本文の内容は、2023年1月26日にVICTOR HERNANDO が投稿したブログ(https://sysdig.com/blog/how-to-monitor-coredns)を元に日本語に翻訳・再構成した内容となっております。
CoreDNSは、Kubernetes環境向けの
DNSアドオンです。コントロールプレーンノードで動作するコンポーネントの1つで、これが完全に動作し、応答することは、Kubernetesクラスターが適切に機能するための鍵になります。CoreDNSを監視する方法と、その最も重要なメトリクスが何であるかを学ぶことは、運用チームにとって必須です。

あなたのキャリアのある時点で、あなたは聞いたことがあるかもしれません。なぜいつもDNSなのですか?
まあ、それは簡単なことです。DNSは、あらゆるアーキテクチャーにおいて最も機密性が高く、重要なサービスの1つです。アプリケーション、マイクロサービス、サービス、ホスト…今日では、すべてが相互接続されており、これは必ずしも内部サービスを意味するものではありません。外部サービスにも適用できます。DNSは、ドメイン名を解決し、内部または外部サービス、PodのいずれかのIPを容易にする役割を担っています。PodsのDNSレコードを維持することは、特にIPアドレスが警告なしにいつ変わるかわからないエフェメラルPodsの場合、重要なタスクとなります。
しかし、DNSが応答しなかったり、ダウンしたりするとどうなるでしょうか?
あなたは深刻な問題に直面することになります。
Kubernetesでワークロードを実行しており、CoreDNSを監視する方法がわからない場合は、読み進めて、Prometheusを使用してCoreDNSメトリクスをスクレイピングする方法、これらのうちどれを確認すべきか、そしてそれらが何を意味するかをチェックしてください。
この記事では、以下のトピックを取り上げます。
- KubernetesのCoreDNSとは?
- KubernetesのCoreDNSを監視する方法は?
- KubernetesのCoreDNSを監視する:どのメトリクスを確認する必要がありますか?
- まとめ
Kubernetes CoreDNSとは?
Kubernetes 1.11から、DNSベースのサービスディスカバリのGeneral Availability(GA)を迎えた直後に、これまでKubernetesクラスターの事実上のDNSエンジンであったkube-dnsアドオンの代替として、
CoreDNSが導入されました。CoreDNSはその名の通り、Goで書かれたDNSサービスで、その柔軟性から広く採用されています。
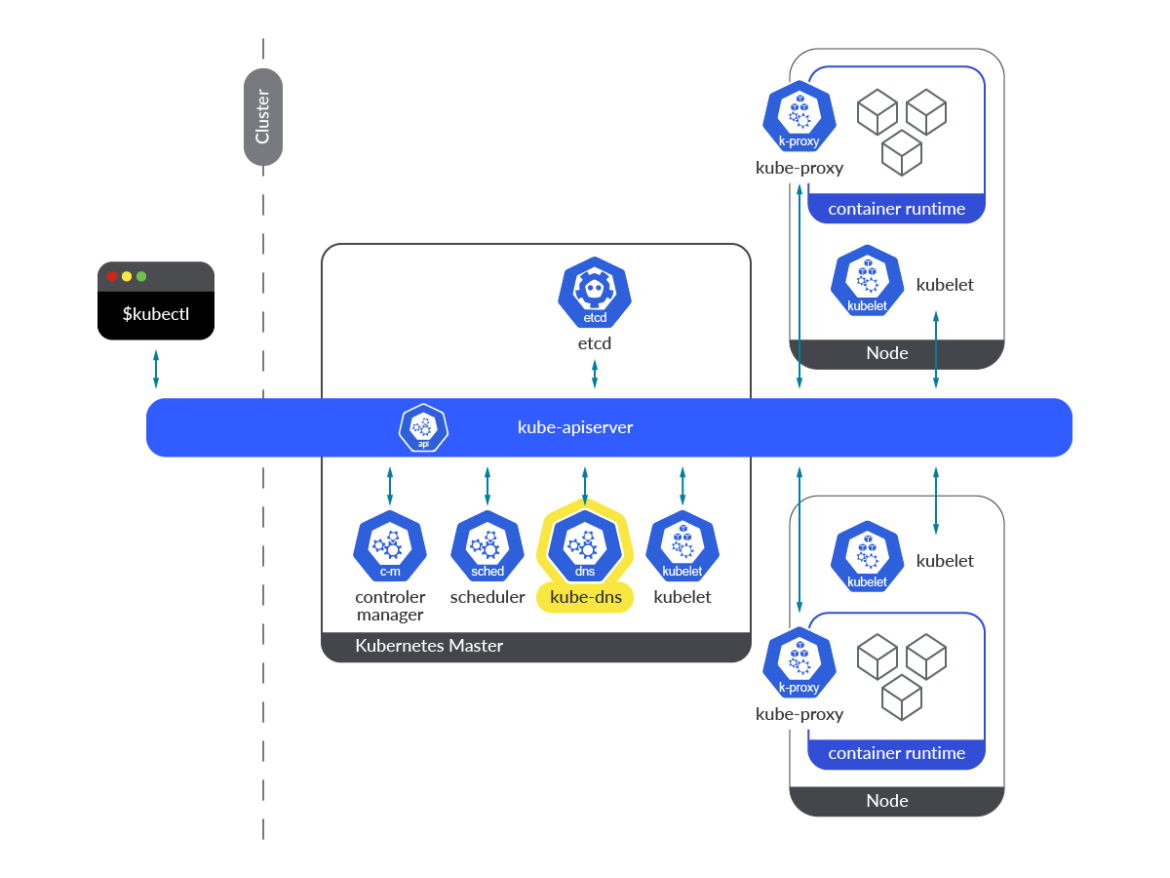
kube-dnsアドオンに関しては、1つのPod内にkubedns、dnsmasq、sidecarという3種類のコンテナという形でDNS機能全体を提供しています。この3つのコンテナについて見ていきましょう。
kubedns: Kubernetes用のSkyDNSの実装です。Kubernetesクラスター内のDNS解決を担当します。KubernetesのAPIを監視し、適切なDNSレコードを提供します。dnsmasq: SkyDNSの解決要求のためのDNSキャッシュ機構を提供します。sidecar: このコンテナは、メトリクスをエクスポートし、DNSサービスのヘルスチェックを実行します。
それでは、CoreDNSについて説明します!
CoreDNSは、当時kube-dnsがもたらした問題のいくつかを解決するために登場しました。
Dnsmasqは、過去にKubernetesのセキュリティパッチが必要となるような
セキュリティ脆弱性の問題をもたらしました。さらに、CoreDNSは、kube-dnsで必要だった3つのコンテナではなく、1つのコンテナですべての機能を提供し、
kube-dnsの外部サービス用スタブドメインに関する他のいくつかの問題を解決しています。
CoreDNSはそのメトリクスエンドポイントを9153ポートで公開し、SDNネットワーク内のPodからもホストノードネットワークからもアクセス可能です。
# kubectl get ep kube-dns -n kube-system -o json |jq -r ".subsets"
[
{
"addresses": [
{
"ip": "192.169.107.100",
"nodeName": "k8s-control-2.lab.example.com",
"targetRef": {
"kind": "Pod",
"name": "coredns-565d847f94-rz4b6",
"namespace": "kube-system",
"uid": "c1b62754-4740-49ca-b506-3f40fb681778"
}
},
{
"ip": "192.169.203.46",
"nodeName": "k8s-control-3.lab.example.com",
"targetRef": {
"kind": "Pod",
"name": "coredns-565d847f94-8xqxg",
"namespace": "kube-system",
"uid": "bec3ca63-f09a-4007-82e9-0e147e8587de"
}
}
],
"ports": [
{
"name": "dns-tcp",
"port": 53,
"protocol": "TCP"
},
{
"name": "dns",
"port": 53,
"protocol": "UDP"
},
{
"name": "metrics",
"port": 9153,
"protocol": "TCP"
}
]
}
]
CoreDNSが何であるか、そして既に解決された問題はお分かりいただけたと思います。次はCoreDNSのメトリクスを取得する方法と、Prometheusインスタンスを構成してメトリクスのスクレイピングを開始する方法を深掘りする番です。さっそく始めてみましょう!
KubernetesでCoreDNSを監視する方法は?
前のセクションで見たように、CoreDNSはすでにインスツルメンテーションされており、すべてのCoreDNS Podのポート9153で独自の
/metrics エンドポイントを公開しています。この
/metricsエンドポイントへのアクセスは簡単で、curlを実行するだけで、すぐにCoreDNSのメトリクスを取得し始めることができます。
エンドポイントに手動でアクセスする
CoreDNSが動作しているエンドポイントまたはIPがわかったら、9153ポートにアクセスしてみてください。
# curl http://192.169.203.46:9153/metrics
# HELP coredns_build_info A metric with a constant '1' value labeled by version, revision, and goversion from which CoreDNS was built.
# TYPE coredns_build_info gauge
coredns_build_info{goversion="go1.18.2",revision="45b0a11",version="1.9.3"} 1
# HELP coredns_cache_entries The number of elements in the cache.
# TYPE coredns_cache_entries gauge
coredns_cache_entries{server="dns://:53",type="denial",zones="."} 46
coredns_cache_entries{server="dns://:53",type="success",zones="."} 9
# HELP coredns_cache_hits_total The count of cache hits.
# TYPE coredns_cache_hits_total counter
coredns_cache_hits_total{server="dns://:53",type="denial",zones="."} 6471
coredns_cache_hits_total{server="dns://:53",type="success",zones="."} 6596
# HELP coredns_cache_misses_total The count of cache misses. Deprecated, derive misses from cache hits/requests counters.
# TYPE coredns_cache_misses_total counter
coredns_cache_misses_total{server="dns://:53",zones="."} 1951
# HELP coredns_cache_requests_total The count of cache requests.
# TYPE coredns_cache_requests_total counter
coredns_cache_requests_total{server="dns://:53",zones="."} 15018
# HELP coredns_dns_request_duration_seconds Histogram of the time (in seconds) each request took per zone.
# TYPE coredns_dns_request_duration_seconds histogram
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.00025"} 14098
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.0005"} 14836
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.001"} 14850
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.002"} 14856
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.004"} 14857
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.008"} 14870
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.016"} 14879
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.032"} 14883
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.064"} 14884
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.128"} 14884
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.256"} 14885
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="0.512"} 14886
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="1.024"} 14887
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="2.048"} 14903
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="4.096"} 14911
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="8.192"} 15018
coredns_dns_request_duration_seconds_bucket{server="dns://:53",zone=".",le="+Inf"} 15018
coredns_dns_request_duration_seconds_sum{server="dns://:53",zone="."} 698.531992215999
coredns_dns_request_duration_seconds_count{server="dns://:53",zone="."} 15018
…
(output truncated)
また、Kubernetesクラスターでデフォルトで公開されているCoreDNS Kubernetesサービスを通じて、
/metrics エンドポイントにアクセスすることもできます。
# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 129d
# kubectl exec -it my-pod -n default -- /bin/bash
# curl http://kube-dns.kube-system.svc:9153/metrics
CoreDNSメトリクスをスクレイピングするためのPrometheusの設定方法
Prometheusは、ターゲットのディスカバリーを開始し、Pod、Kubernetesノード、Kubernetesサービスなどの複数のソースからメトリクスをスクレイピングするための一連のロールを提供しています。Kubernetesクラスターに組み込まれたCoreDNSサービスからメトリクスをスクレイピングする場合、
prometheus.yml ファイルに適切な設定を行うだけでよいのです。今回は、このターゲットをディスカバリーするために、
endpointsロールを使用します。
prometheus.yml の設定ファイルが含まれる
ConfigMap を編集します。
# kubectl edit cm prometheus-server -n monitoring -o yaml
そして、
scrape_configs セクションの下に、以下の設定スニペットを追加します。
- honor_labels: true
job_name: kubernetes-service-endpoints
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape
- action: drop
regex: true
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scrape_slow
- action: replace
regex: (https?)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_scheme
target_label: __scheme__
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_service_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: (.+?)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_service_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_service_annotation_prometheus_io_param_(.+)
replacement: __param_$1
- action: labelmap
regex: __meta_kubernetes_service_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: namespace
- action: replace
source_labels:
- __meta_kubernetes_service_name
target_label: service
- action: replace
source_labels:
- __meta_kubernetes_pod_node_name
target_label: node
この時点で、Prometheus Podを再デプロイすると、PrometheusコンソールでCoreDNSのメトリクスエンドポイントが利用できるようになるはずです(Status -> Targetsへ移動します)。

これでCoreDNSメトリクスが利用できるようになり、Prometheusコンソールからアクセスできるようになりました。
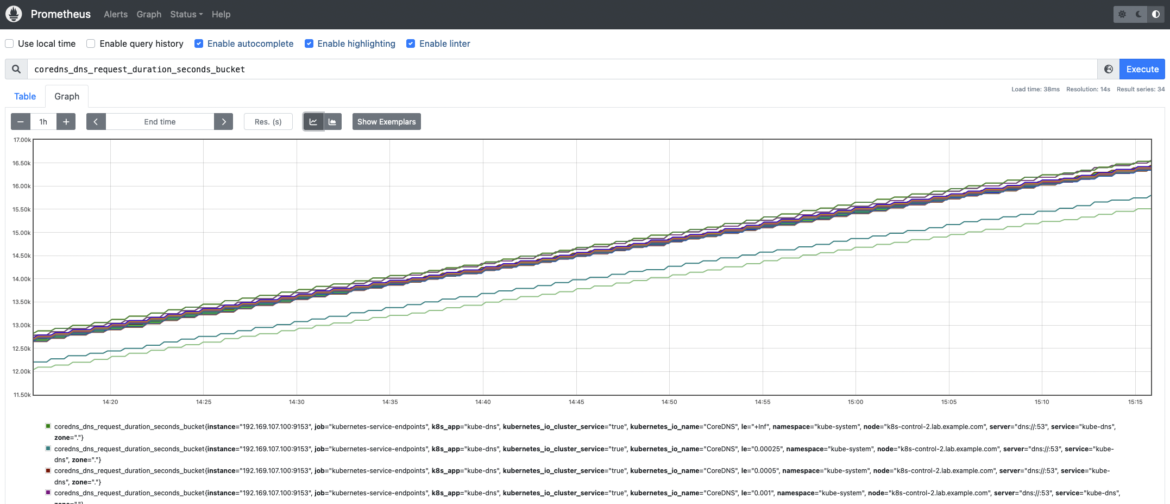
CoreDNSのトップメトリクス。どのメトリクスを確認する必要がありますか?
免責事項: CoreDNSメトリクスは、Kubernetesのバージョンやプラットフォームによって異なる場合があります。ここでは、Kubernetes 1.25とCoreDNS 1.9.3を使っています。CoreDNSのレポで、自分のバージョンで利用できるメトリクスを確認することができます。
まず、可用性についてです。クラスター内で動作するCoreDNSのレプリカの数は変動する可能性があるので、可用性やパフォーマンスに影響を与えるような変動があった場合に備えて、常に監視しておくとよいでしょう。
- CoreDNSレプリカの数:Kubernetes環境で稼働しているCoreDNSレプリカの数を監視したい場合は、
coredns_build_info メトリクスをカウントすることで行えます。このメトリクスは、そのようなPod上で動作しているCoreDNSのビルドに関する情報を提供します。
count(coredns_build_info)
これからは、
4つのゴールデンシグナルのアプローチに従いましょう。このセクションでは、その観点からCoreDNSを監視する方法を学び、エラー、レイテンシー、トラフィック、およびサチュレーションを測定します。
エラー
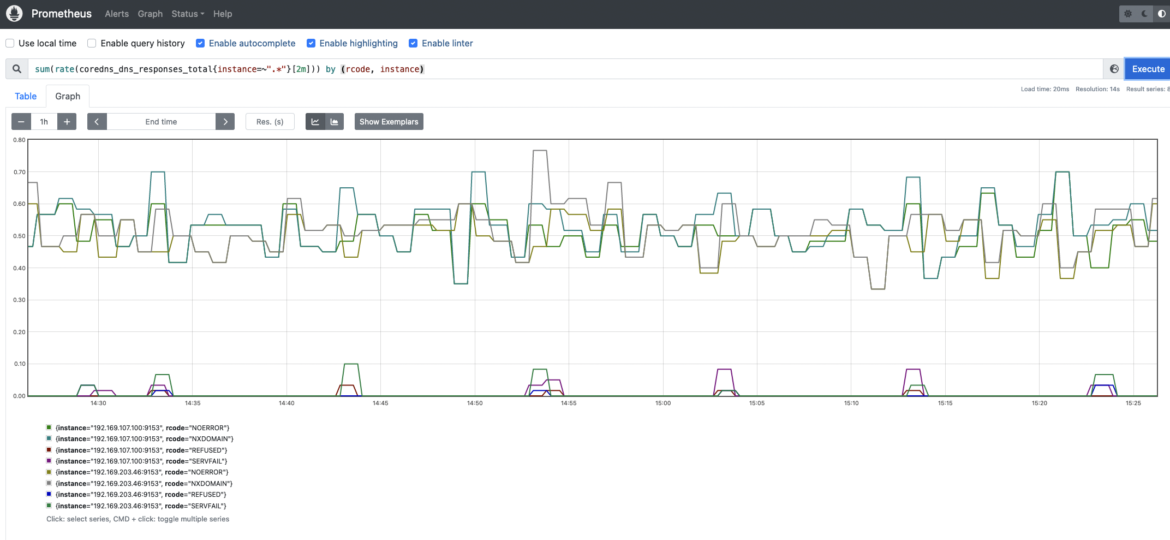
CoreDNSサービスのエラー数を測定できることは、Kubernetesクラスター、アプリケーション、およびサービスの健全性をより良く理解するための鍵です。アプリケーションや内部のKubernetesコンポーネントがDNSサービスから予期せぬエラーレスポンスを取得した場合、深刻な問題に直面する可能性があります。
SERVFAIL と
REFUSED のエラーに注意してください。これらは、Kubernetes内部コンポーネントやアプリケーションの名前を解決する際に問題が発生することを意味する可能性があります。
coredns_dns_responses_total: このカウンターは、CoreDNS応答コード、ネームスペース、およびCoreDNSインスタンスの数についての情報を提供します。各レスポンスコードのレートを取得したい場合があります。これは、CoreDNSインスタンスのエラー率を測定するために常に有用です。
sum(rate(coredns_dns_responses_total{instance=~".*"}[2m])) by (rcode, instance)
レイテンシー
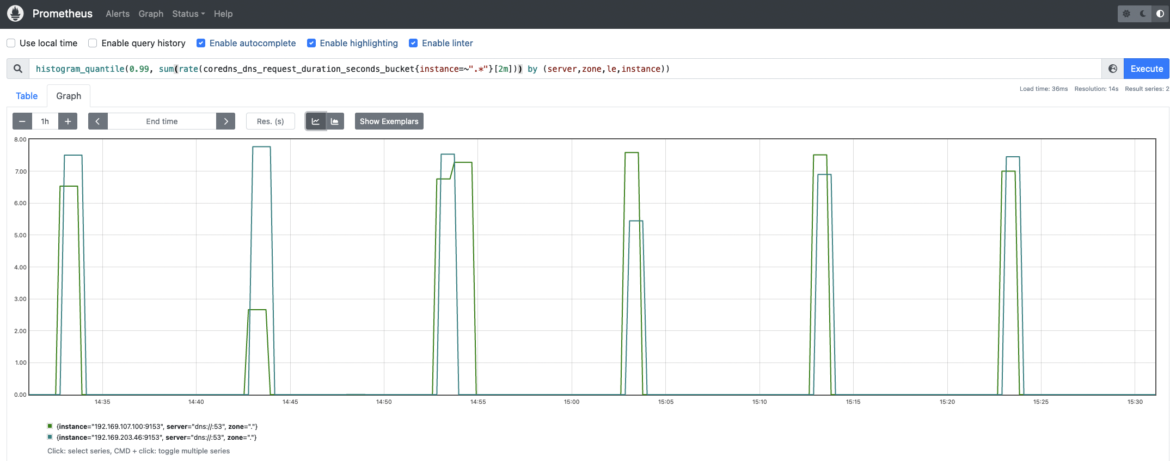
Kubernetesでの適切な運用のために、DNSサービスのパフォーマンスが最適であることを確認するためには、レイテンシーの測定が重要です。レイテンシーが高い、または時間と共に増加している場合、負荷の問題を示している可能性があります。CoreDNSインスタンスが過負荷の場合、DNSの名前解決に問題が発生し、アプリケーションやKubernetesの内部サービスに遅延や停止が発生することが予想されます。
coredns_dns_request_duration_seconds_bucket: CoreDNSリクエストの継続時間(秒)。CoreDNSインスタンス間でレイテンシーがどのように分布しているかを確認するために、99パーセンタイルを計算したい場合があります。
histogram_quantile(0.99, sum(rate(coredns_dns_request_duration_seconds_bucket{instance=~".*"}[2m])) by (server,zone,le,instance))
トラフィック
CoreDNSサービスが処理しているトラフィックまたはリクエストの量です。CoreDNSのトラフィックの監視は、本当に重要であり、定期的に確認する価値があります。トラフィック量の急増や傾向の変化があるかどうかを観察することは、良好なパフォーマンスを保証し、問題を回避するための鍵となります。
coredns_dns_requests_total: ゾーン、プロトコル、ファミリーごとのDNSリクエストカウンター。タイプ別(A、AAAA)のCoreDNSリクエストのレートを測定・監視したい場合があります。”A “はipv4クエリーを表し、”AAAA “はipv6クエリーを表します。
(sum(rate(coredns_dns_requests_total{instance=~".*"}[2m])) by (type,instance))

サチュレーション
CoreDNS PodsのCPU、メモリ、ネットワーク使用率などのシステムリソース消費メトリクスを使用することで、CoreDNSのサチュレーションの状態を簡単に監視することができます。
その他
CoreDNSは、DNSサービスが最大3600秒のレコードをキャッシュすることを可能にする
キャッシュメカニズムを実装しています。このキャッシュは、CoreDNSの負荷を大幅に軽減し、パフォーマンスを向上させることができます。
coredns_cache_hits_total: キャッシュヒットカウンターです。以下のクエリーを実行して、キャッシュヒット率を監視することができます。このPromQLクエリーのおかげで、CoreDNSキャッシュヒットの拒否率と成功率を簡単に監視することができます。
sum(rate(coredns_cache_hits_total{instance=~".*"}[2m])) by (type,instance)

まとめ
Kubernetes環境にDNSサービスを実装するには、kube-dnsと並んでCoreDNSが選択肢の1つになります。DNSはKubernetesクラスターを正常に機能させるために必須ですが、CoreDNSはkube-dnsと比較して、柔軟性や解決できる問題の多さから、多くの人に好まれています。
Kubernetesインフラストラクチャーが健全で正常に動作していることを確認したい場合、DNSサービスを恒久的にチェックする必要があります。これは、あらゆるアプリケーション、オペレーティングシステム、ITアーキテクチャー、またはクラウド環境において、適切な動作を確保するための鍵です。
この記事では、CoreDNS のメトリクスを引き出す方法と、CoreDNS のエンドポイントからメトリクスをスクレイピングするための独自の Prometheus インスタンスを構成する方法について学びました。CoreDNSの主要なメトリクスのおかげで、あらゆるKubernetes環境で独自のCoreDNSの監視を簡単に開始することができます。
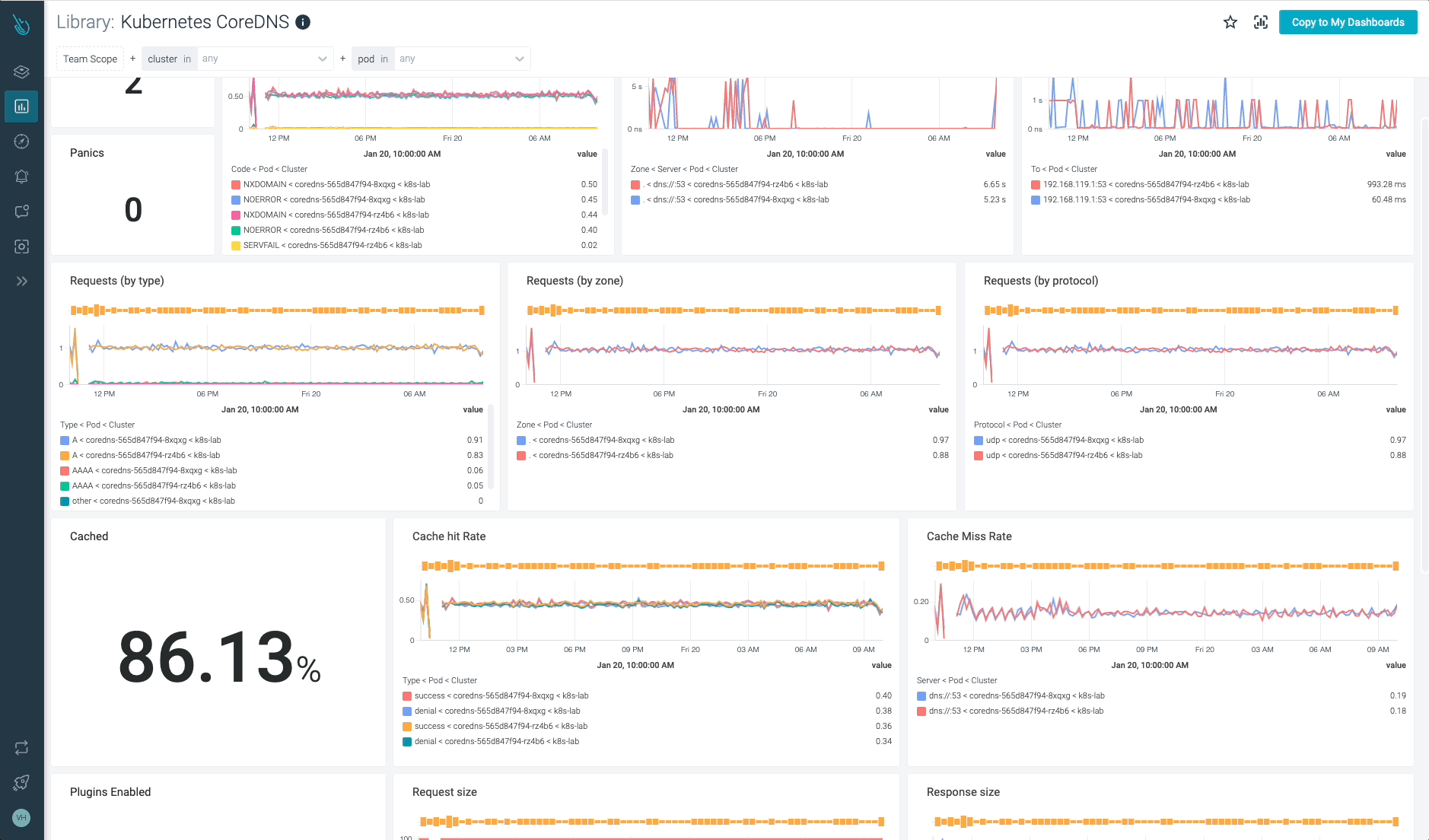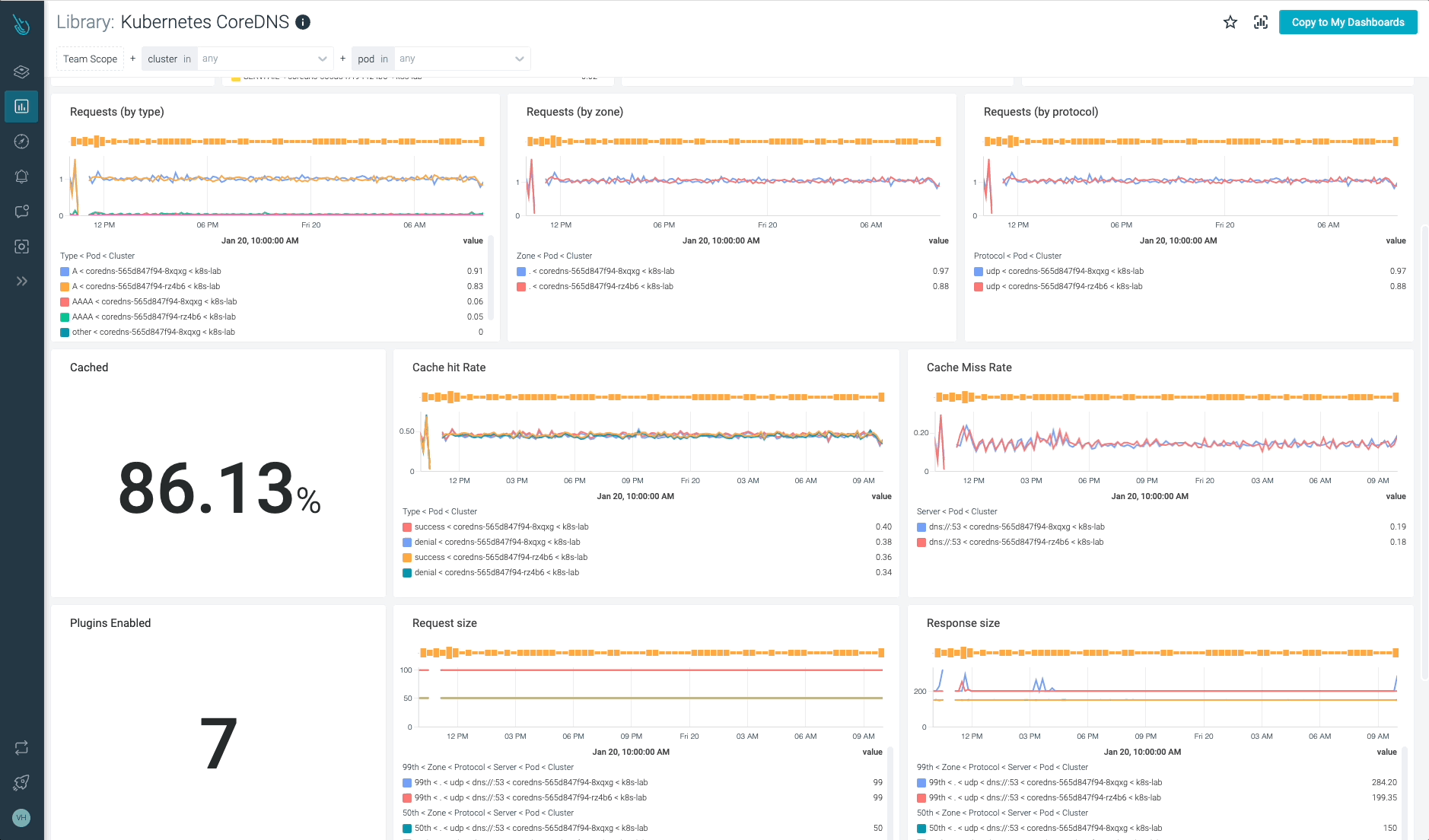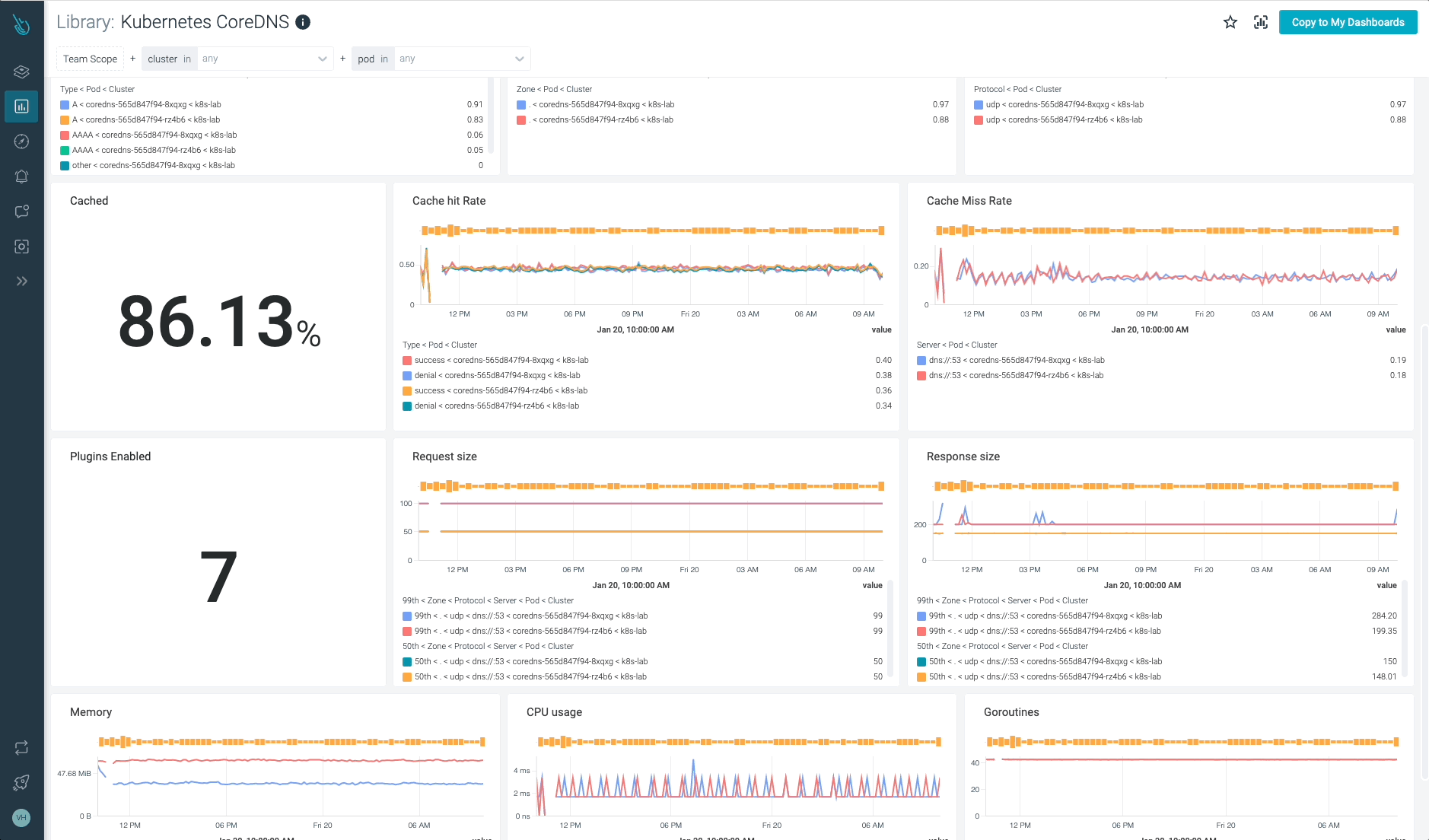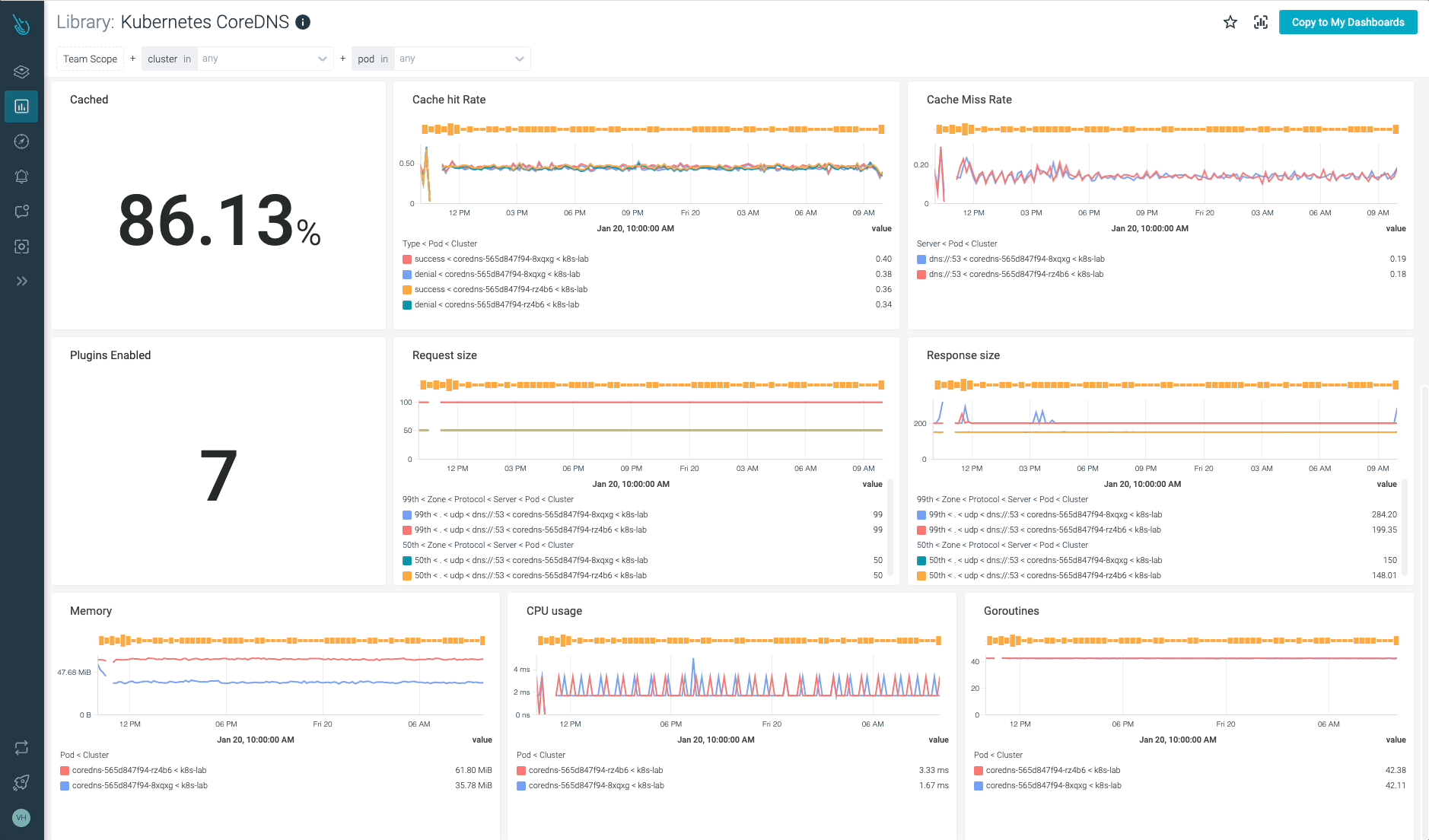
Kubernetes CoreDNSの監視と問題のトラブルシューティングを最大10倍高速化
Sysdigは、Sysdig Monitorに含まれる
すぐに使えるダッシュボードで、CoreDNSやKubernetesコントロールプレーンの他の部分の問題の監視とトラブルシューティングを支援し、Prometheusサーバーのインスツルメンテーションは必要ありません! Sysdig Monitorに統合されたツールであるAdvisorは、Kubernetesクラスターとそのワークロードのトラブルシューティングを最大10倍まで加速します。Sysdig Monitorのアウトオブボックスのダッシュボードのおかげで、Kubernetes CoreDNSのメトリクスをすべて手元に置くことができます。
 30日間のトライアルアカウント
30日間のトライアルアカウントにサインアップして、ご自身でお試しください!

