
このブログでは、KubernetesのCrashLoopBackOffイベントを視覚化し、アラートを発し、デバッグ/トラブルシューティングする方法についてお話します。ベテランのKubernetesユーザなら誰でも知っているように、Kubernetes CrashLoopBackOffイベントは日常茶飯事です。誰もが一度は経験したことがあると思いますが、通常はコンテナ内のトラブルシューティングツールにアクセスできず、頭を悩ませることになります。
KubernetesのCrashLoopBackOffとは?どのような意味なのか?
CrashloopBackOffとは、ポッドが起動して、クラッシュして、また起動して、またクラッシュして、という状態です。PodSpecには、ポッド内のすべてのコンテナに適用される、Always、OnFailure、Neverの可能な値を持つrestartPolicyフィールドがあります。デフォルト値は Always で、restartPolicy は、同一ノード上の kubelet によるコンテナの再起動のみを参照します(そのため、ポッドが別のノードで再スケジュールされると、再起動カウントはリセットされます)。kubeletによって再起動された失敗したコンテナは、5分を上限とする指数関数的なバックオフ遅延(10s、20s、40s …)で再起動され、正常に実行された10分後にリセットされます。以下は、restartPolicyフィールドを持つPodSpecの一例です。
apiVersion: v1
kind: Pod
metadata:
name: dummy-pod
spec:
containers:
- name: dummy-pod
image: ubuntu
restartPolicy: AlwaysCrashLoopBackOffはなぜ起こるのでしょうか?
Googleで検索してみると、クラッシュループイベントはさまざまな理由で発生することがわかります(しかも頻繁に発生します)。ここでは、なぜクラッシュループが発生するのかについて、代表的な原因を挙げてみます。- コンテナ内のアプリケーションがクラッシュし続けている
- ポッドやコンテナのパラメータの設定が間違っている
- Kubernetesのデプロイ時にエラーが発生した
クラスター内にCrashLoopBackOffがあるかどうかを確認するにはどうすればよいですか?
通常のkubectl get podsコマンドを実行すると、現在CrashLoopBackOffになっているポッドの状態を確認することができます。kubectl get pods --namespace nginx-crashloop
NAME READY STATUS RESTARTS AGE
flask-7996469c47-d7zl2 1/1 Running 1 77d
flask-7996469c47-tdr2n 1/1 Running 0 77d
nginx-5796d5bc7c-2jdr5 0/1 CrashLoopBackOff 2 1m
nginx-5796d5bc7c-xsl6p 0/1 CrashLoopBackOff 2 1m実際、Errorステータスのポッドがあれば、おそらくすぐにCrashLoopBackOffになるでしょう:
kubectl get pods --namespace nginx-crashloop
NAME READY STATUS RESTARTS AGE
flask-7996469c47-d7zl2 1/1 Running 1 77d
flask-7996469c47-tdr2n 1/1 Running 0 77d
nginx-5796d5bc7c-2jdr5 0/1 Error 0 24s
nginx-5796d5bc7c-xsl6p 0/1 Error 0 24skubectl describe podを実行すると、そのポッドの詳細な情報が得られます:
kubectl describe pod nginx-5796d5bc7c-xsl6p --namespace nginx-crashloop
Name: nginx-5796d5bc7c-xsl6p
Namespace: nginx-crashloop
Node: ip-10-0-9-132.us-east-2.compute.internal/10.0.9.132
Start Time: Tue, 27 Mar 2018 19:11:05 +0200
Labels: app=nginx-crashloop
name=nginx
pod-template-hash=1352816737
role=app
Annotations: kubernetes.io/created-by={"kind":"SerializedReference","apiVersion":"v1","reference":{"kind":"ReplicaSet","namespace":"nginx-crashloop","name":"nginx-5796d5bc7c","uid":"fb9e9518-f542-11e7-a8f2-065cff0...
Status: Running
IP: 10.47.0.15
Controlled By: ReplicaSet/nginx-5796d5bc7c
Containers:
nginx:
Container ID: docker://513cab3de8be8754d054a4eff45e291d33b63e11b2143d0ff782dccc286ba05e
Image: nginx
Image ID: docker-pullable://nginx@sha256:c4ee0ecb376636258447e1d8effb56c09c75fe7acf756bf7c13efadf38aa0aca
Port: <none>
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
Started: Tue, 27 Mar 2018 19:13:15 +0200
Finished: Tue, 27 Mar 2018 19:13:16 +0200
Ready: False
Restart Count: 4
Environment: <none>
Mounts:
/etc/nginx/nginx.conf from config (rw)
/var/run/secrets/kubernetes.io/serviceaccount from default-token-chcxn (ro)
Conditions:
Type Status
Initialized True
Ready False
PodScheduled True
Volumes:
config:
Type: ConfigMap (a volume populated by a ConfigMap)
Name: nginxconfig
Optional: false
default-token-chcxn:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-chcxn
Optional: false
QoS Class: BestEffort
Node-Selectors: nginxcrash=allowed
Tolerations: node.alpha.kubernetes.io/notReady:NoExecute for 300s
node.alpha.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m default-scheduler Successfully assigned nginx-5796d5bc7c-xsl6p to ip-10-0-9-132.us-east-2.compute.internal
Normal SuccessfulMountVolume 2m kubelet, ip-10-0-9-132.us-east-2.compute.internal MountVolume.SetUp succeeded for volume "config"
Normal SuccessfulMountVolume 2m kubelet, ip-10-0-9-132.us-east-2.compute.internal MountVolume.SetUp succeeded for volume "default-token-chcxn"
Normal Pulled 1m (x3 over 2m) kubelet, ip-10-0-9-132.us-east-2.compute.internal Successfully pulled image "nginx"
Normal Created 1m (x3 over 2m) kubelet, ip-10-0-9-132.us-east-2.compute.internal Created container
Normal Started 1m (x3 over 2m) kubelet, ip-10-0-9-132.us-east-2.compute.internal Started container
Warning BackOff 1m (x5 over 1m) kubelet, ip-10-0-9-132.us-east-2.compute.internal Back-off restarting failed container
Warning FailedSync 1m (x5 over 1m) kubelet, ip-10-0-9-132.us-east-2.compute.internal Error syncing pod
Normal Pulling 57s (x4 over 2m) kubelet, ip-10-0-9-132.us-east-2.compute.internal pulling image "nginx"Sysdig MonitorでKubernetesのイベントを可視化する
CrashLoopBackOffイベントは、Sysdig Monitorの「Event」で確認することができます。Sysdig Monitorは、KubernetesとDockerのイベントをネイティブに取り込み、ユーザーがアラートを出したり、システムパフォーマンスのチャートに重ねて表示することができます。Sysdigに取り込まれたKubernetesのイベント
kubernetes:
node:
- TerminatedAllPods # Terminated All Pods (information)
- RegisteredNode # Node Registered (information)*
- RemovingNode # Removing Node (information)*
- DeletingNode # Deleting Node (information)*
- DeletingAllPods # Deleting All Pods (information)
- TerminatingEvictedPod # Terminating Evicted Pod (information)*
- NodeReady # Node Ready (information)*
- NodeNotReady # Node not Ready (information)*
- NodeSchedulable # Node is Schedulable (information)*
- NodeNotSchedulable # Node is not Schedulable (information)*
- CIDRNotAvailable # CIDR not Available (information)*
- CIDRAssignmentFailed # CIDR Assignment Failed (information)*
- Starting # Starting Kubelet (information)*
- KubeletSetupFailed # Kubelet Setup Failed (warning)*
- FailedMount # Volume Mount Failed (warning)*
- NodeSelectorMismatching # Node Selector Mismatch (warning)*
- InsufficientFreeCPU # Insufficient Free CPU (warning)*
- InsufficientFreeMemory # Insufficient Free Mem (warning)*
- OutOfDisk # Out of Disk (information)*
- HostNetworkNotSupported # Host Ntw not Supported (warning)*
- NilShaper # Undefined Shaper (warning)*
- Rebooted # Node Rebooted (warning)*
- NodeHasSufficientDisk # Node Has Sufficient Disk (information)*
- NodeOutOfDisk # Node Out of Disk Space (information)*
- InvalidDiskCapacity # Invalid Disk Capacity (warning)*
- FreeDiskSpaceFailed # Free Disk Space Failed (warning)*
pod:
- Pulling # Pulling Container Image (information)
- Pulled # Ctr Img Pulled (information)
- Failed # Ctr Img Pull/Create/Start Fail (warning)*
- InspectFailed # Ctr Img Inspect Failed (warning)*
- ErrImageNeverPull # Ctr Img NeverPull Policy Violate (warning)*
- BackOff # Back Off Ctr Start, Image Pull (warning)
- Created # Container Created (information)
- Started # Container Started (information)
- Killing # Killing Container (information)*
- Unhealthy # Container Unhealthy (warning)
- FailedSync # Pod Sync Failed (warning)
- FailedValidation # Failed Pod Config Validation (warning)
- OutOfDisk # Out of Disk (information)*
- HostPortConflict # Host/Port Conflict (warning)*
replicationController:
- SuccessfulCreate # Pod Created (information)*
- FailedCreate # Pod Create Failed (warning)*
- SuccessfulDelete # Pod Deleted (information)*
- FailedDelete # Pod Delete Failed (warning)*カスタムイベントは、Sysdig MonitorのイベントAPIに送信して、相関やアラートにも利用できます。例えば、Jenkinsから新しいデプロイメントを実行したとき、壊れたバージョンのロールバックを行ったとき、クラウドインフラストラクチャーが変更されたときなどに、カスタムイベントを送信することができます。
Sysdig Monitorのカスタムイベントセクションでは、分散したKubernetes環境で発生したすべてのイベントのフィードを見ることができます。ここでは、タイムスタンプ、イベント名、説明、重大度、その他の詳細を見ることができます。
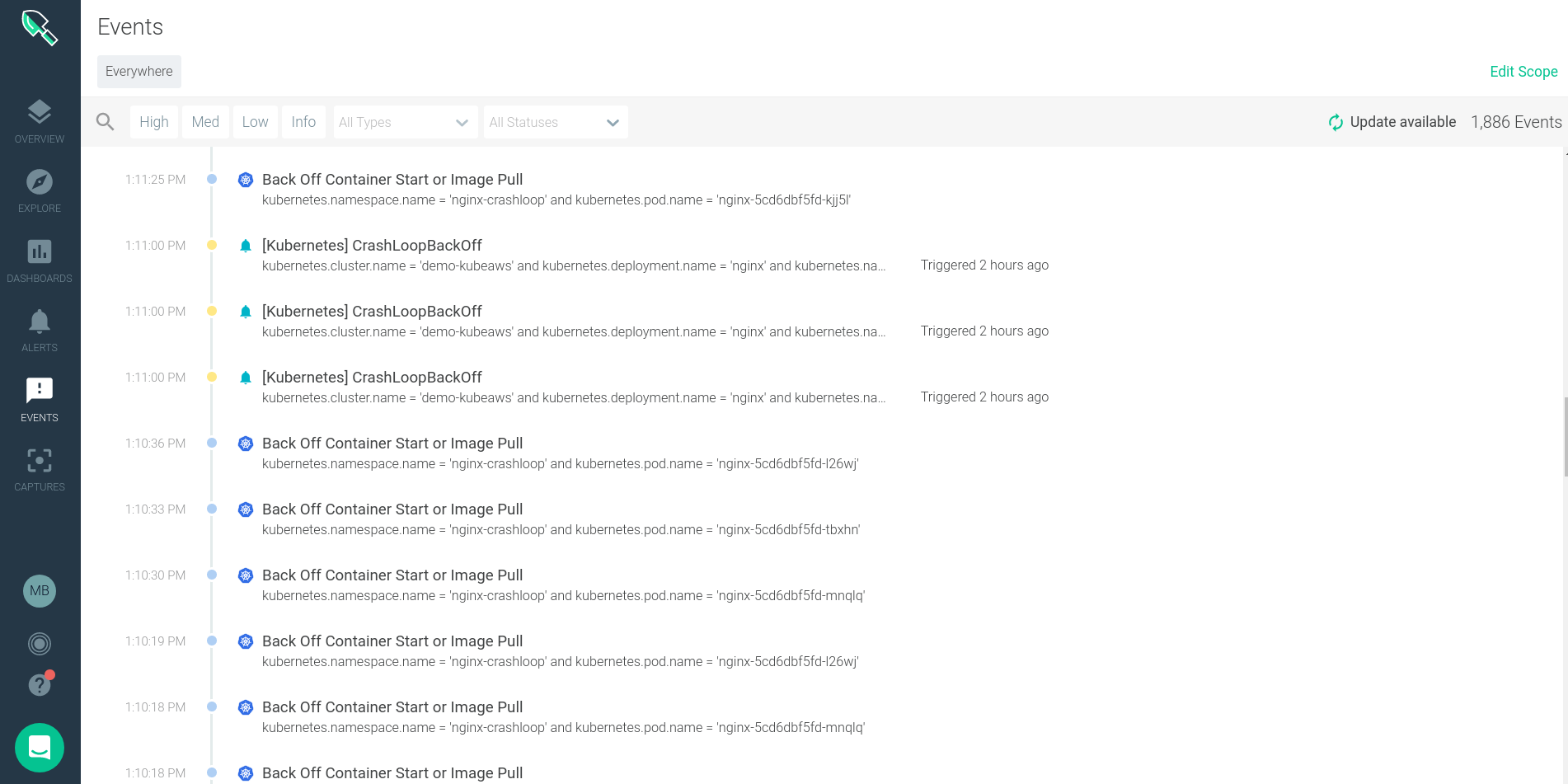
個々のイベントをクリックすると、そのイベントの詳細が表示され、インフラのどこで発生したのか、より詳細な情報が表示されます。
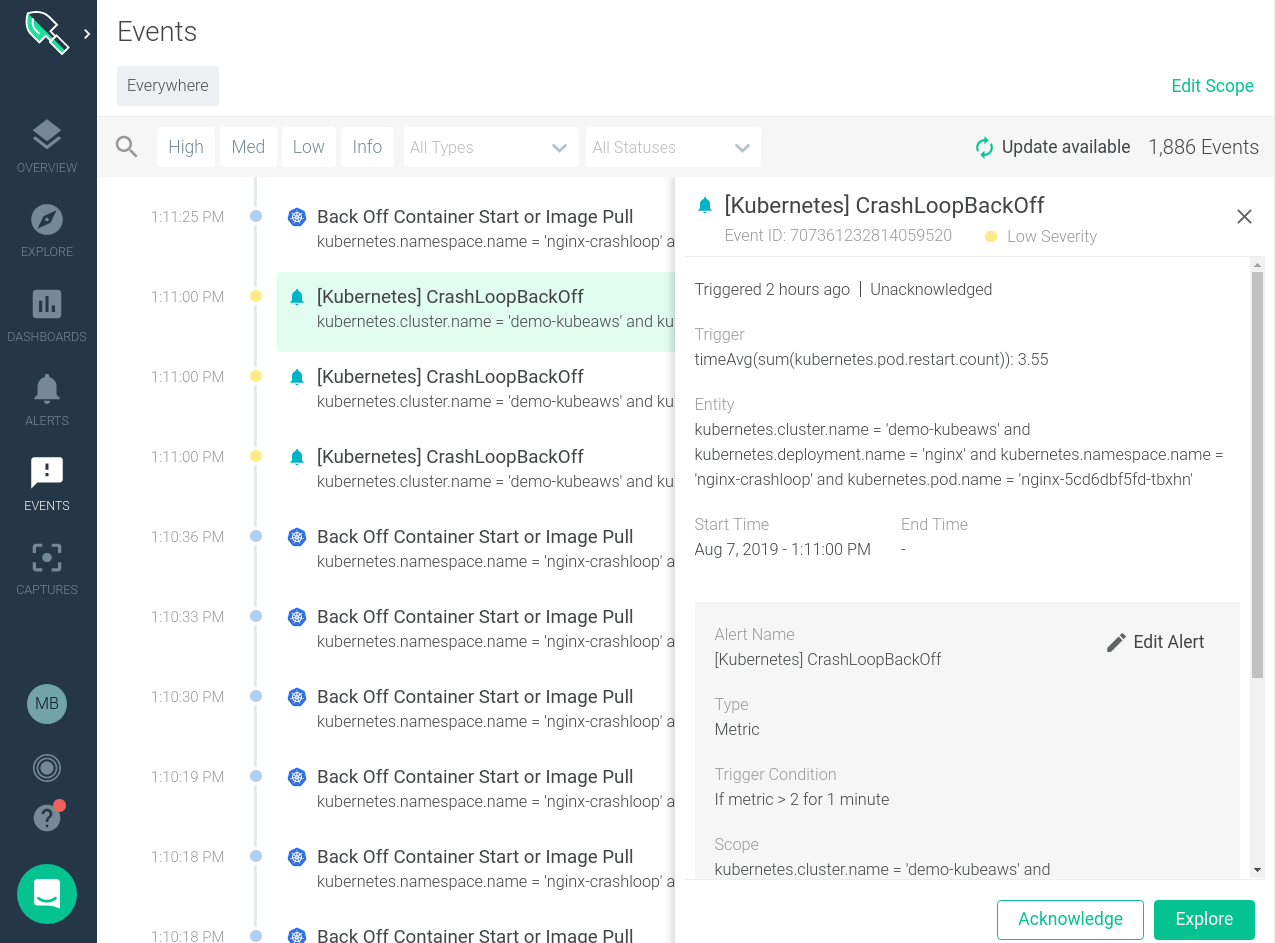
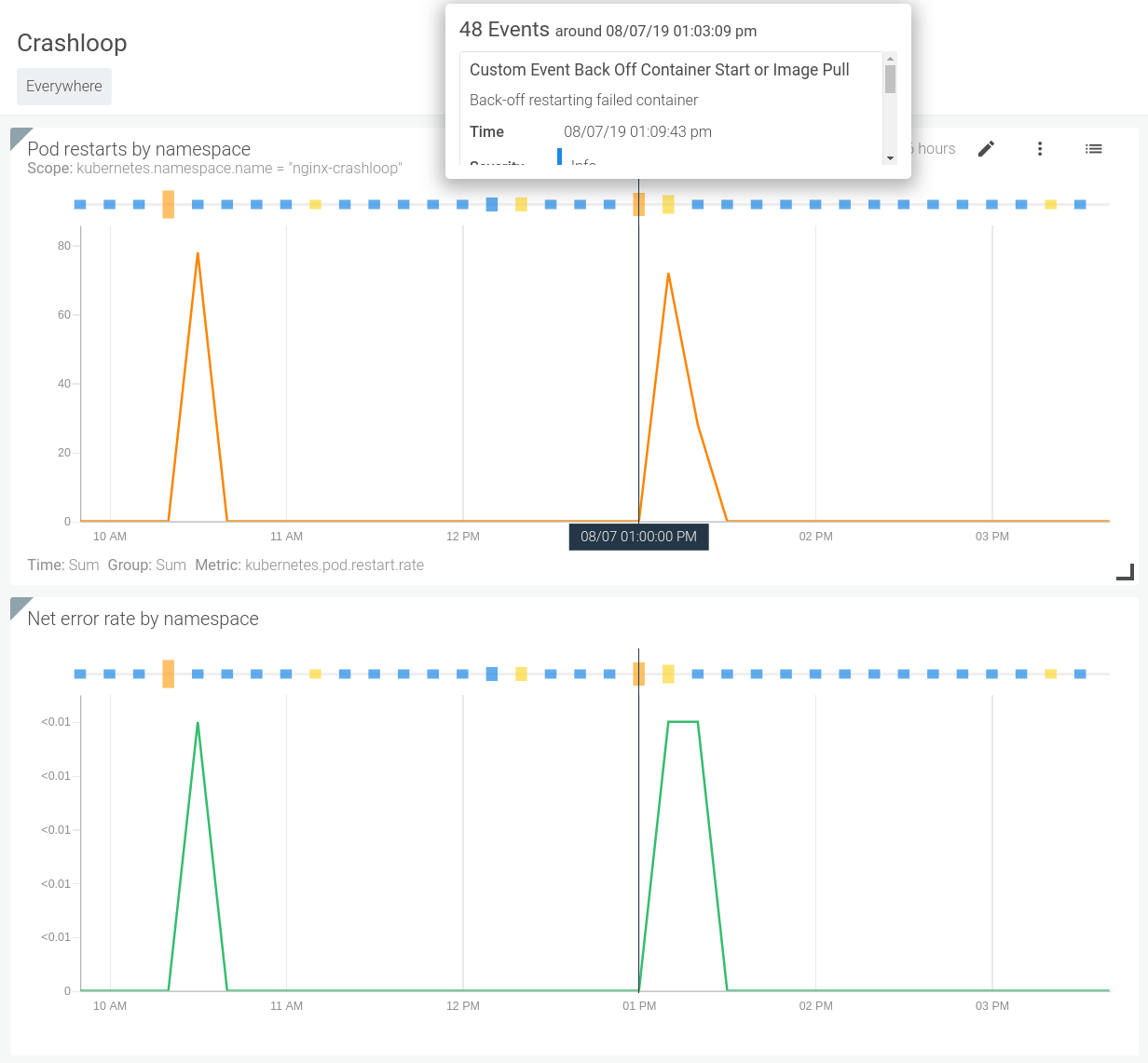
また、これらのイベントをシステムの動作と相関させることもできます。下の画像を見ると、特定のバックオフイベントがいつ発生し、それがシステムのパフォーマンスに変化をもたらしたかどうかがすぐにわかります。
KubernetesのCrashLoopBackOffに関するアラートの出し方
アラートを出すためには、kubernetes.pod.restart.rateというメトリクスを使います。これにより、ポッドの再起動の傾向を時系列で分析し、異常があった場合は速やかにチームに通知することができます。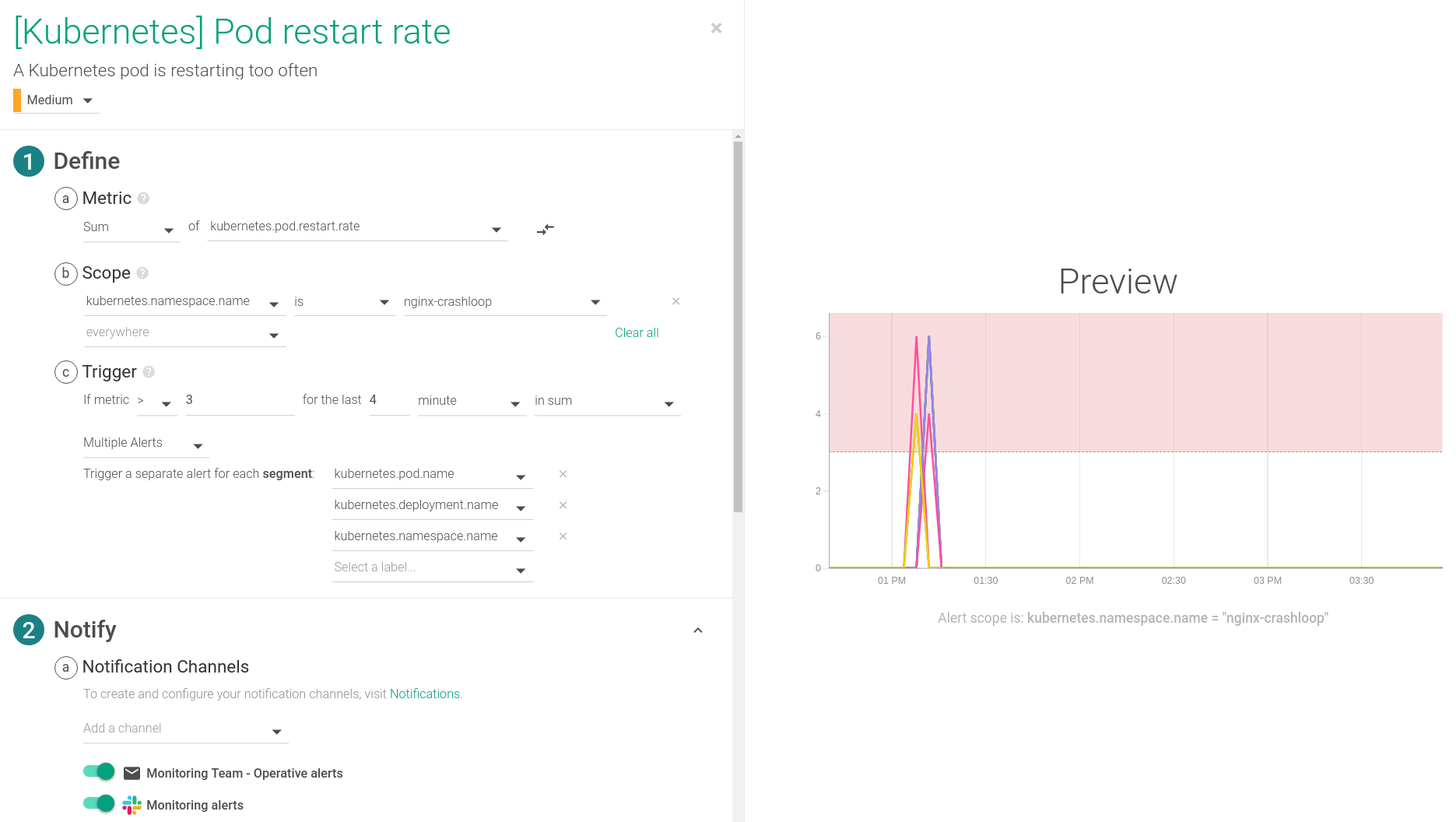
お使いの環境の遅延に応じて、時間設定を切り替えてください。このアラートは、いずれかのポッドが4分間に3回以上再起動した場合に作動するように設定されており、通常はCrashLoopBackOffイベントの指標となります。このアラートは、Kubernetes環境のデフォルトアラートの1つです。
Sysdig Captureを有効にすることも、CrashLoopBackOffのトラブルシューティングには非常に重要です。Sysdigキャプチャーとは、アラートが発生した時点でシステム上で起こったことをすべて記録したものです。キャプチャーはSysdig Inspectで開くことができ、フォレンジック分析やトラブルシューティングのための詳細な分析を行うことができるため、チームはインシデントへの対応と回復を迅速に行うことができます。
同様に、Sysdigが収集したイベントに基づいてCrashLoopBackOffアラートを設定することもできます。
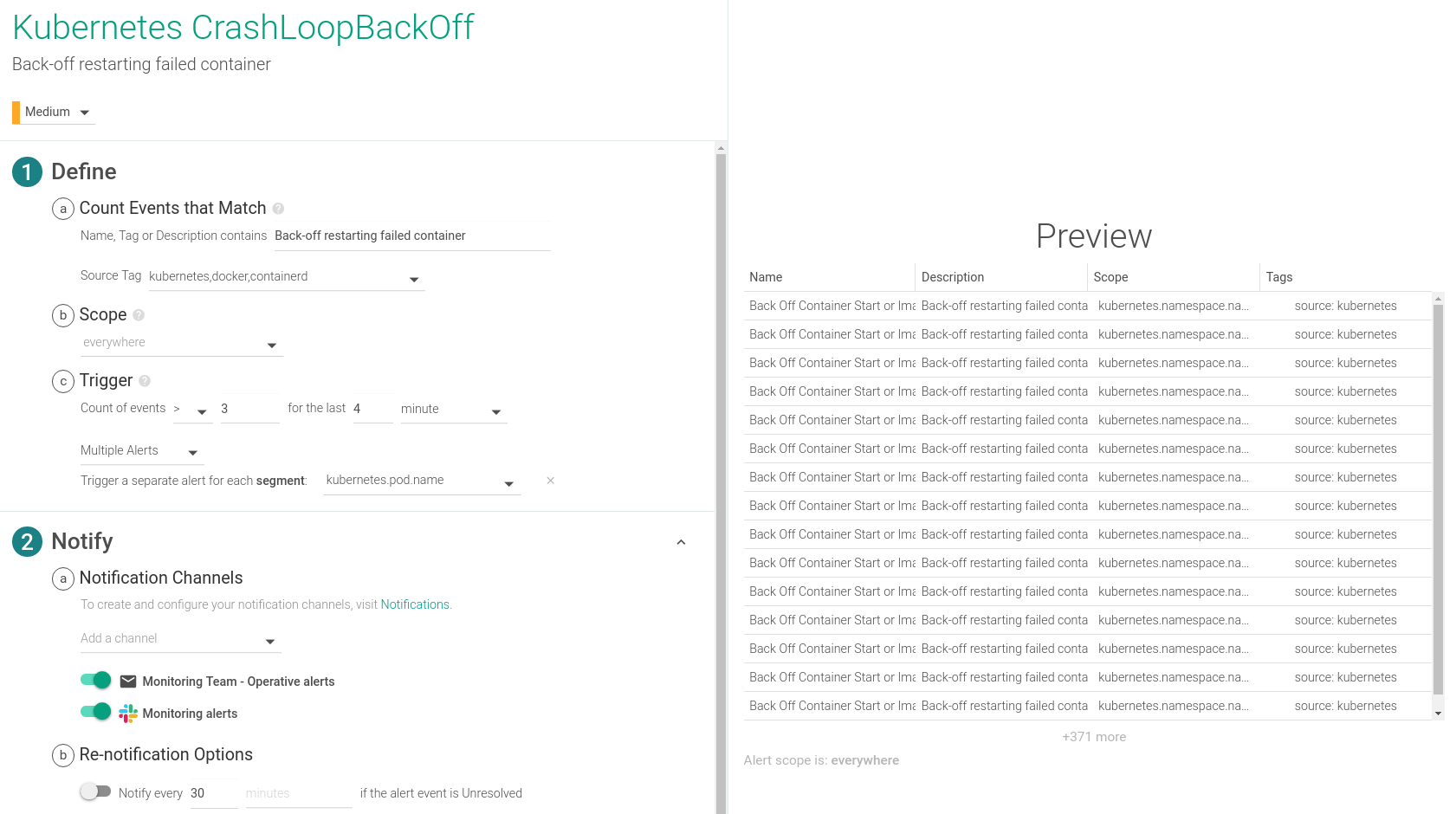
KubernetesにおけるCrashLoopBackOffのデバッグ/トラブルシューティング/修復方法
CrashLoopBackOffが発生していると思われるホストを選択してキャプチャーを開始することで、任意のタイミングでSysdigのキャプチャーを手動で行うことができます。また、Sysdigのオープンソースがホストにインストールされていれば、手動でキャプチャーすることもできます。しかし、ここではSysdig Monitorの機能を利用して、アラート(この場合はCrashLoopBackOffのアラート)への対応として自動的にキャプチャーファイルを取得します。トラブルシューティングの最初のアクションアイテムは、ホスト上でイベントが発生した時点で記録されたキャプチャーファイルを開くことです。

Sysdig Monitorでキャプチャーを開くと、Sysdig Inspectのブラウザーウィンドウが表示されます。Inspectでは、より効率的な相関分析やトラブルシューティング分析のために、GUIでシステムコール分析を行うことができます。Sysdig Inspectは、当社のコンテナランタイムセキュリティ製品であるSysdig Secureで、事後分析やフォレンジックにも利用されます。
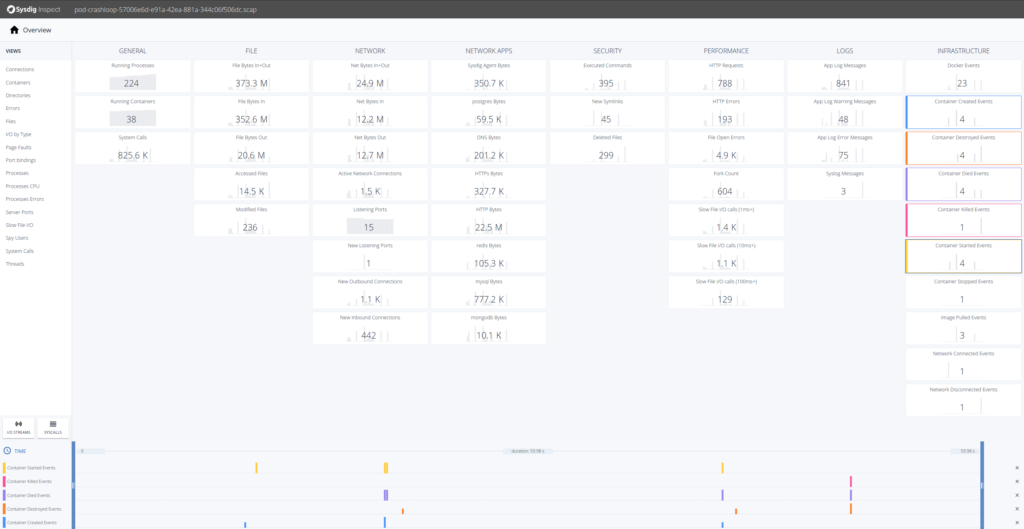
このイベントのトラブルシューティングには、Sysdig Inspectのインフラストラクチャー・カラムで発生しているすべての事象を確認します。「Docker Events」のタイルを選択すると、それらのイベントが下部のタイムラインに表示されます。
ここで何が起こっているのか、トラブルシューティングをしてみましょう。最初のステップとしては、「Container Died Events」をドリルダウンするのが良いでしょう。
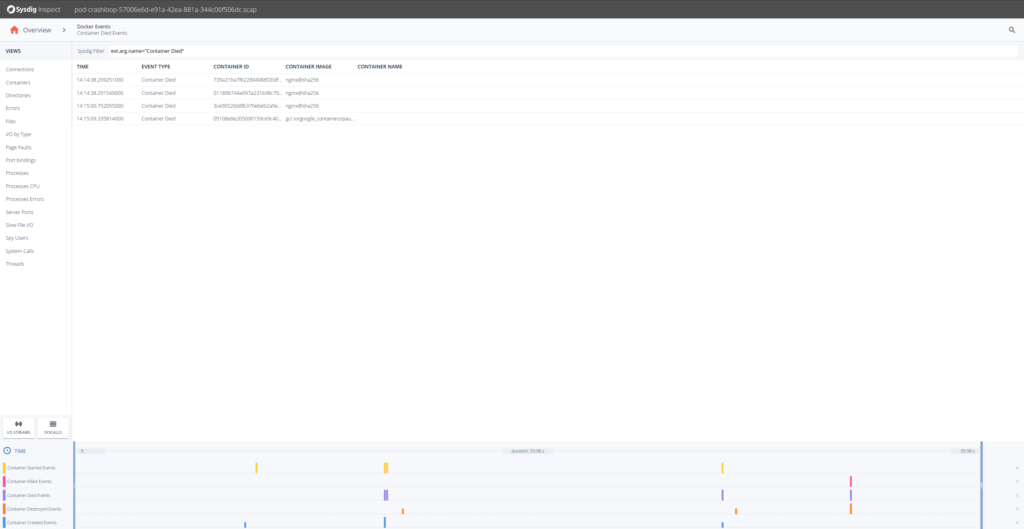
どうやら、Nginxコンテナに問題が発生しているようです。タイムスタンプを見ると、コンテナが作成されてからすぐに死んでいます。どれかのNginxコンテナを掘り下げて、左側にあるProcesssを選択してみましょう。
Nginxコンテナは「nginx」という1つのプロセスしか実行しないことがわかっているので、「Processs」から「proc.name = nginx.CrashLoopBackOff」でフィルタリングします。
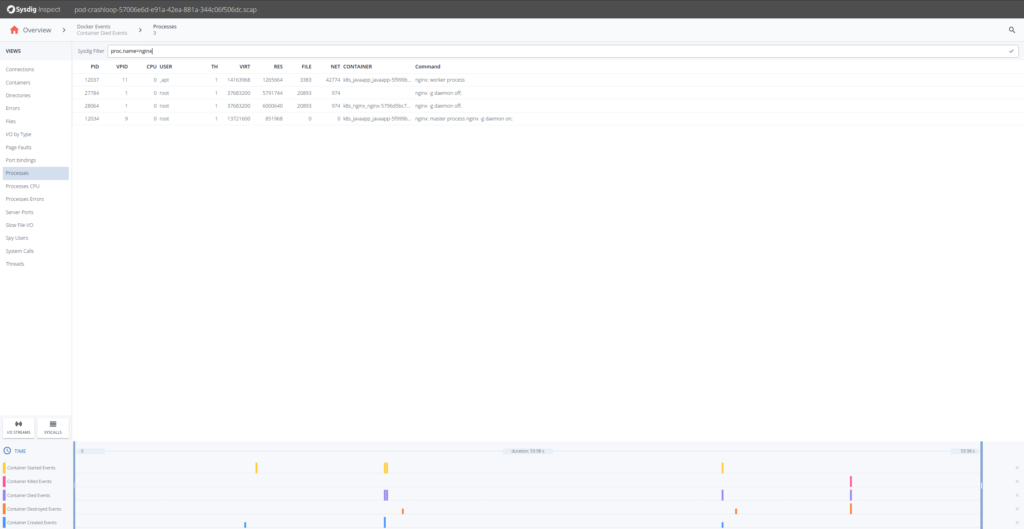
Sysdig Inspectのフィルターは、Sysdigのオープンソース・シンタックスを使用しており、アクティビティを特定するのに利用できます。
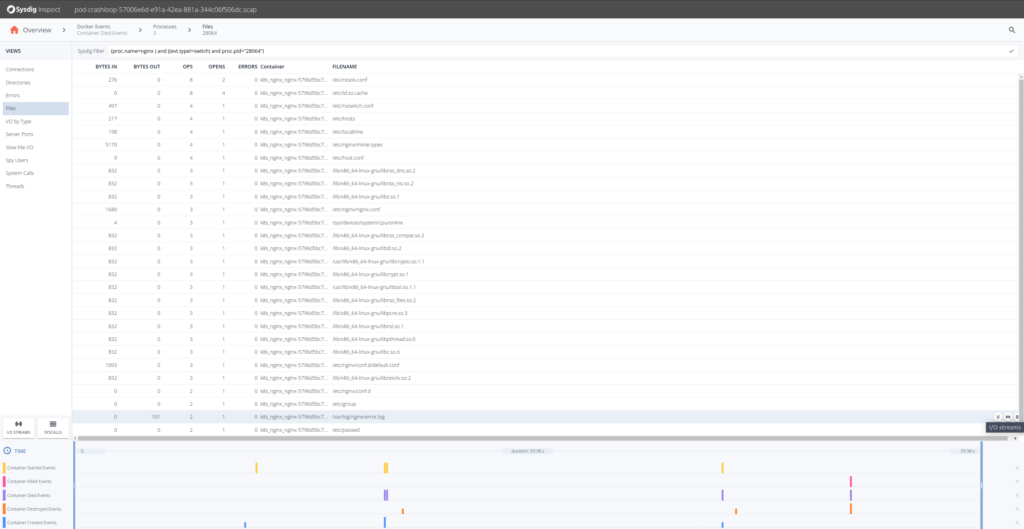
「Errors」セクションをクリックしてみますが、システムコールの失敗など、重要なものは何も表示されません。「Files」セクションに移動して、ファイルシステムのアクティビティを調べてみましょう。そこにはerror.logファイルがあり、おそらく何らかの情報が得られるでしょう。I/O Streamsアイコンをクリックすると、ファイルシステムのI/Oアクティビティを確認できます。
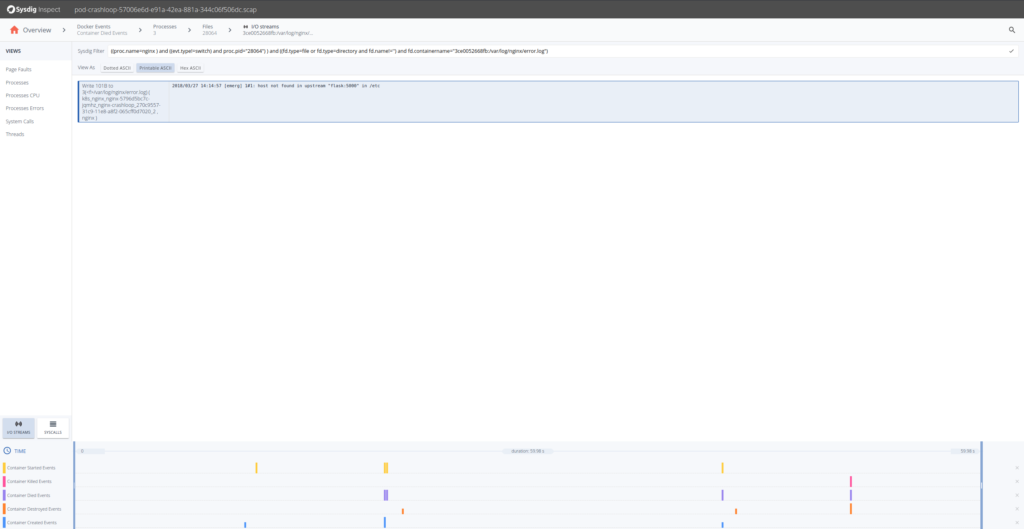
コンテナが停止するまでのerror.logファイルの内容から、Nginxが設定されたアップストリームサーバを解決できなかったことがわかります。Nginxが失敗した理由はわかりましたが、そのポッドに設定されていたDNSサーバーを確認することはできないのでしょうか?もちろん、resolv.confのストリームを取得して戻ってください。
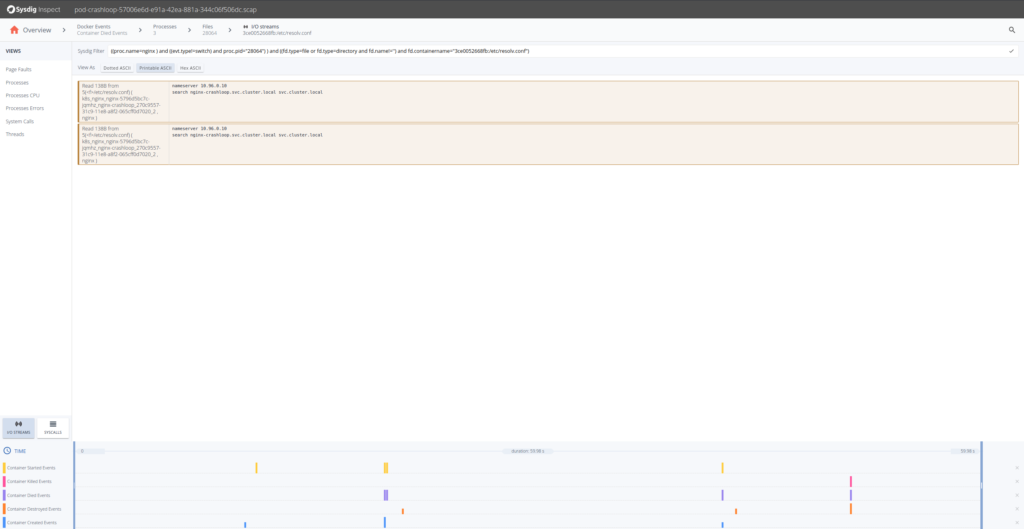
ここからさらに進んで、DNSリクエスト53/UDPを見てみると、応答が見つからなかったようです。NginxのReplicaSetsを先にデプロイし、上流のKubernetesサービスを後からデプロイしたことが、トラブルシューティングの手がかりとなります。Nginxには、クライアントからのリクエスト時ではなく、起動時にプロキシ名(”flask “など)をキャッシュするという特徴があります。言い換えれば、異なるKubernetesエンティティを間違った依存関係の順序でデプロイしてしまったということです。
まとめ
ポッドの再起動のようなものは簡単に見つけることができますが、本番サービスにおける潜在的な劣化への対応と迅速な回復ははるかに困難です。特に、コンテナからのログがなくなってしまった場合や、特定の環境の外で問題を再現できない場合、あるいはコンテナ内にトラブルシューティングツールがない場合などがあります。そのため、Sysdigキャプチャーのような更なるトラブルシューティングの準備が必要となります。Sysdigキャプチャーは、コンテナの完全なコンテキストを提供し、あらゆるプロセス間通信、書き込まれたファイル、ネットワーク・アクティビティを完全に可視化します。まるでタイムマシンのように システムコール・レベルでのトラブルシューティングは難しいものですが、Sysdig Inspectを使えば簡単です。