客様は、データ、アプリケーション、オペレーティングシステム、ネットワークトラフィックを含むクラウド内のセキュリティに責任を負います。
インシデント対応において、この区別は、侵害の様々な側面について、調査と修復の責任をどちらが負うかを明確にします。AWSはインフラストラクチャーの脆弱性やサービス中断に関連する問題に対処し、お客様はデータの侵害、設定ミス、アプリケーションの脆弱性といった欠陥に対処する必要があります。このモデルにより、インシデント対応における透明性と協力体制が確保され、AWSとお客様はそれぞれ異なる役割を担いながらも補完し合いながら、環境全体のセキュリティを確保します。
AWS organizationの構造
ユーザーは、セキュリティ用の organization ユニット (OU) を 1 つとフォレンジック用の organization ユニット (OU) を 1 つ含む AWS アカウントの組織構造を設定することをお勧めします。
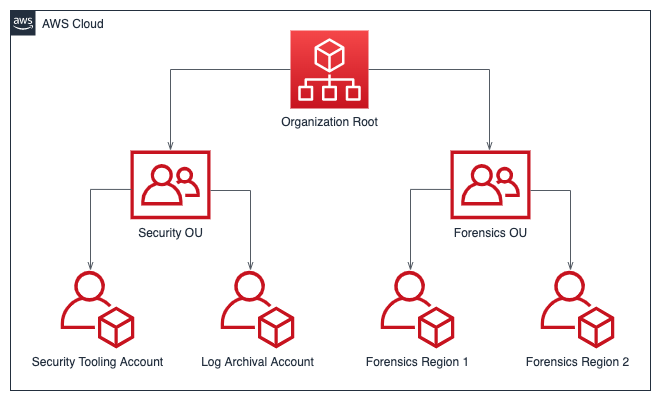
AWS organization 内でセキュリティとフォレンジックに別々の OU を持つことで、インシデント対応にいくつかの利点が生まれます。
- 職務の分離: セキュリティ OU はプロアクティブなセキュリティ対策とツールに集中し、フォレンジック OU はリアクティブ調査と分析に集中できます。
- アクセス制御:各OUに異なる権限セットを適用することで、機密性の高いフォレンジックツールやデータへのアクセスを制限できます。これにより、フォレンジック証拠の整合性を維持できます。
- リソースの分離: フォレンジック活動を別の環境で実行できるため、生産システムが汚染されるリスクが軽減されます。
- 機密性: この組織モデルは、調査の機密性を維持するのに役立ちます。
- コスト追跡: 個別の OU により、セキュリティオペレーションとフォレンジック活動に関連するコストの追跡と割り当てが容易になります。
- スケーラビリティ: フォレンジック OU は、他のセキュリティ リソースに影響を与えることなく、調査のニーズに基づいて個別に拡張できます。
- 監査証跡: フォレンジック OU で実行されたアクションは、通常のセキュリティ操作とは別に、より簡単に追跡および監査できます。
- 影響範囲の縮小: 1 つの OU でセキュリティ侵害が発生した場合でも、他の OU への影響を最小限に抑えることができます。
- サービス クォータの枯渇を回避: 脅威アクターがサービスのクォータ制限に達した場合、OU を分離することで、調査を実行するためのリソース (EC2 インスタンスなど) の作成が妨げられることはありません。
インシデント対応フェーズとAWSサービス
包括的な AWS インシデント対応計画には、以下に示すように複数のフェーズが含まれる必要があります。
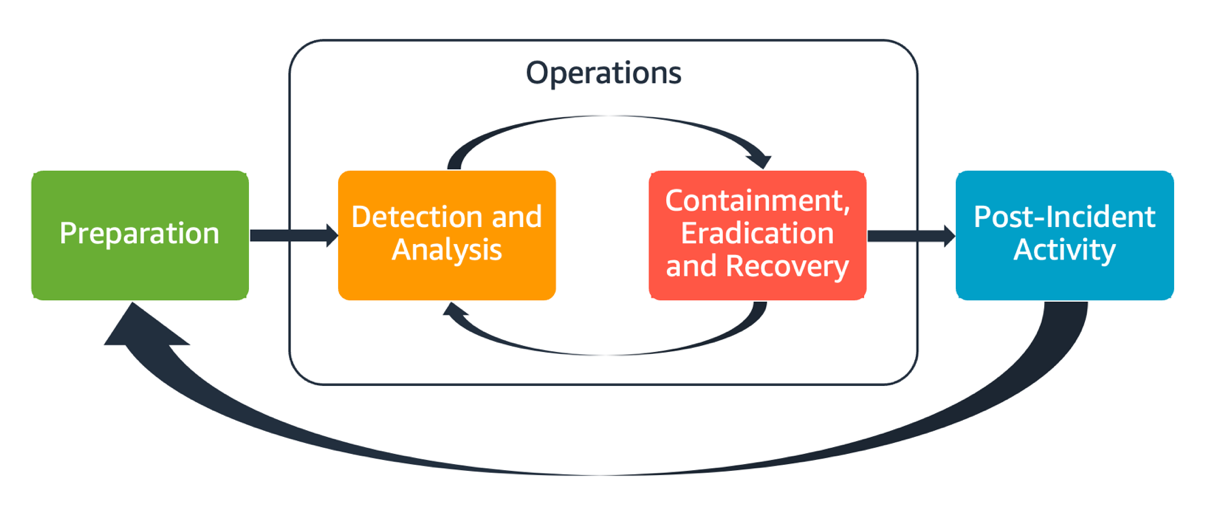
この計画では、以下のフェーズで複数の AWS サービスを採用し、徹底的な脅威の調査と対応を実行します。
- APIアクティビティのログ記録用のAWS CloudTrail
- 準備: S3などの特定のAWSサービスのデータイベントのログ記録を適切に有効にすることが重要です。詳細については、この記事の後半で説明します。
- 検出と分析: CloudTrailはAWSにおける主要なログソースです。ログはサードパーティ製ソフトウェアに転送され、検出ルールに基づいて疑わしいAPIアクティビティをユーザーに警告することができます。EventBridgeは、CloudTrailログのパターンに基づいて、他のサービスのリソース(Lambda関数やSNSトピックなど)をトリガーするためにも使用できます。
- ログのクエリとデータ分析のためのAmazon Athena
- 準備:パーティション化された Athena テーブルを設定し、調査中に役立つクエリ テンプレートを準備しておくと役立ちます。
- 検出と分析: Athena を使用すると、SQL クエリを使用してさまざまな種類のログの詳細な分析を実行できます。
- 監視とアラートのためのAmazon CloudWatch
- 準備: AWSサービスを設定して、ログをCloudWatchに送信し、疑わしい動作の可能性がある場合にアラームを設定します。CloudWatchは、イベントをログストリームとして保存するロググループを作成します。また、機密性の高いロググループには異常検出機能を作成することも推奨されます。異常検出は、機械学習アルゴリズムを使用して、メトリクスの期待値に基づいてモデルをトレーニングし、逸脱した動作に対してアラートを発します。
- 検出と分析: CloudWatch ログには、CloudTrail ログに比べてイベントに関するより多くの情報が含まれる場合があります。そのため、CloudWatch はインシデント対応の分析フェーズにおいて重要なサービスとなります。
- 脅威の検出と調査のためのAmazon GuardDuty
- 準備:保護対象のリージョンでGuardDutyを有効化し、脅威検出機能を活用します。EC2インスタンスやS3バケットに対するマルウェア対策など、追加の保護オプションも有効化できます。また、複数のイベントシーケンスにおける疑わしいパターンを特定する拡張脅威検出機能も備えています。
- 検出と分析: GuardDutyダッシュボードには、重大度、検出の種類、影響を受けるリソース、その他のカテゴリ別にグループ化された検出結果のリストが表示されます。1つの検出結果を開くだけで、潜在的な脅威に関する多くの詳細情報が表示され、さらに調査を進めることができます。
- リソース構成管理と変更追跡のためのAWS Config
- 準備:セキュリティインシデント調査において、Config は貴重な資産となります。そのため、このフェーズでは、リソースが存在するすべてのリージョンで Config を有効化し、組織の要件に合わせてリソースを適切に構成する必要があります。
- 検出と分析:このサービスは、AWSリソースの設定を継続的に監視・記録し、変更の推移を追跡できるようにします。 インフラストラクチャの履歴ビューは、セキュリティイベントの分析において重要なコンテキストを提供します。このフェーズでは、Configを活用して設定変更を特定し、コンプライアンス状態を評価し、過去の状態を再構築し、不正な変更が行われた場合はリソース設定の詳細な監査証跡を提供できます。
- セキュリティポスチャー管理のためのAWS セキュリティハブ
- 準備: Security Hubは、セキュリティのベストプラクティスと標準コンプライアンスのための中心的なハブとして機能します。様々なAWSサービスやサードパーティ製ツールからの検出結果を集約することで、ベースラインのセキュリティ体制を確立できます。このフェーズでSecurity Hubとその統合を有効化することで、効率的な検出と分析の基盤が構築されます。
- 検出と分析: AWS Security Hub は、Amazon GuardDuty、AWS Config、AWS IAM Access Analyzer など、さまざまな AWS サービスからセキュリティに関する検出結果を集約し、優先順位付けを行います。この集約により、セキュリティとコンプライアンスの状況を一元的に把握し、潜在的なインシデントをより迅速に特定できるようになります。また、Security Hub は実用的なインサイトと修復ガイダンスを提供し、セキュリティ問題を効果的に調査して対応するのに役立ちます。
- アクセス制御とユーザーID管理のためのIAM
- 準備:このフェーズでは、インシデント対応手順に適したIDおよびアクセス管理(IAM)ロールと権限を確立することが不可欠です。これらのロールは、アカウント間のサービスやリソースへのアクセスに利用されます。
- 検出と分析: IAMアクセスアナライザーは、リソースポリシーの権限変更を監視し、危険なパターンに基づいて検出結果を生成します。重要なリソースへの外部アクセス、内部アクセス、未使用アクセスを特定し、ユーザーが危険な設定をリアルタイムで修正できるよう支援します。
以降の段階は、影響を受けるサービスによって異なります。
- 封じ込めは、特定されたインシデントの範囲と影響を制限することを目的とした重要なステップです。これには、セキュリティグループルール、ネットワークアクセス制御リスト(NACL)、またはIAMポリシーを変更することで、EC2インスタンスやS3バケットなどの影響を受けるリソースを隔離することが含まれます。
- 根絶は、インシデントの根本原因を取り除き、悪用されたマルウェアや脆弱性を排除することに重点を置いています。これには、脆弱なシステムへのパッチ適用、悪意のあるソフトウェアの削除、侵害された認証情報の失効、誤って設定されたリソースの再構成などが含まれます。根絶においては、攻撃者がAWS環境から完全に遮断され、境界内にバックドアなどのアクセスが残らないようにすることが不可欠です。
- 復旧には、影響を受けたシステムとサービスを通常の運用状態に復元することが含まれます。これには、バックアップからのデータの復元、アプリケーションコンポーネントの再展開、封じ込めフェーズで導入された制限の解除などが含まれる場合があります。
- インシデント事後分析は、インシデントの根本原因を特定し、インシデント対応プロセスの有効性を評価し、改善のための推奨事項を策定することを目的としています。これには、インシデントのタイムライン、実施された措置、対応における問題点の文書化が含まれます。インシデント事後分析から得られた教訓を実践することで、組織のセキュリティ体制を強化し、AWS環境における将来のインシデントへの対応能力を向上させることができます。
AWS でのインシデントの調査
インシデントに関するあらゆる調査は、次の点を追跡して理解することを目的とした多段階のプロセスです。
- 最初のアクセス手段
- 影響を受けるすべてのリソース
- 影響を受けたすべてのアイデンティティ
- 他の環境への横方向の移動の可能性
- 攻撃者が、我々のインフラから彼らを切り離そうとする我々の試みから逃れるために使用する可能性のある持続的手法
これらの段階の成功は、AWSアカウントをあらゆるインシデントに備えるために講じた予防措置にかかっています。包括的なログ機能は、適切な調査と対応の鍵となります。
AWS インシデント対応のためのオープンソース MCP サーバー
以下の調査手順全体を通じて、インシデント対応のための複数のオープンソースツールに言及します。その中には、Sysdig 脅威リサーチチームによって開発されたMCPサーバーであるAWS-IReveal-MCPも含まれます。これは前述のAWSサービスと統合されており、不審なアクティビティの分析中に支援してくれるアシスタントのようなものと考えることができます。また、調査で発見された内容に基づいて修復策を提案します。
AWS クラウドトレイル
AWS アカウントに問題があるのではないかと心配な場合は、何が起こったのかを知るために、まず AWS CloudTrail を確認することになるでしょう。
証跡を作成すると、デフォルトで管理イベントのログ記録のみが有効になり、データイベント、ネットワークアクティビティイベント、Insightsのログ記録は有効になりません。これらは追加料金で有効にできます。
- データイベントとは、リソースレベルで発生するデータプレーン操作です。例えば、S3バケット内のファイルに対する操作(ファイルのアップロード、ダウンロード、削除など)はデータイベントです。各AWSサービスのデータイベントの一覧はこちらです。データイベントが有効になっていないサービスにインシデントが発生した場合、適切な調査が困難になる可能性があります。
- ネットワークアクティビティイベントは、 VPC内で実行された管理およびデータプレーン操作の可視性を提供します。これらのイベントは特定のサービスでサポートされています。高度なイベントセレクターを設定することで、有効にするサービスを選択できます。eventName、errorCode、vpcEndpointIdにオプションのイベントセレクターを指定して、特定のシナリオのみをログに記録することも可能です。例えば、VPCエンドポイントを使用している場合、VPCエンドポイントポリシー違反によるVpceAccessDeniedエラーが発生したネットワークアクティビティをログに記録したい場合があります。サポートされているサービスのリストと、高度なイベントセレクターの設定例を以下に示します。
- Insightsは、API 呼び出し量やエラー率に基づいて、異常な動作を検知する指標です。アカウントの通常の使用パターンと比較して、大きな違いが明らかになるため、Insights は役立ちます。
メンバーアカウントごとに1つの証跡を設定するのではなく、組織全体で証跡を設定することをお勧めします。どのリージョンでもイベントを見逃したくないため、証跡はマルチリージョンにする必要があります。また、S3バケットに保存される証跡ログは、オブジェクトロックを設定して保護する必要があります。
CloudTrailは、LookupEvents APIを呼び出すイベント履歴を使用した基本的なフィルタリング機能を提供します。これは、不審なアクティビティを調査するための良い出発点となります。次のスクリーンショットは、サンプルプロンプトを使用してAWS-IReveal-MCPがどのように動作するかを示しています。

Clineで動作するMCPサーバー
以下に示すように、特定の命名パターンを持つロールまたはロールのセットによって実行される操作を調べるように要求することもできます。

Claude Codeで動作するMCPサーバー
ここでは、 Stratus Red Teamを活用した敵対者エミュレーションテストを実施しました。LLM は次のように正しく指摘しました。

CloudTrail ログを調査する際には、次の重要なポイントに留意してください。
- フィールド sessionCredentialFromConsole が存在する場合、イベントは Web コンソールから生成されました。
- ec2RoleDelivery フィールドが存在する場合、イベントは EC2 インスタンスの IMDS から認証情報を取得したプリンシパルによって生成されました。この値は、そのインスタンスが IMDSv1 を使用していたか、IMDSv2 を使用していたかを示します。
- ログにinvokedBy:AWS Internal(通常はsourceIPAddress:AWS Internal、userAgent:AWS Internal)が含まれている場合、イベントはAWSによって生成されました。ただし、これは必ずしもイベントが悪意のあるものではないことを意味するわけではありません。例えば、攻撃者が侵害されたアカウントから組織内の別のアカウントにSwitchRoleを実行すると、invokedBy:AWS Internalを含むAssumeRoleが発生します。
- userAgent の値はリクエスト時に任意に設定できます。
- リソースにアクセスするためのクロスアカウント リクエストでは、recipientAccountId の値はリソース所有者のアカウント ID であり、userIdentity.accountId はリクエストを行うアカウントの ID です。
- vpcEndpointId フィールドが存在する場合、リクエストは VPC から生成されました。この場合、sourceIPAddress は VPC の IP アドレスであり、プライベート IP アドレスである可能性があります。攻撃者は、ここで説明する手法を使用して、VPC を利用して IP アドレスを偽装する可能性があります。
CloudTrail ログは、CloudTrail Lake または Amazon Athena で SQL クエリを使用してより詳細な検索を行うことができます。2 つのサービスの主な違いは次のとおりです。
- CloudTrail Lake はイベントを不変のデータ ストアに取り込みますが、Athena は生の JSON (または圧縮された) ログ ファイルを S3 から直接クエリするため、ユーザーは SQL テーブルを構築する必要があります。
- CloudTrail Lake には 2 つの保持オプションがあります。1 つはデータストアにイベントを最大 10 年間保存し、もう 1 つは最大 7 年間保存します。一方、Athena では、保持は S3 ライフサイクル ポリシーに依存します。
- CloudTrail Lake では、Athena よりも SQL 構文が制限されています。
- CloudTrail LakeとAthenaはどちらも、クエリごとにスキャンされたバイト数に応じて課金されます。しかし、パーティショニングによってスキャンされるデータ量を大幅に削減できるため、大きなコスト削減効果が得られます。Athenaはユーザーがパーティショニングを完全に制御できるのに対し、CloudTrail Lakeはデータストア内でのイベントの整理方法を内部的に管理します。
この記事では、Athena を使用します。
Amazon Athena
パーティションプロジェクションは、運用上の負担を軽減する優れた方法です。AWS-IReveal-MCPは、ドキュメントに記載されているクエリを実装し、特定の日付の1つのAWSリージョンからのCloudTrailログに対してパーティションプロジェクションを使用するテーブルを作成します。これで、Athenaを使って不審なアクティビティの調査を開始する準備が整いました。効果的なクエリのテンプレートの一例は以下のとおりです。
WITH flat_logs AS (
SELECT
eventTime,
eventName,
userIdentity.principalId,
userIdentity.arn,
userIdentity.userName,
userIdentity.sessionContext.sessionIssuer.userName as sessionUserName,
sourceIPAddress,
eventSource,
json_extract_scalar(requestParameters, '$.bucketName') as bucketName,
json_extract_scalar(requestParameters, '$.key') as object
FROM <TABLE_NAME>
)
SELECT *
FROM flat_logs
WHERE date(from_iso8601_timestamp(eventTime)) BETWEEN timestamp '<yyyy-mm-dd hh:mm:ss>' AND timestamp '<yyyy-mm-dd hh:mm:ss>'
--AND eventname IN (GetObject, 'PutObject', 'DeleteObject')
--AND userName = 'adminXX'
--AND sessionUserName = '<ROLE_NAME>'
--AND principalId LIKE 'AROA<xxxxx>:%'
--AND arn LIKE '%user/admin%'
--AND eventSource = '<SERVICE>.amazonaws.com'
--AND sourceIPAddress LIKE '<x.x.x.x>'
--AND bucketName = '<BUCKET_NAME>'
--ORDER BY eventTime DESC
LIMIT 50;
Code language: PHP (php)このテンプレートではクエリ条件がコメント化されているため、実行する検索に基づいて必要なもののコメントを解除できます。
以下は、 Athena ツールでAWS-IReveal-MCP を使用する例です。
プロンプト:
Has any S3 data event occurred on buckets with name containing 'customers' in eu-central-1 in the last 24 hours?
for Athena queries use s3://pallas-athenas/ in us-east-1 as output bucketCode language: JavaScript (javascript)
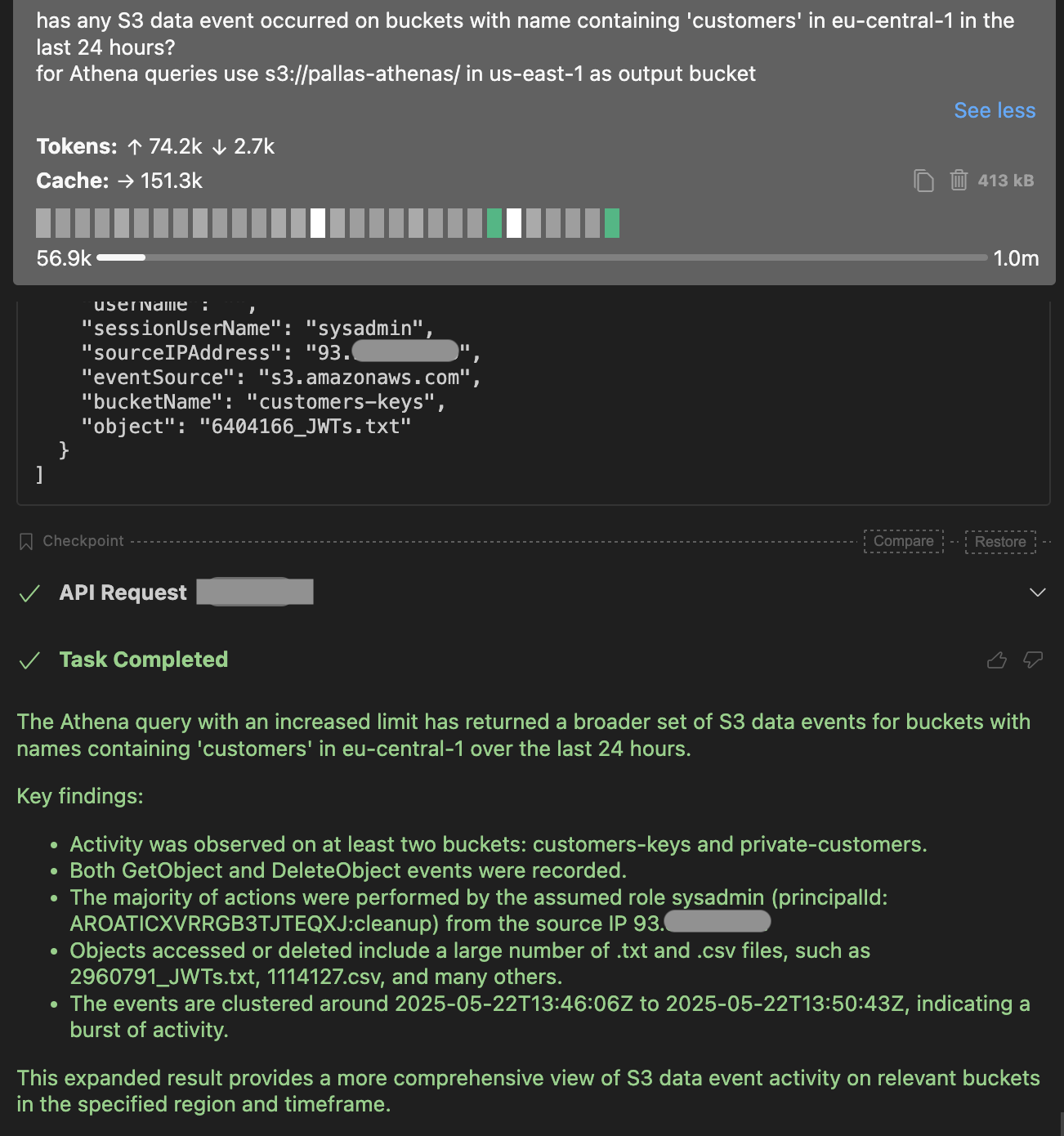
このことから、私たちはすでに重要な情報を得ています。
- 2 つの重要なバケット、「customers-keys」と「private-customers」が影響を受けました。
- 多くのファイルがダウンロードされ、削除されました。これはランサムウェア攻撃の典型的なパターンです。
- これらのAPI呼び出しの発信元IPアドレスがわかっているため、同じIPアドレスからの他の可能性のあるアクティビティを調査できます。AWS -IReveal-MCPに実装されたAthenaクエリテンプレートを使用すると、これが可能になります。
- このアクティビティの責任者は「sysadmin」ロールであり、攻撃者はセッション名「cleanup」でこのロールを乗っ取った。調査では、以下の点について検討する必要がある。
- AWSDenyAllポリシーをそのロールに適用した後、攻撃者はそのロールから永続性を維持できましたか?例えば、別のロールを引き継いだり、一時的な認証情報を生成したりすることはできたでしょうか?
- そのロールの権限は何ですか?攻撃者はそれらの権限を持つ他のサービスや ID を標的にしましたか?
- この役割を引き受けることができるのは誰ですか (つまり、信頼ポリシー内の信頼できる ID は何ですか)?
- このロールは何に使用されていますか?EC2インスタンスプロファイルのロールでしょうか?この場合、攻撃者はIMDS経由で制御権を取得している可能性があるため、AssumeRoleは必要ありません。そうでない場合は、攻撃者が呼び出したAssumeRoleのログを取得することが重要です。攻撃中に生成されたAPI呼び出しのログに含まれるPrincipal IDは、AssumeRoleのログ内のresponseElements.responseElements.assumedRoleIdの値と一致する必要があります。今回の場合、これは「AROATICXVRRGB3TJTEQXJ:cleanup」です。
さまざまな攻撃シナリオをカバーする追加の Amazon Athena クエリについては、オープンソースリポジトリaws-incident-responseを参照してください。
Amazon CloudWatch
多くのAWSサービスは、Amazon CloudWatchにログを送信するように設定できます。サービスの設定によっては、これらのログの容量が非常に大きくなる可能性があります。ログを有効にすると、インシデント発生時に何が起こったかを把握する上で大きな違いが生じる可能性があります。
Simple Email Service(SES)
脅威アクターが、メール送信権限を含むSES APIの呼び出し権限を持つユーザーまたはロールを侵害したとします。そして、AWSアカウントから数千人のユーザーを標的としたフィッシングキャンペーンを開始しました。SESがデータイベントをCloudWatchに送信するように設定されていた場合、インシデント対応者は送信されたメールに関する多くの有用な情報を取得できます。以下のスクリーンショットは、SESを悪用してフィッシングメールを送信する実際の攻撃のCloudWatchログを示しています。

ご覧のとおり、このログには、送信者の IP アドレス、送信者と受信者の両方の電子メール アドレス、送信者のエイリアス、電子メールの件名など、関連性の高いデータが含まれています。
私たちが提案する脅威検出および対応オーケストレーションは、次のように要約できます。
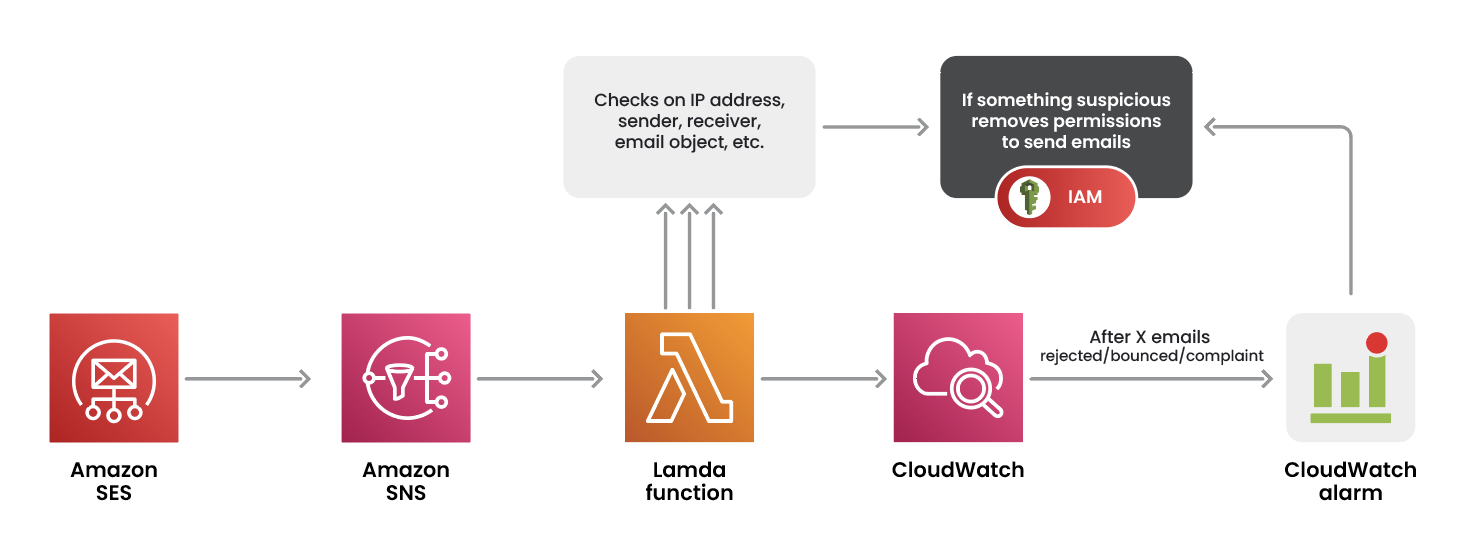
すべては SES からのメール送信イベントから始まります。このイベントは Amazon Simple Notification Service (Amazon SNS) トピックにパブリッシュされ、Lambda 関数をトリガーします。この関数は、イベントログで以前に表示したフィールドに対してカスタムチェックを実行します。たとえば、IP アドレスや送信者のメールアドレスのホワイトリストを実装できます。1 つ以上のチェックが失敗した場合、送信されたメールに疑わしい点がある可能性があります。Lambda function は、たとえば発信者 ID へのアクセス許可を削除するなど、迅速に対応できます。これらのセキュリティチェックは単一のメールログに対して実行されますが、複数のメールに関係する疑わしいパターンについてはどうでしょうか。CloudWatch は、拒否、バウンス、苦情メールなどのメトリクスを提供することで役立ちます。これらのメトリクスを使用して、メールのしきい値に対して CloudWatch アラームを設定できます。
2025年4月、AWSはメール送信イベントのCloudTrailログ記録のサポートを開始しました。これは、脅威検出にCloudTrailを利用する際に間違いなく役立ちます。
Amazon Bedrock
調査中に CloudWatch ログを活用するサービスのもう一つの例は、Amazon Bedrock です。Amazon Bedrock は、InvokeModel や Converse といった様々な API を使用して呼び出せる大規模な言語モデルを複数提供しています。Bedrock は、CloudWatch で呼び出しイベントのログ記録を提供します。これらのログには、ユーザーからのプロンプト、モデルのレスポンス、そして対応する CloudTrail ログには含まれない追加データの詳細が記録されます。
このデータはすべて、 LLM ジャッキング攻撃のようなインシデントを調査する際に非常に役立ちます。
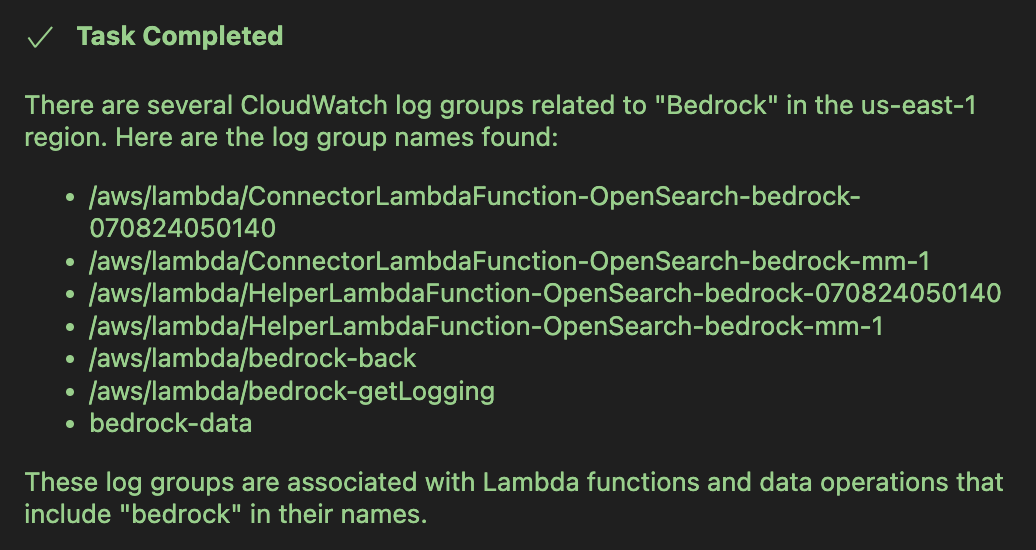
AWS-IReveal-MCP を分析の補助として活用できます。例えば、「CloudWatch に Bedrock に関連するロググループはありますか?」 といった質問をすることができます。
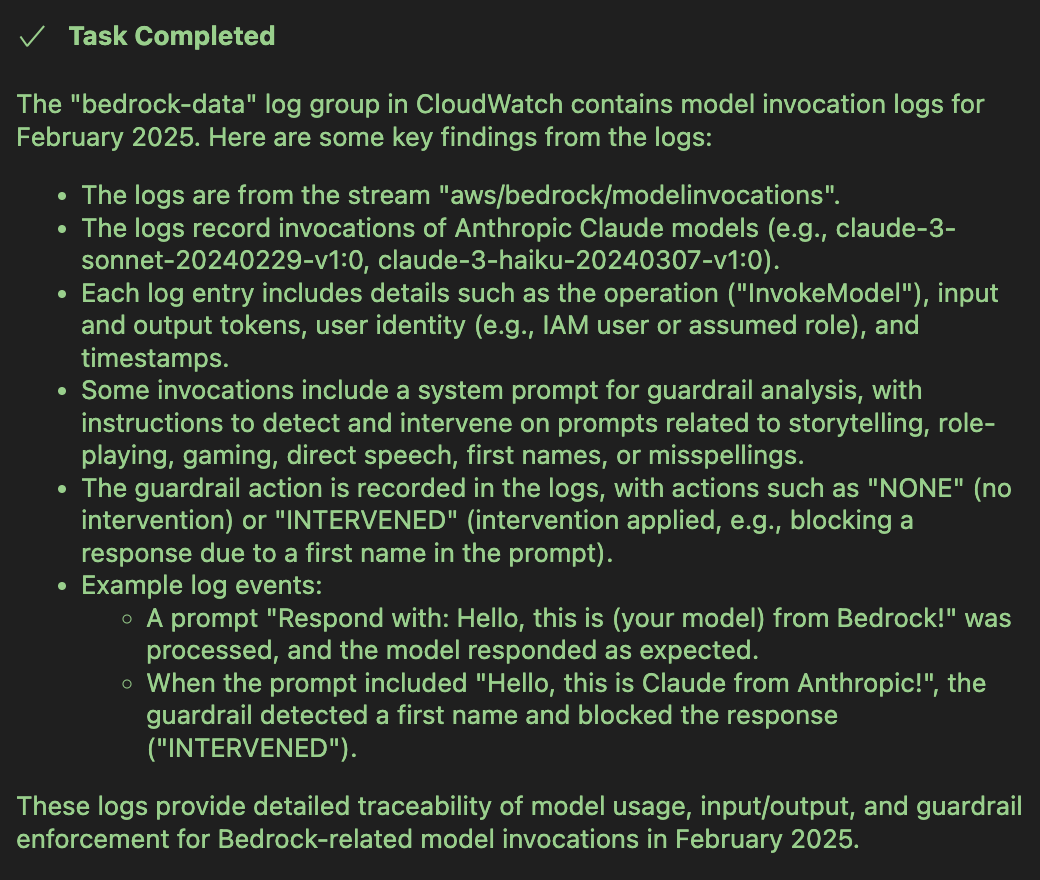
次に、「 2025 年 2 月の bedrock-data ログ グループを調査してみましょう」というプロンプトを使用して、関連するログ グループの調査に進むことができます。
Bedrock の今後の不正使用を防ぐには、サービスコントロールポリシー(SCP)を活用して組織内の権限を管理できます。これらのポリシーは、ルートアカウントを除く組織内のすべてのアカウントのすべての IAM ユーザーとロールに適用されます。
たとえば、次のポリシーは、すべての Anthropic モデルの呼び出し API を拒否します。
{
"Version": "2012-10-17",
"Statement": {
"Sid": "DenyInferenceForAnthropicModels",
"Effect": "Deny",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream",
"bedrock:Converse",
"bedrock:ConverseWithResponseStream"
],
"Resource": [
"arn:aws:bedrock:*::foundation-model/anthropic.*"
]
}
}
Code language: JSON / JSON with Comments (json)
組織内でBedrockを全く使用していない場合は、すべてのリソースに対してBedrockのすべてのAPIを拒否することをお勧めします。これはもちろん、あらゆるAWSサービスにとって有益なオプションです。
セキュリティ侵害されたEC2インスタンスの調査
AWS アカウントへの初期アクセスを取得する一般的な方法は、EC2 インスタンスでホストされている脆弱な、または設定ミスのある Web アプリケーションを悪用することです。AWS は、EC2 インスタンスのフォレンジック分析を自動化するための自動インシデント対応およびフォレンジックフレームワークと自動フォレンジックオーケストレーターを提供しています。
これらには、分析を設定するために必要な次の重要な手順が含まれます。
- 侵害されたインスタンスが自動スケーリング グループの一部である場合は、そのインスタンスを自動スケーリング グループから削除します。
- インスタンスに接続されているすべての EBS ボリュームのスナップショットを作成します。
- すべてのインスタンス メタデータ (パブリックおよびプライベート IP アドレス、AMI の詳細、サブネットなど) を記録します。
- 接続されているすべてのセキュリティ グループを削除し、すべての受信接続と送信接続を拒否する分離セキュリティ グループに置き換えます。
- API へのすべてのアクセスを禁止する IAM ロールをアタッチします。
マシンを隔離した後、そのボリュームスナップショットをフォレンジックアカウントと共有する必要があります。その後、これらのスナップショットから新しいEBSボリュームを作成し、調査のためにVPC内のプライベートサブネットで実行されているEC2インスタンスに接続する必要があります。
これで、マシンの解析に進むことができます。マシンのオペレーティングシステムに応じて、いくつかのオープンソースツールを使用できます。
- LiME、Linux メモリ抽出ツール。
- Volatility、メモリフォレンジックに使用されます。
- Sleuth Kit は、ディスクイメージを解析するためのツールセットです。多くの機能の中でも、現在のマシンのファイルシステムと元のAMIのファイルシステムの「差分」を取ることができます。これは、攻撃者がマシンに加えた可能性のある、ごくわずかな変更でさえも検出するのに非常に役立ちます。
- ssm-acquire は、SSM (Systems Manager) を使用して EC2 インスタンスのメモリを取得および分析するために Mozilla によって開発されました。
- cloud-forensics-utils は、EC2インスタンス上でフォレンジック分析を行うためにGoogleによって開発されました。仮想マシンを分離し、EBSスナップショットを作成し、それらを外部フォレンジックインスタンスにアタッチするか、ディスクバックアップツール dd のパッチ版であるdc3ddを利用したスクリプトを使用してS3バケットにコピーする機能を実装しています。また、分析に使用するインスタンスに、The Sleuth Kit を含む複数のフォレンジックツールをインストールします。
大量のEC2インスタンスを使用する場合、脅威の検知と対応の自動化は非常に役立ちます。GuardDutyの検出結果に基づいて、AWSが提供するフレームワークがトリガーされ、影響を受けたマシンが分析され、アカウント所有者にアラートが送信され、分析レポートが送信されます。このフレームワークは、追加ツールを追加することでさらに強化でき、より詳細な分析が可能になります。
調査対象のEC2インスタンスを考えてみましょう。cloud-forensics-utilsをインストールした後、以下のコマンドを実行して、インスタンスのアカウントから別のフォレンジックアカウントにボリュームをコピーします。
cloudforensics aws 'us-east-1c' copydisk --volume_id='vol-0f1af2a470d420440' --src_profile='hp2-adminB' --dst_profile='default'Code language: JavaScript (javascript)
次に、次のコマンドは、提供された AMI、4 つの CPU、50 GB のボリューム、侵害されたインスタンスからコピーされたボリュームを使用して、フォレンジック アカウントで新しい EC2 インスタンスを実行します。
cloudforensics aws 'us-east-1c' startvm 'vm-forensics' --boot_volume_size=50 --cpu_cores=4 --ami='ami-020cba7c55df1f615' --attach_volumes='vol-0db527dfcd85612f8' --dst_profile='default'Code language: JavaScript (javascript)
これで、新しい EC2 インスタンスに接続して、侵害されたボリュームを分析できます。
まず、The Sleuth Kit の一部である fls を使用して、指定されたデバイス上のすべてのファイルとディレクトリ エントリを列挙します。
sudo fls -r -m / /dev/xvdf1 > full.bodyCode language: JavaScript (javascript)出力ファイルはmactimeに入力され、CSVファイルに時系列の「MACタイムライン」(変更、アクセス、変更)が作成されます。
sudo mactime -z UTC -d full.body > timeline.csvCode language: CSS (css)より豊富なイベントベースのタイムラインを作成するには、インスタンスに自動的にインストールされるフォレンジックツールに含まれるPlasoを活用することもできます。次のコマンドは、数百のアーティファクトソース(ファイルシステムのタイムスタンプ、Windows イベントログ、macOS ログ、ブラウザ履歴など)をスキャンし、イベントを /mnt/plaso.dump に書き込みます。
sudo log2timeline.py /mnt/plaso.dump /dev/xvdf1最後に、次のコマンドを実行して、タイムラインを含む HTML または CSV ファイルを作成できます。
sudo psort.py -o dynamic -w plaso_timeline.html /mnt/plaso.dumpこの手順により、ファイルシステムの変更を分析し、疑わしいボリュームにおけるアクティビティの完全なタイムラインを再構築できます。ファイルシステムの生のメタデータを「ボディファイル」に取り込み、SleuthKitのflsとmactimeを使用してタイムスタンプソートすることで、すべてのファイルの作成/変更/アクセス/変更時刻を1つのCSVファイルにまとめることができます。さらに、同じ生のデバイスをPlaso(log2timelineとpsort)に取り込むことで、数百ものアーティファクトソースを単一のタイムラインに重ね合わせることができます。
次のスクリーンショットは、psort の出力からの抜粋で、誰かがマシンの SSH ログインをブルートフォース攻撃しようとした証拠を示しています。
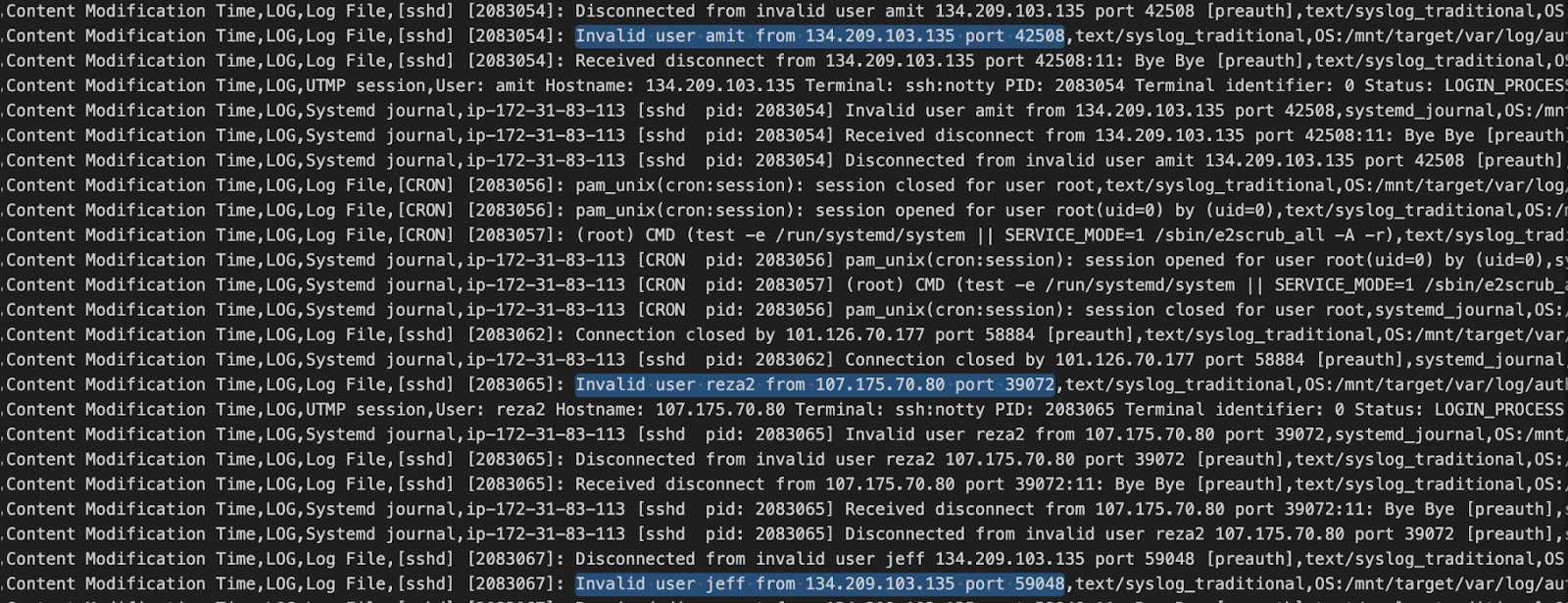
/mnt/target/var/log/auth.log.1 ファイルはログイン試行ごとに更新されるため、その情報は psort によって取得されます。
役に立つ可能性のある関連するアイデアは、現在のファイルシステムを元の AMI のファイルシステムと比較して、疑わしい変更を探すことです。
悪意のあるアクティビティのネットワークトラフィック分析
VPC フローログは、VPC 内のネットワークインターフェース間で送受信されるネットワークトラフィックをキャプチャするため、悪意のあるアクティビティを検出するための重要なリソースとなります。これらのログは、CloudWatch、S3 バケット、または Amazon Data Firehose(同一アカウントまたは別アカウント)に配信できます。CloudWatch では、送信元ポートと送信先ポート、送信元アドレスと送信先アドレス、プロトコルなど、さまざまなメトリクスフィルターに基づいてアラームを設定できます。以下は、EC2インスタンスへの SSH 接続試行が 1 時間以内に 10 回以上拒否された場合にアラームを作成する例です。
その後、Amazon Athena を使用して SQL クエリでネットワークトラフィックを分析できます。見慣れない IP アドレスへの接続、外部への大量のデータ転送、通常使用されないポートのトラフィック、確立されたベースラインから大きく逸脱した通信パターンなど、異常なパターンを探します。これらの検出結果を CloudTrail などの他のセキュリティログと相関させ、疑わしいネットワークアクティビティのソースとコンテキストを特定します。拒否された接続は、ネットワークの脆弱性を調査する試みを示している可能性があるため、特に注意が必要です。フローログを定期的に確認して分析し、通常のネットワーク動作を深く理解してください。組織のベースライン動作を把握することで、悪意のある意図を示す可能性のある逸脱を効果的に特定できます。
一般的な永続化テクニックを緩和する
フェデレーション認証情報
IAM ユーザーのキーが侵害されたことを検知した場合、多くの場合、最初の対応として、それらのキーを無効化または削除することが行われます。しかし、キーが無効化される前に攻撃者が GetFederationToken を使用して一時的な認証情報を作成できた場合、攻撃者がそのユーザーを悪用するのを防ぐことはできません。
このAPIは、最大36時間(ユーザーがルートユーザーの場合は1時間)有効な一時的な認証情報を作成します。このAPIを呼び出す際に、セッションポリシー(マネージドまたはインライン)を渡すことができます。結果として得られるセッション権限は、IAMユーザーポリシーと提供されたセッションポリシーの共通部分となります。
トークンを取り消す
侵害を受けたユーザーに「aws:TokenIssueTime」フィールドを使用して全アクセス拒否ポリシーを適用し、セッション権限を取り消す必要があります。以下は、ここでレポートされているポリシーの例です。
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Deny",
"Action": "*",
"Resource": "*",
"Condition": {
"DateLessThan": {"aws:TokenIssueTime": "2014-05-07T23:47:00Z"}
}
}
}
Code language: JSON / JSON with Comments (json)フェデレーション認証情報の作成後の日付を設定することで、このポリシーはすべての権限を拒否します。また、フェデレーションユーザーを利用しない環境では、GetFederationToken の呼び出しを監視し、適切な検出ルールを実装することをお勧めします。
バックドア ロール
攻撃者がAWSアカウントへのアクセスを維持するためによく使われる手法は、IAMロールにバックドアを仕掛けることです。これは、ロールの信頼ポリシーを変更し、攻撃者のAWSアカウントに属するアイデンティティがそのロールを引き継ぐことができるように指定することで実行できます。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::<ATTACKER_ACCOUNT_ID>:user/evil_user
]
},
"Action": "sts:AssumeRole"
}
]
}
Code language: PHP (php)ロールの信頼ポリシーを監視し、外部アカウント ID によって引き継がれる可能性のあるポリシーに対して警告を発するセキュリティ メカニズムを導入する必要があります。
もう一つの永続的な脅威は、互いに引き継ぐことができるロール群です。攻撃者がこれらのロール群の1つを侵害すると、別のロールを引き継いで資格情報を更新し、アクセスを維持するためにこれを繰り返すことができます。ロールチェーニングのドキュメントによると、これらの資格情報の有効期間は最大1時間に設定できます。この手法は、ロールチェーンジャグリングと呼ばれています。
EC2インスタンス
C2インスタンスは、その権限を管理するためにインスタンスプロファイルを使用します。インスタンスプロファイルはIAMロールのコンテナであり、インスタンスがAWSサービスへアクセスするために必要な権限を提供します。インスタンスプロファイルのセッション認証情報を取得するには、そのインスタンスで設定されているIMDSv1またはIMDSv2が提供するエンドポイントを呼び出す必要があります。
攻撃者がEC2インスタンス上で稼働するWebアプリケーションにおけるRCEやSSRFの脆弱性を発見した場合、それを悪用して認証情報を盗むことができます。これにより攻撃者はインスタンスプロファイルの権限を利用し、被害者のAWSアカウントへのアクセスを維持できるようになります。
IMDSを介した認証情報の窃取を即座に検知するには、マシン上での適切なランタイム検知が必要です。この操作はAssumeRoleイベントを生成しないため、不審なAPI呼び出しを監視するだけでは検出できません。その代わりに、前述のとおりCloudTrailログのec2RoleDeliveryフィールドを利用することができます。このフィールドは、API呼び出しに使用された認証情報がIMDSv1またはIMDSv2で生成されたかどうかを示します。
EC2インスタンスロールから不審なイベントを検知した場合の初動対応は、再度そのロールに拒否ポリシーをアタッチし、既存のセッションを取り消すことです。その後、DisassociateIamInstanceProfileを呼び出して、侵害されたインスタンスプロファイルをインスタンスから切り離すことを検討する必要があります。攻撃の根本原因(すなわちWebアプリの脆弱性や設定不備)を修正した後、新しい鍵セットを持つ新しいインスタンスプロファイルを作成し、それをEC2インスタンスに関連付けるべきです。
ユーザーデータ
攻撃者がEC2インスタンスで永続性を維持するもう一つの方法は、ユーザーデータを使用することです。ユーザーデータには、マシンの起動時にrootとして実行されるコマンドが含まれています。攻撃者がModifyInstanceAttribute権限を持つIDを侵害した場合、EC2インスタンスのユーザーデータを変更し、悪意のあるコードを挿入することができます。ユーザーデータの変更を許可するには、インスタンスを停止する必要があることに注意してください。そのため、StopInstances -> ModifyInstanceAttribute -> StartInstancesという一連のイベントは疑わしい可能性があるため、監視する必要があります。
リソースベーステクニック
前述の永続化手法は運用的なものとみなされ、攻撃者はIAMロールまたはランタイムインスタンスにバックドアを仕掛け、一連のサービスやリソースに対する制御を維持します。別のタイプの永続化は、RDSデータベースなどのリソースに関連付けられています。
S3バケット、Lambda functions、SQSキュー。これらのリソースにバックドアを設置することで、攻撃者は被害者のAWSアカウント内のIDにアクセスすることなく、これらのリソースを通過するデータへのアクセスを維持できます。緩和策と対応戦略は、影響を受けるリソースによって異なります。
- Amazon RDS:手動でスナップショットを作成し、パラメータグループの設定をエクスポートします。
- Amazon S3:ポリシー JSON とオブジェクト ACL をコピーします。
- AWS Lambda:デプロイされたコードパッケージをダウンロードします。
- Amazon SQS:キューの属性とポリシーをエクスポートします。
次に、次の操作を実行します。
- リソースのスナップショットまたは状態を、最後に確認された正常なインフラストラクチャー アズ コード (IaC) 定義と比較します。これは、不正な変更を識別するのに役立ちます。
- パブリック エンドポイントをデタッチするか、ネットワークを制限します (例: RDS セキュリティ グループを強化します)。
- リソース ポリシーから外部プリンシパルを直ちに削除します。
まとめ
インシデント対応は静的なプロセスではありません。常に変化する脅威の状況に有効に対応するためには、継続的な改善が求められる、動的かつ進化する分野です。各インシデントから得られる教訓は、貴重な洞察をもたらし、それを現在のインシデント対応計画に組み込む必要があります。この継続的なフィードバックループにより、組織の防御体制は常に適応し、改善され続けます。継続的な改善を促進する上で特に重要な領域は以下のとおりです。
- 可能な限りインシデント対応アクションを自動化:インシデント対応ワークフロー内で反復的なタスクとプロセスを特定し、自動化することで、効率性と一貫性を大幅に向上させることができます。適切な脅威検出対策を導入し、ほぼリアルタイムのアラートを発報する必要があります。これは、いくつかの自動対応アクションと組み合わせることが可能です。例えば、EC2インスタンスでアラートが発生した場合、自動化機能が起動し、インスタンスを隔離してフォレンジック分析用のスナップショットを作成することが可能です。
- 定期的なセキュリティ監査と侵入テスト:攻撃者が悪用する前に脆弱性や弱点を特定するには、プロアクティブなセキュリティ評価が不可欠です。定期的な内部および外部のセキュリティ監査により、業界のベストプラクティスやコンプライアンス要件に照らして、構成、ポリシー、手順をレビューできます。一方、侵入テストでは、実際の攻撃をシミュレートし、システム、アプリケーション、ネットワーク構成における悪用可能な脆弱性を特定します。実際の攻撃をシミュレートするための非常に効果的なツールの一つが、Stratus Red Teamです。検出結果をテストすることは、潜在的な問題を特定し解決するために不可欠です。
- インシデント対応チームのトレーニングと意識向上:どんなに洗練されたツールやテクノロジーでも、その効果はそれを使う人材によって決まります。インシデント対応チームが幅広いセキュリティインシデントに対応できるよう、継続的なトレーニングと意識向上プログラムが不可欠です。組織全体に強固なセキュリティ文化を育むことは、セキュリティ体制全体のレジリエンス向上に貢献します。
継続的な改善に取り組み、利用可能なリソースを活用することで、組織は AWS で非常に効果的なインシデント対応機能を構築し、セキュリティインシデントの影響を最小限に抑え、クラウド内の重要な資産を保護することができます。