
本文の内容は、2025年10月23日に Paolo Polidori が投稿したブログ(https://www.sysdig.com/blog/kubernetes-incident-response-detect-investigate-and-contain-in-under-10-minutes/ )を元に日本語に翻訳・再構成した内容となっております。
Kubernetesでレスポンスが重要な理由
Kubernetes環境では、脅威の検知は戦いの半分に過ぎません。本当に重要なのは、脅威が検知された場合に、いかに迅速かつ効果的に対応できるかです。ワークロードは数秒で起動と停止を繰り返し、コンテナは痕跡をほとんど残さないことが多いため、有効な対応策を講じられる時間は限られています。Sysdigのクラウド検知と対応に関する555ベンチマークは、迅速な検知だけでは不十分であることを示しています。10分以内に検知、調査、対応を行う必要があります。このブログでは、Kubernetesの検知と対応ワークフローを詳しく説明し、Sysdigのインラインレスポンスアクションが迅速かつ確実に、より良い結果をもたらす方法をご紹介します。
より迅速な対応は、平均封じ込め時間(MTTC)に直接影響を与え、攻撃者が横方向に移動したりデータを持ち出したりできる時間枠を短縮します。MTTCを短縮することで、チームはリスクの曝露を最小限に抑え、インシデントの影響範囲を限定します。
先日、ホスト環境向けのインラインレスポンスアクションに関するブログを公開しました。このブログでは、Sysdigの最新のインライン機能を使用したKubernetes固有のレスポンスワークフローについて説明します。
インラインKubernetesアクションの紹介
インラインレスポンスアクションを使用すると、Sysdigイベントから直接、コンテキストに応じた即時のアクションを実行できるため、ツールを切り替えることなく脅威や問題に対応できます。ボリュームのスナップショットの取得からネットワークの分離まで、自動化された正確な対応アクションは、滞留時間の短縮、インシデントの封じ込め、Kubernetes環境のセキュリティ維持に不可欠です。
セキュリティインシデントの調査と対応のためにワークロードにアクセスするには、多くの場合、異なるスキルセットを持つ他のチームの支援が必要になります。こうした依存関係は対応作業を遅らせ、セキュリティチームに不必要な複雑さをもたらします。Kubernetesは、抽象化レイヤーと運用上の複雑さを追加することで、この課題をさらに困難にします。
インシデントへの対応には通常、次のことが必要です。
- 対象リソースへの適切なアクセス権を持つこと
- それらのリソースを見つけて接続する方法を知る
- Kubernetesの詳細(どのコマンドを実行するか、どのように実行するかなど)を理解する
- 意図せず本番環境に影響を与えるリスクを回避する
Sysdigは、セキュリティチームが最も苦労する領域に直接対応機能を拡張することで、この問題に対処します。Sysdigを使用すると、アクセスと接続は自動的に処理されるため、Kubernetesに関する深い専門知識の必要性が大幅に軽減されます。これにより、ミスのリスクが最小限に抑えられ、マネージドオンプレミスおよびクラウドKubernetes環境(GCP、Azure、AWS、Oracleなど)全体で効果的な対応能力が向上します。
Sysdig Threat Management ダッシュボードを用いて、実際のインシデント対応シナリオを詳しく見ていきましょう。コンテキストに基づくインサイトとインラインアクションによって、調査と修復がどのように効率化され、チームが555ベンチマークを達成できるようになるかをご紹介します。
ウォークスルー: リアルワールドにおける深刻な Kubernetes の脅威
Sysdig Threat Management ダッシュボードを確認すると、「潜在的なマルウェアアクティビティ」というラベルの付いたワークロードで重大度の高い Kubernetes 脅威が検知されていることが把握できます。
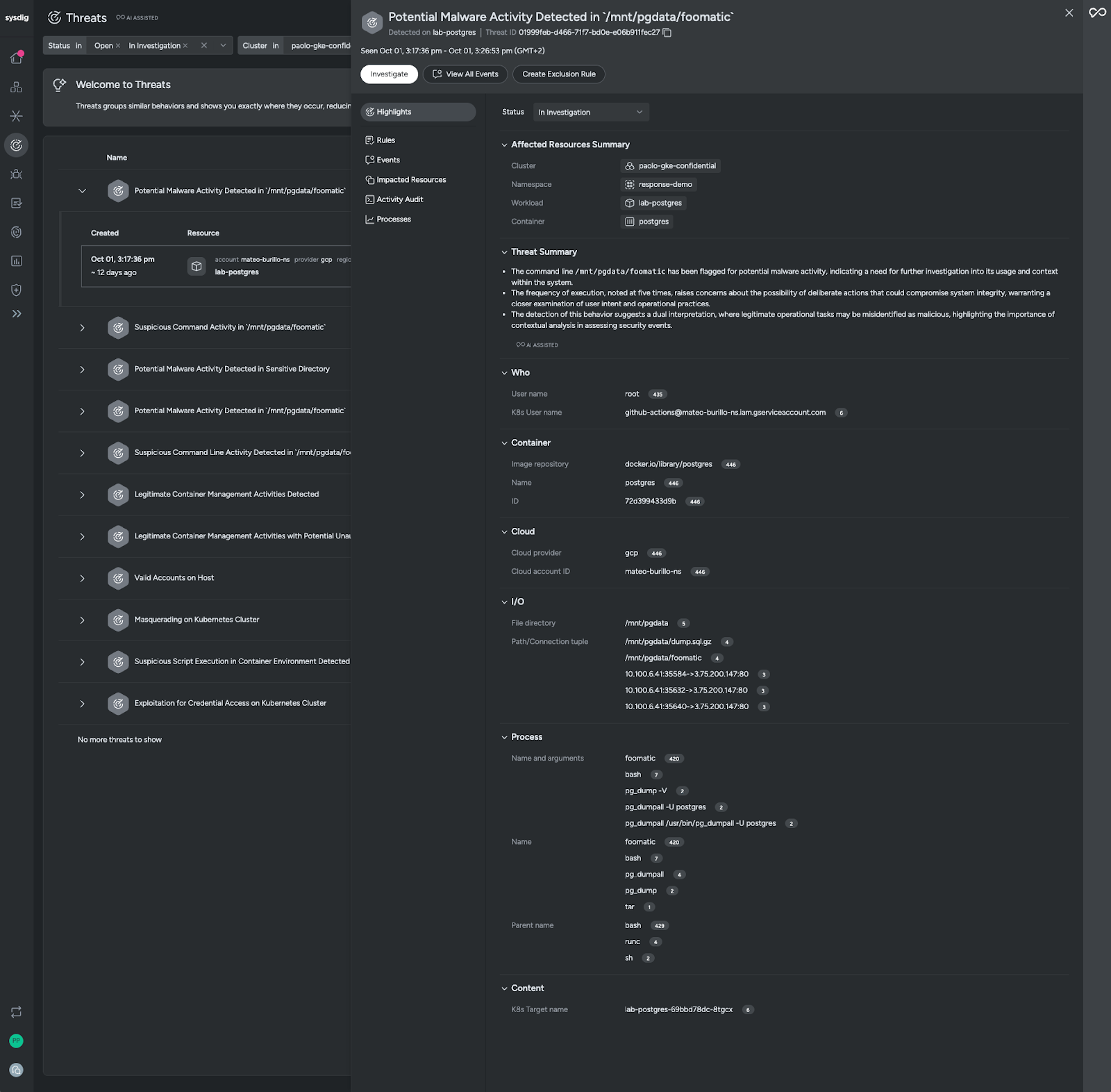
重要なコンテキストをすぐに把握
脅威検知をクリックすると、Sysdig Sage™が提供する脅威サマリーから重要なコンテキストを迅速に取得できます。以下のことが把握できます。
- コマンドラインには
/mnt/pgdata/foomatic潜在的なマルウェアアクティビティのフラグが付けられており、システム内での使用方法とコンテキストについてさらに調査する必要があることを示しています。 - 実行頻度が5回であることから、システムの整合性を損なうような意図的な行為の可能性が懸念されます。ユーザーの意図と運用慣行を詳細に調査する必要があります。
- この動作の検出は、正当な運用タスクが悪意のあるものとして誤認される可能性があるという二重の解釈を示唆しており、セキュリティ イベントの評価におけるコンテキスト分析の重要性が強調されています。
さらに深く掘り下げる
脅威の概要の下のコンテキストは、この潜在的な脅威の誰が、何を、どこで、いつ、どのように行うのかを理解するための追加の手がかりとなります。
- github-action サービス アカウントが何かを実行しました。
- HTTP ポートへの接続がいくつか行われました。
pg_dumpalltar および疑わしい foomatic の使用とともに実行されました。
影響範囲の定義
詳しく調査していく中で、影響範囲、特に関連する具体的なリソースを把握していきます。この例では、影響を受けるリソースはGKE内のPostgresのKubernetesデプロイメントであることがわかります。

相関イベントの評価
影響を受けたリソースを把握した後、脅威を構成する個々の関連イベントに焦点を絞りました。検知結果では、脅威サマリーに表示されている未知の潜在的に悪意のある実行ファイルと同じfoomaticによって実行された、C2サーバーへのアウトバウンド接続が急増していることが確認されました。
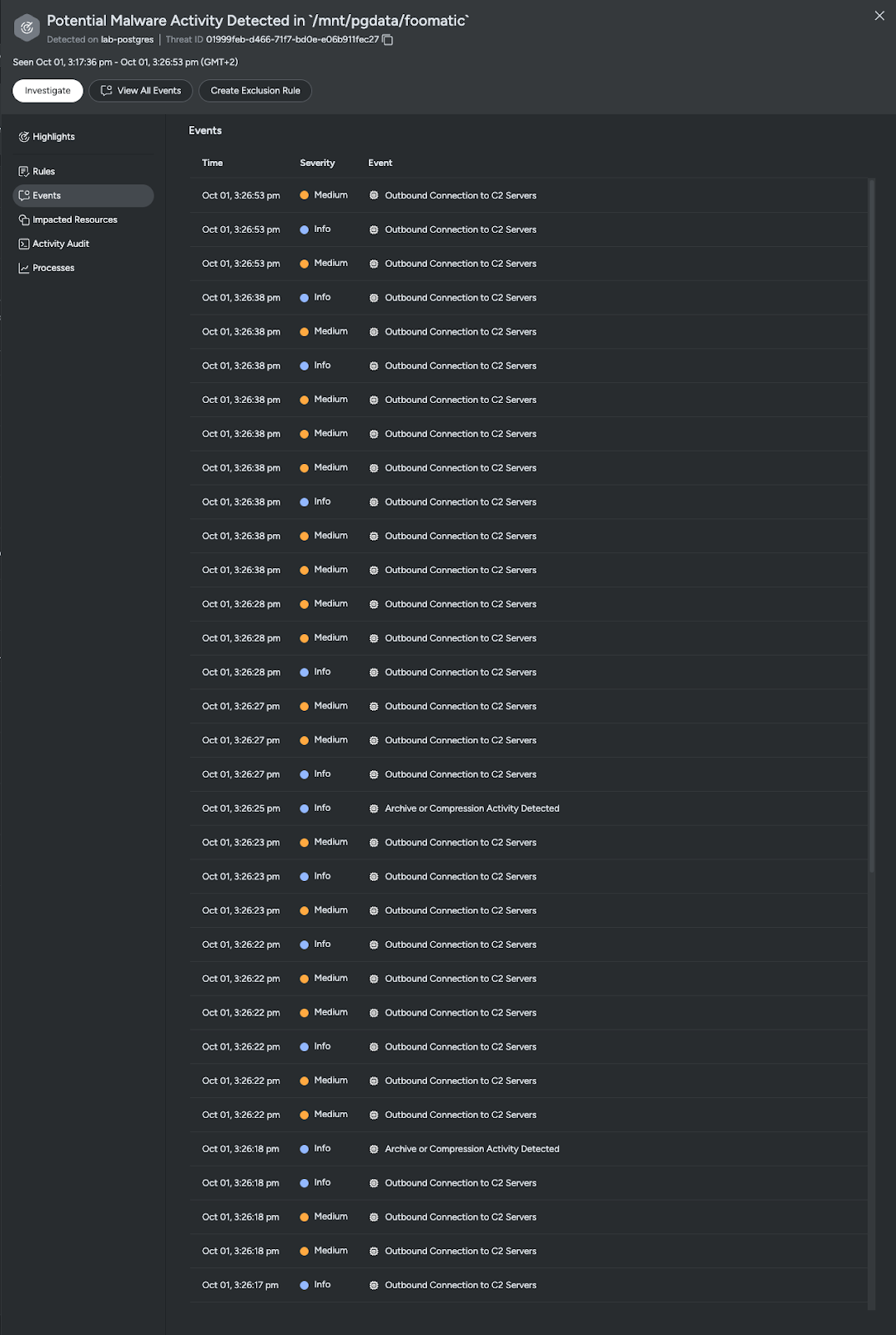
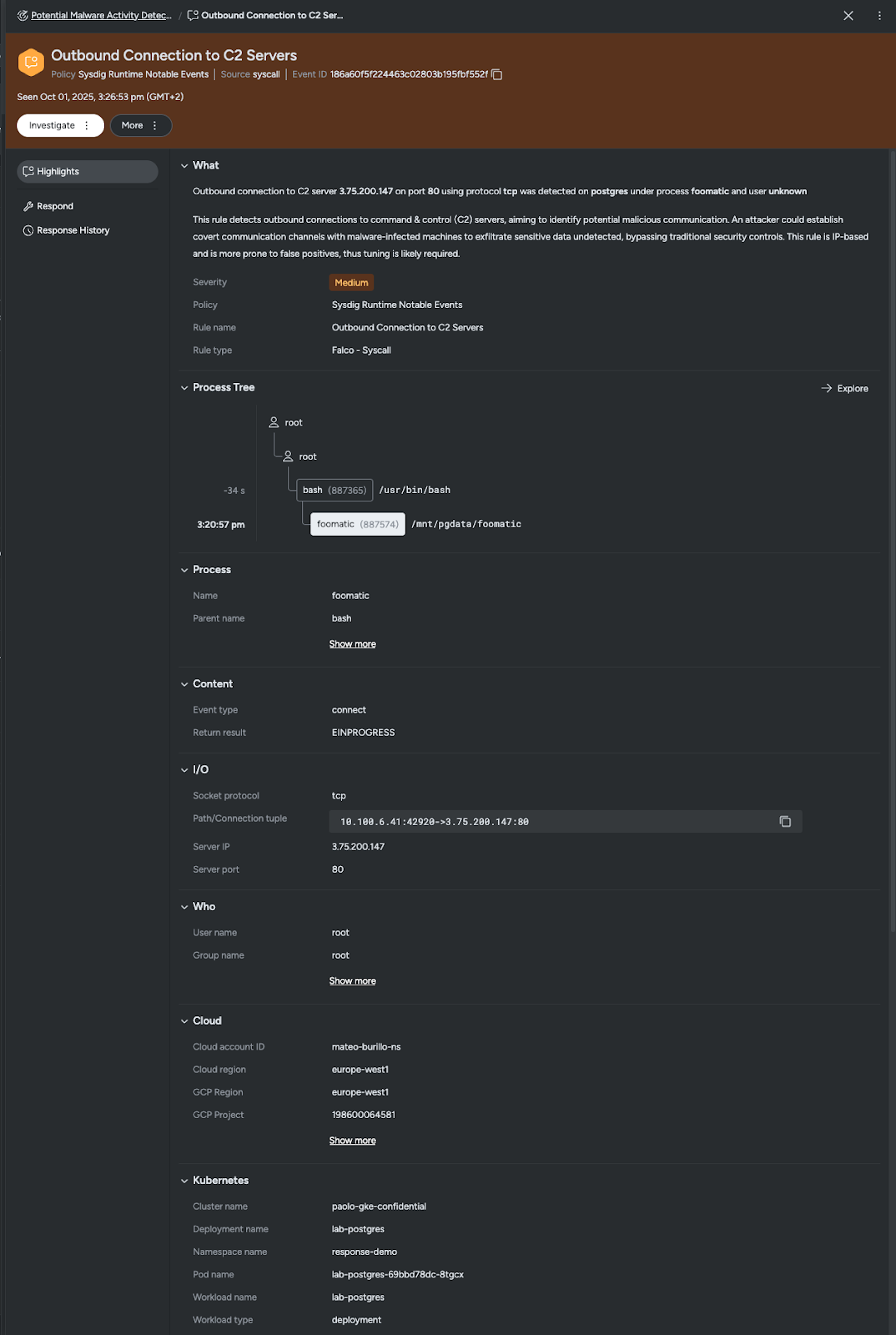
潜在的に危険な組み合わせを評価する
C2接続内のさらなるイベントを確認すると、foomatic が利用された行動と一致する形で postgresql のデプロイメントとの潜在的な関連性が見られます。これは警戒すべき状況です。なぜなら、foomatic はマルウェアとして分類されており、その結果として他のイベントもトリガーされているためです。

観察された情報から、これは無害なアクションでも誤検知でもないと高い確信を持って言えます。
Sysdig による Kubernetes フォレンジックデータの収集
次のワークフローステップは、フォレンジックデータを収集することです。これにより、脅威を修復した後、正確な事後分析を実行するのに十分なアーティファクトが得られます。Kubernetesの新しいレスポンス機能により、わずか数回のクリックでインラインで実行できるアクションが拡充されます。Sysdigは、効果的なデータ収集のために、以下の新機能を備えています。
- ボリュームスナップショット:ボリュームの内容をキャプチャし、後でマウントして分析することで、クリーンアップ作業を可能にします。また、攻撃者に知られることなくボリュームを収集することで、攻撃者が痕跡を削除してフォレンジック分析をさらに困難にすることを防止することもできます。
- ログを取得: アプリケーションから Kubernetes ログにアクセスして、攻撃中の行動をより深く理解するために使用できる認証やその他の動作を表示します。
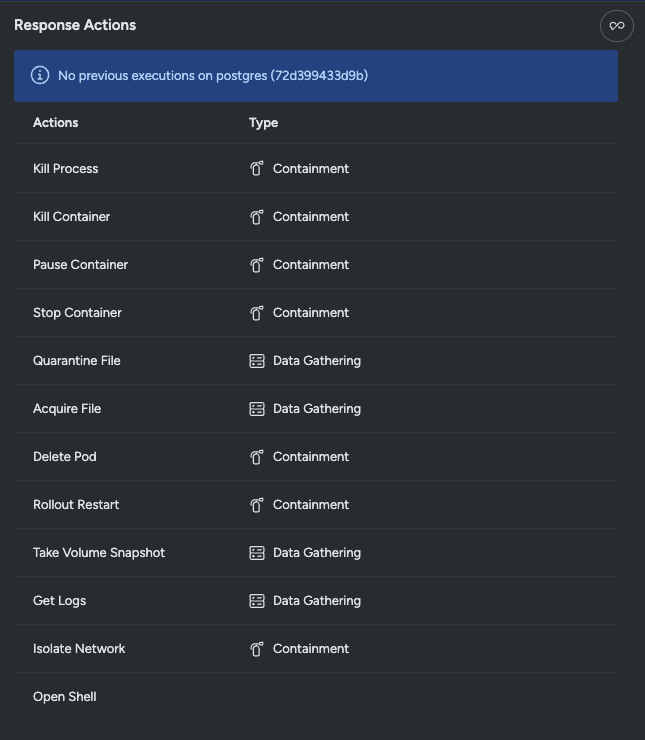
ワークロード内部のマルウェアが実行されたことがわかっているので、被害ワークロードである postgresql からボリュームのスナップショットをすぐに取得する必要があります。
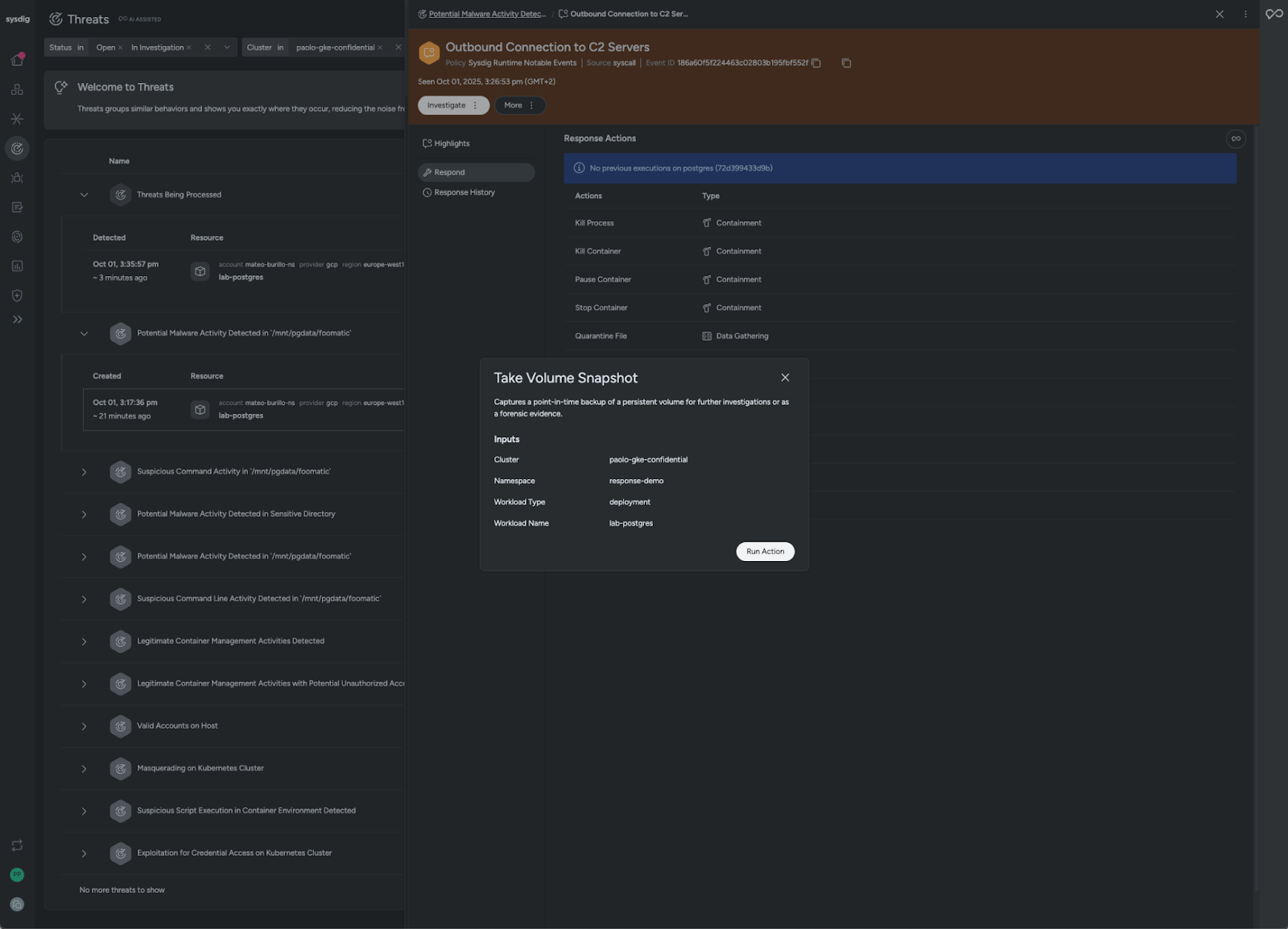
このスナップショットにより、攻撃の再構築、影響の評価、そして再発防止のための防御強化が可能になります。
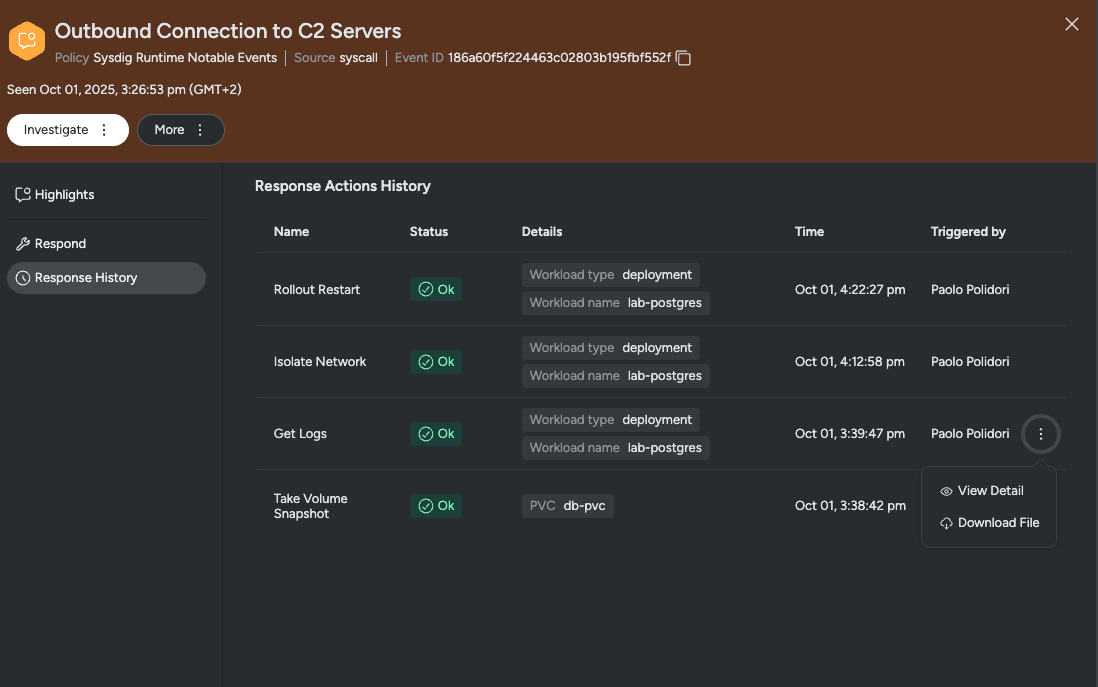
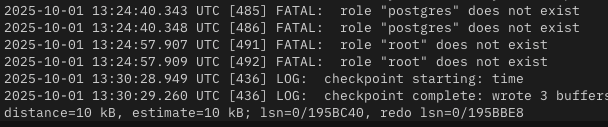
さらに詳しく調査するため、「Get Logs」を使用して、攻撃者がデプロイメントとどのようにやり取りしたかを確認します。この分析中に、複数の認証試行が失敗していることがわかりました。これは、データの窃取が試みられた可能性を示唆しています。
脅威の封じ込めと修復:Sysdig でレスポンスアクションを加速する方法
データが流出したかどうかに関わらず、このような行為は阻止する必要があります。以前は、チームには以下のような広範な専門知識が必要でした。
- Kubernetesの知識。不要な中断のリスクなく、正しい構文で正しいコマンドを実行する
- インフラストラクチャーの知識、つまり、どこに何があるか、クラスターにどのようにアクセスするか
チームには適切な権限があるか、適切な権限を持つ人が関与する必要がありました。
Sysdigで封じ込めを効率化する方法
Sysdig の新しい Kubernetes アクションは、いくつかの強力な封じ込めアクションにより、このプロセスをより高速かつシンプルにします。
- ロールアウトの再起動: ワークロードのポッドをクリーンアップし、通常の操作を中断することなく、新しい状態から強制的に再作成します。
- ポッドの削除:侵害を受けたワークロードを削除します。これは、本番環境に影響を与えずに削除できる、重要度の低いスタンドアロンポッドや、CronJobs のようにワークロードの一部ではないポッドの場合に便利です。また、単一のポッドに対してより正確なワークロードのクリーンアップを実行したい場合にも役立ちます。
- ネットワークを分離: 着信または発信の接続を、広範囲にすべての接続に対してブロックするか、より限定的に特定のポート/IP に対してブロックします。
リアルワールドの封じ込め例
このシナリオでは、データベースがHTTP接続を行うことは想定されていないため、C2 IPへの接続は望ましくない接続であることが確実なので、安全に停止できます。より大胆なアプローチとしては、ポート80への接続をすべてブロックするか、データベースではほとんど必要ないため、送信接続をすべてブロックすることもできます。このシナリオでは、安全かつ保守的なアプローチを採用したかったため、特定のIPとポートへの接続を停止することにしました。
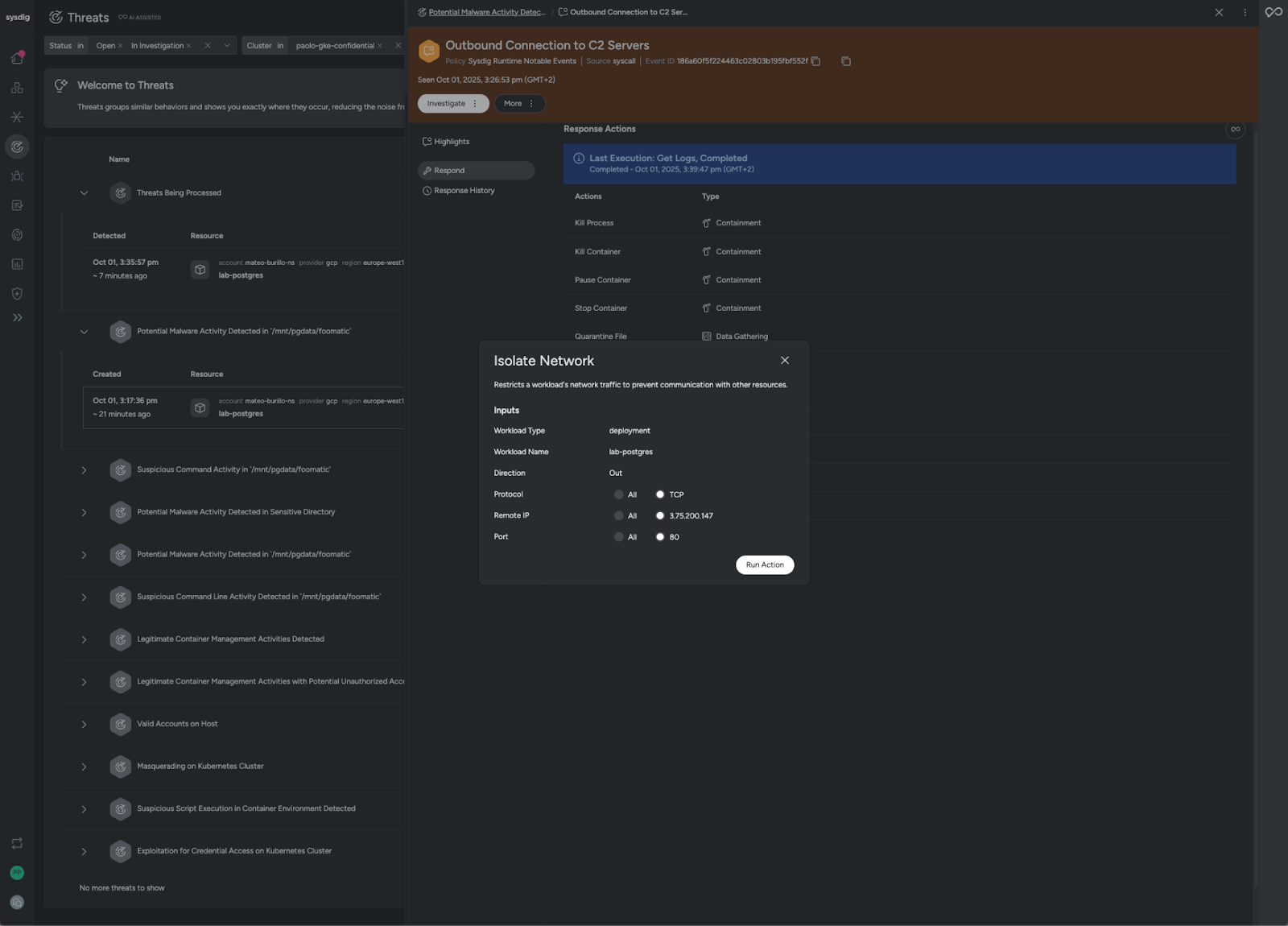
特定のIPとポートへの接続を停止するだけで、脅威を阻止するには十分すぎるはずです。しかし、必要なフォレンジックデータを既に収集しているため、ワークロードを再起動して永続性を排除し、再攻撃のリスクを軽減することができます。これらの新機能を活用することで、検知から解決までの時間を短縮し、セキュリティチームはクラウドネイティブのスピードで、正確かつ自信を持って対応できるようになります。

最後に
Kubernetesの脅威に迅速かつ確実に対応するには、単なる検知にとどまらず、状況に応じた迅速な対応が求められます。ワークロードは絶えず変化し、脅威は一時的な環境に潜んでいるため、従来のインシデント対応アプローチでは対応しきれません。
Sysdig の新しいインライン Kubernetes レスポンス機能は、Kubernetes に関する深い専門知識や面倒なチーム間の依存関係を必要とせずに、チームが脅威を調査、封じ込め、修復するのに役立つ強力でターゲットを絞ったアクションで検知を拡張します。
これらの機能により、状況に応じた即時の対応が可能になり、平均封じ込め時間(MTTC)が大幅に短縮されます。チームは脅威をより迅速に阻止し、被害を最小限に抑え、リスクが拡大する前に軽減することができます。
Sysdig は、ボリュームスナップショット、ログ取得、ネットワーク分離などの自動化ツールを提供することで、セキュリティ チームとプラットフォーム チームが滞在時間を短縮し、攻撃者の持続性を防ぎ、将来の攻撃に対する防御を強化できるようにします。