
この記事では、Prometheus を使って Consul を監視する方法を学びます。また、Prometheusを使用して、Consulのコントロールプレーンのトラブルシューティングを、Consulのドキュメントにあるモニタリングの推奨事項に従って、ゼロから行います。また、最も一般的なConsulの問題をトラブルシュートする方法も紹介します。
KubernetesにConsulをインストールする方法
KubernetesへのConsulのインストールは簡単です。Consulのドキュメントページを見て、その指示に従えばよいのです。Kubernetesにアプリケーションをデプロイする方法としては、Helmチャートの利用が簡単なので、そちらを利用することをおすすめします。
Prometheusのメトリクスを公開するためのConsulの設定方法
Consulは自動的にPrometheus形式のメトリクスをエクスポートします。global.metricsの設定で、これらのオプションを有効にするだけです。Helmを使用している場合は、以下のようにします。--set 'global.metrics.enabled=true' --set 'global.metrics.enableAgentMetrics=true'
また、Consul Server と Client の両方で telemetry.disable_hostname を有効にして、メトリクスにインスタンスの名前が含まれないようにする必要があります。
--set 'server.extraConfig="{"telemetry": {"disable_hostname": true}}"'
--set 'client.extraConfig="{"telemetry": {"disable_hostname": true}}"'PrometheusでConsulを監視する:全体の状況
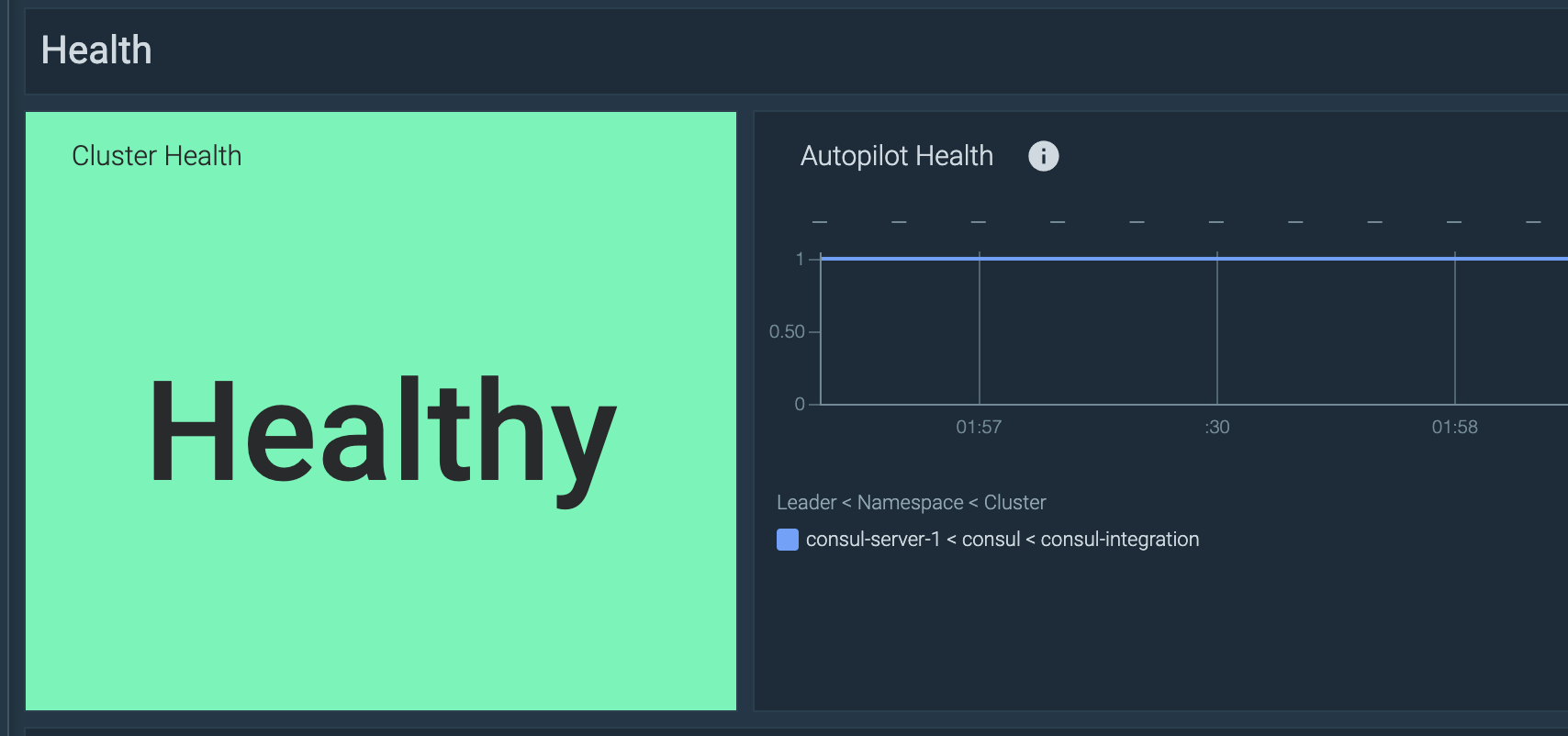
Autopilot
まず、Autopilot メトリクス (consul_autopilot_healthy) を使って、Consul サーバの全体的な健康状態を確認します。すべてのサーバが正常な場合、これは 1 – を返し、そうでない場合は 0 を返します。リーダーでないサーバーはすべてNaNを報告します。この PromQL クエリーをダッシュボードに追加して、Consul サーバーの全体的な状態をチェックすることができます。
min(consul_autopilot_healthy)
これらの閾値を追加することで:
1: “Healthy”0: “Unhealthy”
クラスター内の1つまたは多くのConsulサーバが不健康になったときにアラートを出すには、単純にこのPromQLを使用します:
consul_autopilot_healthy == 0
PromQL をもっと深く知りたいですか?Prometheusがどのようにデータを保存し、どのようにPromQL関数や演算子を使用するかを学ぶために、PromQLの入門ガイドをお読みください。
リーダーシップの変更
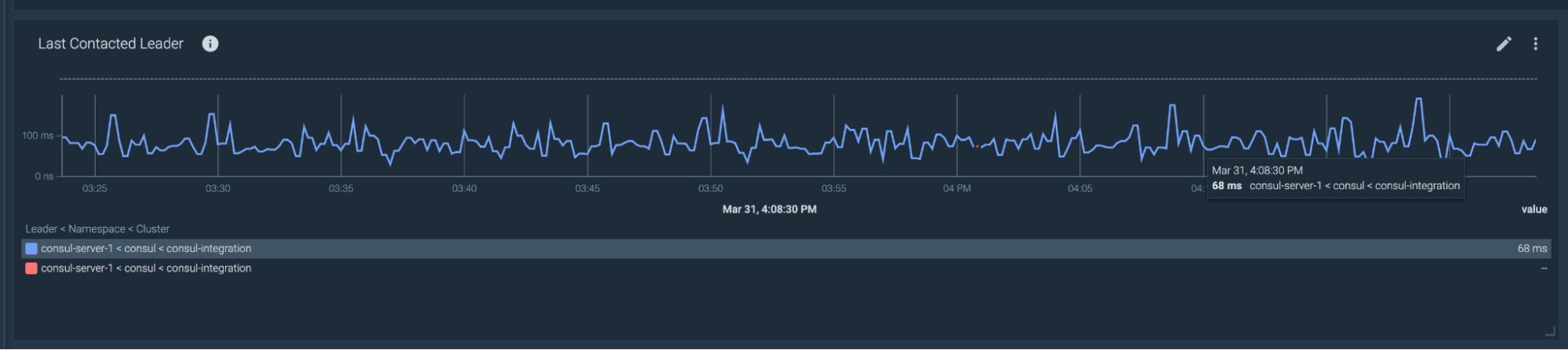
Consulは高可用性を確保するために、コントロールプレーンコントローラのインスタンスを複数配置しています。しかし、そのうちの1つだけがリーダーであり、残りは不測の事態に備えたものです。Consulクラスターは、常に安定したリーダーを持つ必要があります。頻繁に選挙が行われたり、リーダーが変わったりして安定しない場合、Consulサーバー間でネットワークの問題に直面する可能性があります。リーダーの安定性を確認するために、以下のメトリクスを利用することができます:
- consul_raft_leader_lastContact: リーダーリースを確認する際に、リーダーがフォロワーノードにコンタクトしてからどれくらいの時間が経過したかを示す。
- consul_raft_state_leader: リーダーの数
- consul_raft_state_candidate: リーダーに昇格するための候補者の数。このメトリクスが0より大きい数値を返した場合、リーダー交代が進行中であることを意味します。
リーダーシップを発揮するために、いくつかのアラートを作成しましょう。
- リーダーシップのための選挙が多すぎる: sum(rate(consul_raft_state_candidate[1m]))>0
- リーダーシップの交代が多すぎる: sum(rate(consul_raft_state_leader[1m]))>0
- リーダーがフォロワーと接触するまでの時間が長すぎる: consul_raft_leader_lastContact{quantile=”0.9″}>200
最後のクエリーは、quantile=”0.9 “というラベルを含んでおり、パーセンタイル90を使用するためのものです。パーセンタイルp90を使用することで、リーダーとの接触に200ms以上かかっているサンプルのうち、10%を取得することができます。
Consulを監視するためのトラブルシューティング
Consulのトランザクションで長い待ち時間が発生する
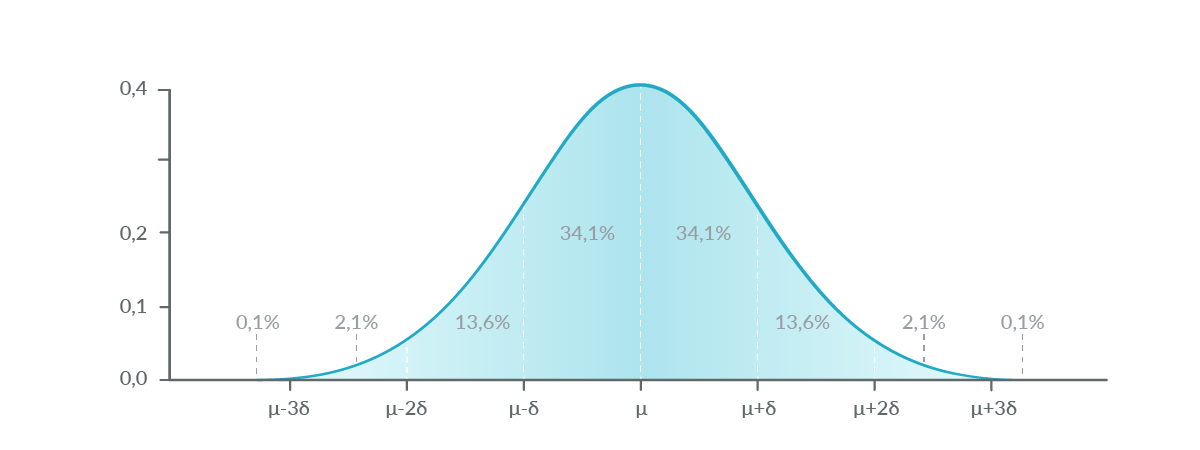
Consulのトランザクション処理における長い待ち時間は、Consulサーバーに予期せぬ負荷がかかっているか、サーバーに問題があることが原因である可能性があります。ネットワークはもともと動的なものなので、異常を時間軸で検出する必要があり、サンプルを固定値と比較するだけではダメなのです。過去1時間(または過去1日、過去5分…)の他の値と比較して、その値が望ましい値なのか、それとも注意が必要な値なのかを判断する必要があります。
異常を検出するには、古い統計学の本をひっぱり出してきて、正規分布について説明している章を見つけるとよいでしょう。正規分布のサンプルの95%は、平均と標準偏差の2倍との間にあります。
PromQLでこれを計算するには、この例のようにavg_over_time関数とstddev_over_time関数を使用します:
avg(rate(consul_kvs_apply_sum[1m]) > 0)>(avg_over_time(rate(consul_kvs_apply_sum[1m]) [1h:1m]) + 2* stddev_over_time(rate(consul_kvs_apply_sum[1m]) [1h:1m]))
トランザクションのレイテンシーが正常でない場合に発生するアラートをいくつか見てみましょう。
キーバリューストアの更新時間異常
Consul KV Storeの更新時間に、前1時間の間にベースラインからの顕著な乖離がありました。avg(rate(consul_kvs_apply_sum[1m]) > 0)>(avg_over_time(rate(consul_kvs_apply_sum[1m]) [1h:1m]) + 2* stddev_over_time(rate(consul_kvs_apply_sum[1m]) [1h:1m]))

これらの例にはPromQLのサブクエリーが含まれていることに注意してください。
トランザクション時間の異常
Consulのトランザクション時間は、前の1時間の間にベースラインから顕著な偏差がありました。avg(rate(consul_txn_apply_sum[1m]) >0)>(avg_over_time(rate(consul_txn_apply_sum[1m])[1h:1m]+2*stddev_over_time(rate(consul_txn_apply_sum[1m]) [1h:1m]))
Consulには、Raftアルゴリズムを使用したConsensusプロトコルがあります。Raftは「コンセンサス」アルゴリズムで、分散した耐障害性のあるクラスターノードの集合上で値の収束を達成する方法です。
トランザクション数の異常
Consulのトランザクションカウント率が、前1時間の間にベースラインから顕著に逸脱していました。avg(rate(consul_raft_apply[1m]) > 0)>(avg_over_time(rate(consul_raft_apply[1m])[1h:1m])+2*stddev_over_time(rate(consul_raft_apply[1m])[1h:1m]))
コミット時間の異常
Consulのコミット時間は、前の1時間でベースラインから顕著な乖離がありました。avg(rate(consul_raft_commitTime_sum[1m]) > 0)>(avg_over_time(rate(consul_raft_commitTime_sum[1m])[1h:1m])+2*stddev_over_time(rate(consul_raft_commitTime_sum[1m]) [1h:1m]))
高いメモリ消費量
メモリ使用量をコントロールし続けることは、Consulサーバーを健全に保つための鍵です。Consulサーバーが利用可能なメモリより多く使用していないことを確認するために、いくつかのアラートを作成してみましょう。100 * sum by(namespace,pod,container)(container_memory_usage_bytes{container!="POD",container!="", namespace="consul"}) / sum by(namespace,pod,container)(kube_pod_container_resource_limits{job!="",resource="memory", namespace="consul"}) > 90
ガベージコレクションのポーズ時間が長い
Consulのガベージコレクターは、ガベージコレクションが完了するまで、すべての実行スレッドをブロックする一時停止イベントを持っています。このプロセスはわずか数ナノ秒しかかかりませんが、Consulのメモリ使用量が多い場合、それがGCイベントをどんどん誘発し、Consulを遅くする可能性があります。2つのアラートを作成してみましょう。GCに1分あたり2秒以上かかる場合は警告アラート、1分あたり5秒以上かかる場合は重大アラートです。
1秒は1000000000ナノ秒であることに注意してください。
ガベージコレクションのstop-the-world一時停止が1分あたり2秒を超えました。
(rate(consul_runtime_gc_pause_ns_sum[1m]) / (1000000000) > 2
ガベージコレクションのstop-the-world一時停止が1分間に5秒以上ありました。
(min(consul_runtime_gc_pause_ns_sum)) / (1000000000) > 5
ネットワーク負荷が高い
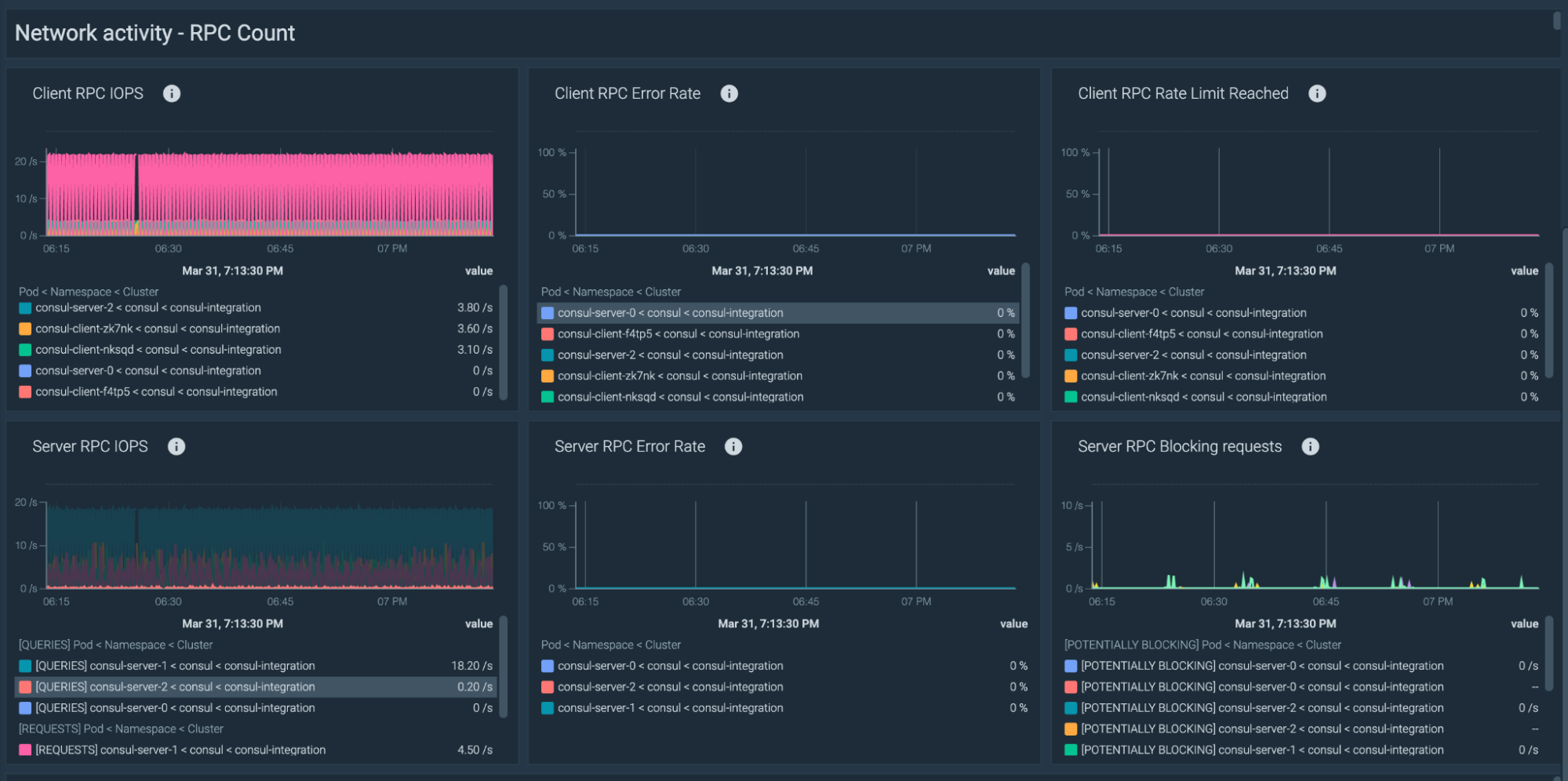
高いRPCカウントは、リクエストがレート制限されていることを意味し、Consulエージェントの設定ミスを示唆します。
今度は、あなたのConsulクライアントがConsulサーバーへのリクエスト送信で速度制限されていないことを確認する番です。以下は、RPC接続に対する推奨アラートです。
クライアントRPCリクエストの異常
ConsulクライアントのRPCリクエストが、過去1時間の間にベースラインから顕著に逸脱していました。avg(rate(consul_client_rpc[1m]) > 0) > (avg_over_time(rate(consul_client_rpc[1m]) [1h:1m])+ 2* stddev_over_time(rate(consul_client_rpc[1m]) [1h:1m]) )
クライアントRPCリクエストのレート制限を超過
ConsulクライアントRPCリクエストの10%以上がレートリミットを超えています。rate(consul_client_rpc_exceeded[1m]) / rate(consul_client_rpc[1m]) > 0.1
クライアントRPCリクエストの失敗
ConsulクライアントRPCリクエストの10%以上が失敗しています。rate(consul_client_rpc_failed[1m]) / rate(consul_client_rpc[1m]) > 0.1
レプリカの問題
リストア時間が長すぎる
この状況では、ディスクまたはリーダーからのリストアは、リーダーが新しいスナップショットを書き、ログを切り捨てるよりも遅いです。再起動後、書き込み速度が低下するまでフォロワーがクラスターに再接続しない可能性があります。consul_raft_leader_oldestLogAge < 2* max(consul_raft_fsm_lastRestoreDuration)
Consul Enterpriseをお使いですか?ライセンスが最新であることを確認してください!
この簡単なPromQLクエリーを使って、Consul Enterpriseのライセンスが30日以内に期限切れになるかどうかを確認することができます。consul_system_licenseExpiration / 24 < 30
PrometheusでConsulを監視するダッシュボード
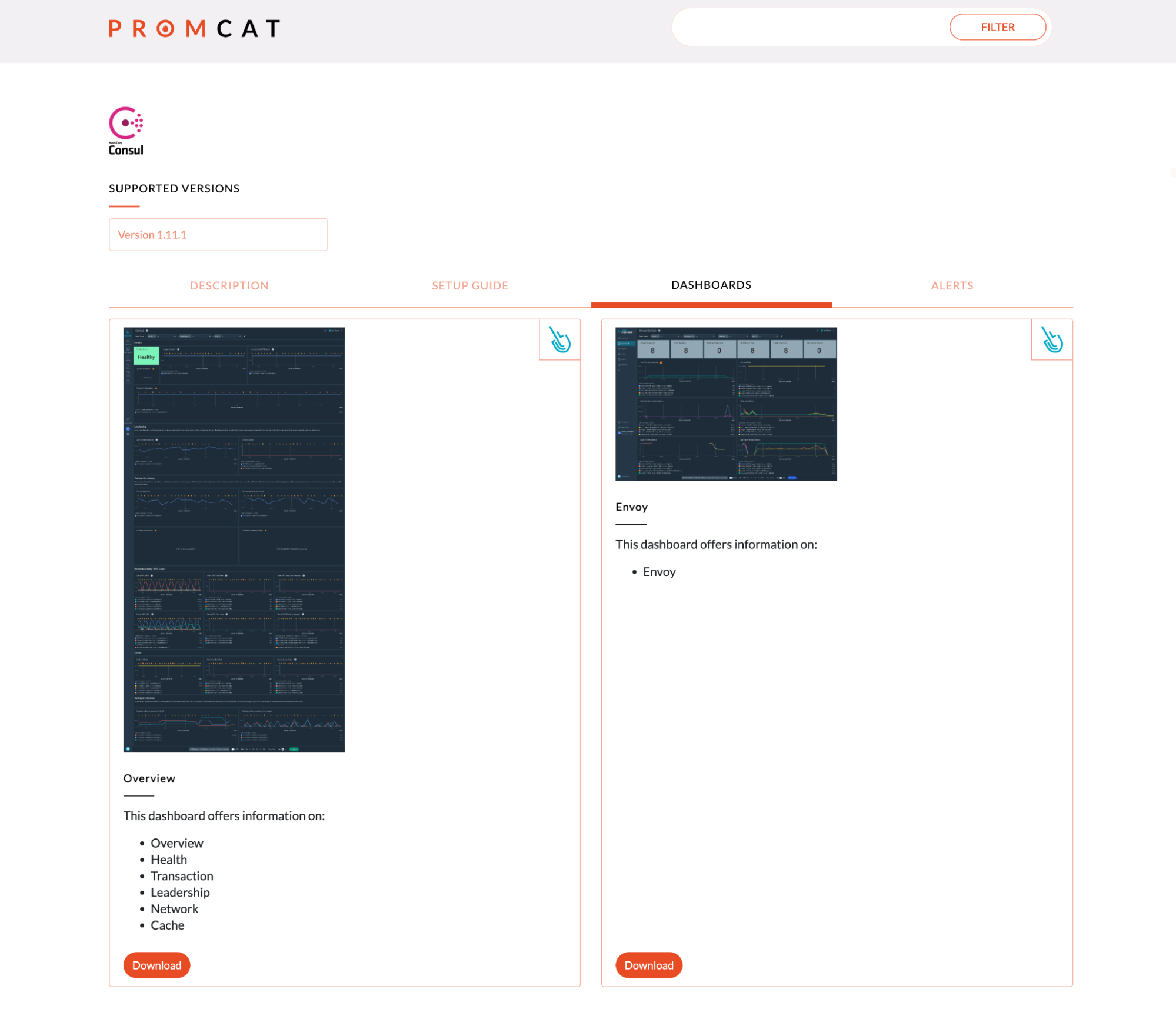
オープンソースのダッシュボードは、Consulクラスターの概要を監視するためにすでにセットアップされていますので、お見逃しなく!また、次のようなダッシュボードもあります:
- Health
- Transaction
- Leadership
- Network
- Cache
この記事では、PrometheusでConsulコントロールプレーンを監視する方法と、Consulの最も一般的な問題のトラブルシューティングに役立つ推奨アラートについて学びました。
このインテグレーションを試してみたいですか?
Sysdig Monitorの無料トライアルに登録し、マネージドPrometheusサービスの利用を開始しましょう。Prometheusインテグレーションを試すか、Prometheus Remote Writeでメトリクスを数分で送信してください。