
以前のブログ記事で、Kubernetesのリミットとリクエストの基本について説明しました:これらは、クラウド環境のリソースを管理するために重要な役割を果たします。
このシリーズの別の記事では、クラスターに影響を与える可能性のあるOOMとCPUスロットリングについて説明しました。
しかし、全体として、リミットとリクエストはCPU管理のための銀の弾丸ではなく、他の選択肢の方が良い場合があります。
このブログポストでは、次のことを学びます:
- CPUリクエストの仕組み
- CPUリミットの仕組み
- プログラミング言語別の現在の状況
- リミットが最適な選択肢でない場合
- リミットの代わりに使用できるもの
KubernetesのCPUリクエスト
リクエストは、Kubernetesでは2つの目的を果たします。可用性のスケジューリング
まず、KubernetesにCPUの使用可能量(他のPod/コンテナによってすでに要求されておらず、指定されたNode(s)で実際にその時間にアイドル状態でないこと)を知らせます。そして、スケジューリングのフィルタリングの段階で、要求を満たすのに十分な未要求のリソースを持っていないNodeをフィルタリングします。もし十分なCPU/メモリがない場合、PodはスケジュールされずにPendingの状態で放置され、CPU/メモリが確保されるまで待機します。

CPUの割り当てを保証する
実行するNodeを決定すると(最初にFilterを通過し、次にScoreが最も高いもの)、LinuxのCPUシェアをmCPUメトリクスとほぼ一致するように設定します。CPUシェア(cpu_share)は、Linux Control Groups(cgroups)のFeatureの一つです。通常、cpu_shareは任意の数を指定でき、Linuxは各cgroupsのシェア数と全シェア数の合計との比率を使用して、どのプロセスがCPUにスケジュールされるかの優先順位を決定します。例えば、あるプロセスのシェア数が1,000で、すべてのシェア数の合計が3,000の場合、そのプロセスは全体の3分の1の時間を得ることになります。Kubernetesの場合:
- すべてのNodeでLinuxのCPUシェアを設定する唯一のものであるべきで、そのシェアは常にmCPUメトリクスに合わせられます。
- 実際にマシンで利用可能な論理CPUコアのうち、最大mCPUまでしか要求できません(要求されていないCPUが十分でない場合、スケジューラーによってフィルタリングされます)。
- つまり、LinuxのcgroupsのCPUシェアは、システム上のコンテナの最低CPUコアをほぼ「保証」することになりますが、Linuxでは必ずしもそのような使い方はされません。
CPUリクエストの設定は任意なので、設定しなかった場合はどうなるのでしょうか?
- LimitRangeでネームスペースにリミットを設定した場合は、そのLimitが適用されます。
- リクエストを設定せず、リミットを設定した場合(直接またはネームスペースのLimitRangeを介して)、リミットに等しいリクエストも設定されます。
- ネームスペースに LimitRange がなく、リミットもない場合、リクエストを指定しなければ、リクエストはありません。
CPU Requestを指定しないことで:
- スケジューリングでフィルタリングされるノードがないため、「満杯」であってもどのノードでもスケジューリングできます(ただし、最もスコアの良いノードを取得することになり、多くの場合、最も満杯ではないノードになるはず)。つまり、CPUの観点からクラスタをオーバープロビジョニングすることができるのです。
- その結果、Pod/コンテナはCPUシェアを持たないため、Node上で最も低い優先順位となります(一方、Requestを投入した人はCPUシェアを持つことになります)。

また、Podにリクエストを設定しないと、BestEffort Quality of Service(QoS)となり、可用性を維持するためのアクションが必要な場合にNodeからevictedさせられる可能性が最も高くなることに注意してください。
そのため、コンテナが要件(可用性、パフォーマンス/レイテンシーなど)を満たすために最低限必要なリクエストを十分に高く設定することが非常に重要です。

また、アプリケーションがステートレスであると仮定すると、スケールアップ(より大きなPodの数を減らし、それぞれがより多くの作業を行う)ではなく、スケールアウト(より小さなPodをより多くのNodeに分散させ、それぞれがより少ない作業を行う)することは、特定のPodやNodeを失ったとしても、アプリケーション全体への影響が少なくなるため、可用性の観点からもしばしば意味を持ちます。また、スケジューリング時に小さなPodをノードにフィットさせやすくなるため、リソースをより効率的に使用できるようになります。
KubernetesのCPUリミット
リクエストに加えて、KubernetesにはCPUのリミットもあります。リミットは、アプリケーションが使用できるリソースの最大量ですが、利用可能なリソースに依存するため、保証されません。リクエストは、コンテナが少なくともその量/割合のCPU時間を持つことを保証すると考えることができますが、リミットは代わりに、コンテナがその量以上のCPU時間を持つことができないことを保証します。
これにより、システム上の他のワークロードが制限されたコンテナと競合しないように保護されますが、制限されたコンテナのパフォーマンスに深刻な影響を与える可能性もあります。また、リミットの仕組みは直感的ではなく、お客様はしばしば設定を誤ることがあります。
リクエストは Linux の cgroup CPU 共有を使用しますが、リミットは代わりに cgroup CPU quotas を使用します。
これらには2つの主要なコンポーネントがあります。
- アカウンティングピリオド:クォータをリセットするまでの時間(マイクロ秒単位)。Kubernetesのデフォルトでは、これを100,000us(100ミリ秒)に設定しています。
- クォータピリオド:その集計期間中にcgroup(この場合、私たちのコンテナ)が持つことができるCPU時間の量(マイクロ秒単位)。KubernetesはこれをCPU == 1000m CPU == 100,000us == 100msと設定しています。
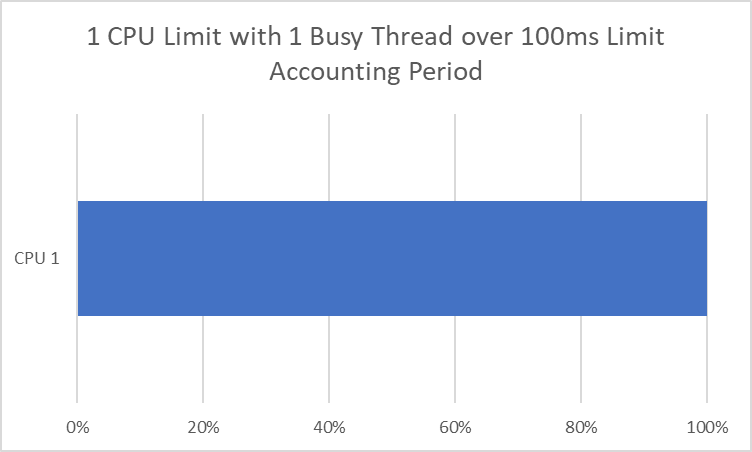
VS

これがシングルスレッド(一度に1つのCPUコアでしか実行できない)アプリであれば、直感的に理解できます。1CPUにリミットをかけると、100msごとに100msのCPU時間、またはそのすべてを得ることができます。問題は、一度に複数のCPUで実行できるマルチスレッドのアプリを用意した場合です。
2つのスレッドがあれば、1CPU期間(100ms)を最短で50msで消費することができます。そして、10個のスレッドが10msで1CPU期間秒を消費することができ、100msごとに90ms、つまり90%の時間、スロットル状態になります。これは通常、スロットルされていない1つのスレッドがある場合よりもパフォーマンスが悪化することにつながります。
もう1つの重要な考慮点は、アプリや言語/ランタイムによっては、Nodeのコア数を見て、そのリクエストやリミットに関係なく、すべてのコアを使用できると思い込んでしまうことです。また、私たちのKubernetes Node/Clusters/Environmentsが、コア数に関して一貫性がないとします。その場合、同じLimitでも、Coreの数の違いに応じて実行されるスレッドの数が異なるため、Node間で異なる動作になる可能性があります。
そのため、以下のどちらかが必要です:
- すべてのスレッドに対応するようにリミットを設定する。
- スレッド数を減らしてリミットに合わせる。
ただし、言語やランタイムがcgroupsを見て、リミットに自動的に適応することを知っている場合はこの限りではありません(一般的になってきています)。
プログラミング言語別の現状
Node.js
Nodeはシングルスレッドなので(worker_threadsを利用しない限り)、CPUコアを1つ以上使うようなコードにはならないはずです。そのため、個々のPodをスケールアップするよりも、Kubernetes上のより多くのPodにまたがってスケールアウトするのに適した候補になります。- 例外として、Node.jsはさまざまな処理(ファイルシステムIO、DNS、暗号、zlib)でデフォルトで4スレッドを実行しますが、UV_THREADPOOL_SIZE環境変数でそれを制御できます。
- Worker_threadsを使用する場合、スロットリングを防ぎたいのであれば、CPUのリミットを超える数のスレッドを同時に実行しないようにすることが必要です。この場合、maxThreads を Node の物理 CPU ではなく CPU のリミット値に合わせる必要があります (piscina のデフォルトは物理 CPU の 1.5 倍です – cgroup/container Limit から自動的にリミット値を計算することはありません)。
Python
Node.jsと同様に、インタプリタ型Pythonは通常シングルスレッドで、一部の例外(マルチプロセッシングライブラリの使用、C/C++拡張など)を除き、1CPU以上を使用するべきではありません。このため、Node.jsのように、個々のPodをスケールアップするのではなく、Kubernetes上のより多くのPodにまたがってスケールアウトするのに適しています。- なお、マルチプロセシングライブラリを使用する場合、デフォルトではNodeの物理的なコア数が実行すべきスレッド数であると仮定されます。この動作に影響を与える方法は、デフォルトのプールサイズを使用するのではなく、コードで設定する以外にないようです。現在、GitHubにオープンイシューが存在します。
Java
Java Virtual Machine(JVM)は、コンテナ/グループの自動検出をサポートするようになり、Dockerコンテナで実行されるJavaプロセスが利用できるメモリ量とプロセッサ数を判断できるようになりました。この情報は、システムリソースの割り当てに使用されます。このサポートは、Linux x64プラットフォームでのみ利用可能です。サポートされている場合、コンテナサポートはデフォルトで有効になります。サポートされていない場合は、-XX:ActiveProcessorCount=Xで、CPU リミットのコア数を手動で指定できます。.NET/C#
Javaと同様に、コンテナ/グループ自動検出のサポートを提供します。Golang
コンテナ(複数可)の環境変数GOMAXPROCSをCPUリミットに合わせて設定します。または、このパッケージを使用すると、Uberからのコンテナリミットに基づいて自動的に設定されます。クラウドにリミットは必要なのでしょうか?
リクエストは、リミットのようにCPU時間ではなく、総CPUの割合について話すので、概念的にもっと理にかなっています。リミットの主な目的は、特定のコンテナがNodeの特定の占有率しか得られないようにすることです。Node の量がある程度決まっている場合(オンプレミスのデータセンターで、今後数ヶ月/数年間使用するベアメタル Node の量が決まっている場合など)、マルチテナントシステム/環境全体の安定性と公平性を維持するために必要な悪となり得ます。
そのほかの主な使用例としては、予約した以上のリソースが利用できることに慣れてしまわないようにすること、つまりパフォーマンスの予測可能性を確保し、実際に予約した分しか与えられないのに文句を言われるような状況にならないようにすることです。
しかし、クラウドでは、コスト以外では、ノードの数は実質的に無制限です。しかも、プロビジョニングもデプロビジョニングも、コミットメントなしに素早く行うことができます。この弾力性と柔軟性が、そもそも多くのお客様がクラウドでワークロードを実行する理由の大きな部分を占めています。
また、ノードが何台必要かは、Podが何台必要かとそのサイズに直接左右されます。Podは実際に「仕事をし」、環境内で価値を高めるものであり、ノードではありません。また、必要なPodの数は、その時々の作業量(リクエスト数、キュー内のアイテム数など)に応じて、自動的/動的にスケールさせることができます。
コストを削減するためにいろいろなことができますが、ワークロードのパフォーマンスや可用性を損なうようなスロットリングは、最後の手段です。
リミットの代替手段

例えば、処理量が増えたとします(これはワークロードによって異なるでしょう – リクエスト/秒、キュー内の処理量、レスポンスのレイテンシーなどかもしれません)。まず、HPA(Horizontal Pod Autoscaler)が自動的にもう1つのPodを追加しますが、それをスケジュールするのに十分なNodeの容量がリクエストされないままあります。Kubernetes Cluster AutoscalerはこのPending Podを見て、Nodeを追加します。
その後、営業日が終了し、HPAは行うべき処理が少なくなったため、いくつかのPodをスケールダウンします。Cluster Autoscalerは、いくつかのノードをスケールダウンしても、すべてを稼働させるのに十分な予備容量を確認します。そのため、一部のノードをドレインしてから終了し、実行中の Pod の数が減ったため、環境を適切なサイズに調整します。
このような状況では、リミットは必要ありません。すべてのノードに対する正確なリクエスト(CPUシェアを通じて各ノードが機能するために必要な最小値を確保する)とクラスターオートスケーラがあればよいのです。これにより、ワークロードが不必要にスロットルされることはなく、いつでも適切な量のキャパシティを確保することができます。
まとめ
KubernetesのCPU リミットについてよく理解できたところで、次はワークロードを調べて適切に設定する番です。これは、ワークロードが他のワークロードにとってうるさい隣人でないことを保証しつつ、その過程でパフォーマンスをあまり損なわないようにする間の適切なバランスを取ることを意味します。多くの場合、これは実行中の同時スレッド数がリミットに沿うようにすることを意味します(ただし、JavaやC#などの一部の言語/ランタイムは、これを実行してくれます)。
また、リクエストとHPA(Horizontal Pod Autoscaler)を組み合わせて、よりダイナミックな(そしてスロットル的でない)方法で、常に十分な容量を確保できるようにするために、それらをまったく使用しないこともあります。
Sysdig MonitorでKubernetesリソースを適切にする
Sysdig MonitorのAdvisorツールを使用すると、現在のCPUの使用量と割り当てを素早く確認することができます:- 使用されているCPU VS 要求されたCPU
- CPU使用量 VS リミット
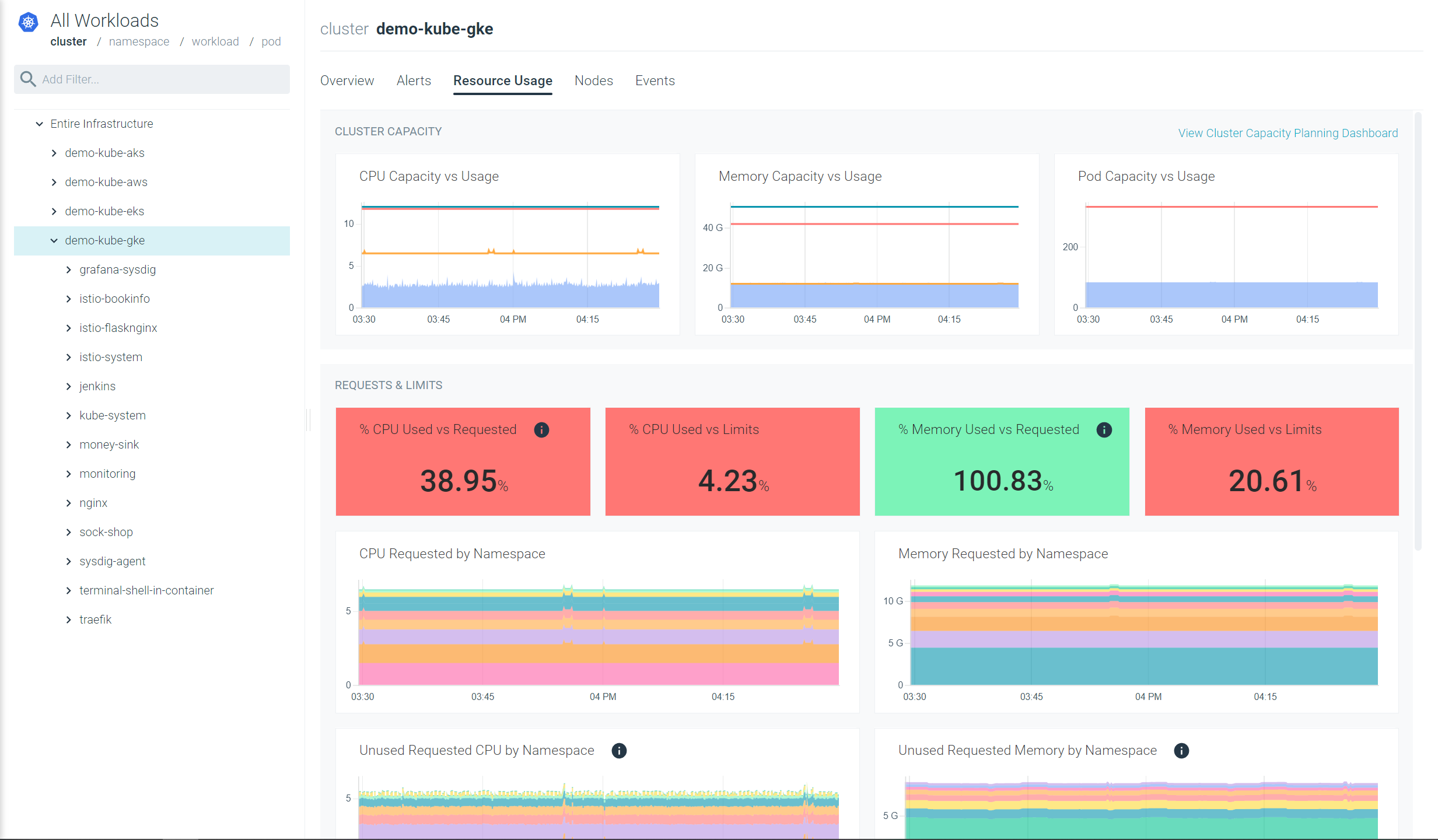
また、アウトオブボックスのKubernetesダッシュボードを使えば、2クリックで十分に活用されていないリソースを発見することができます。ワークロードを適正化し、支出を削減するのに役立つ洞察を簡単に得ることができます。
30日間無料でお試しください!