本文の内容は、2023年2月23日にVICTOR HERNANDO が投稿したブログ(https://sysdig.com/blog/kubernetes-metrics-ingestion)を元に日本語に翻訳・再構成した内容となっております。
Prometheusは、Kubernetes監視のための最も評判の良いソリューションの1つです。Kubernetesのメトリクスを引き出す作業を容易にする、複数のアドオンとエクスポーターがあります。Sysdig Monitorは、クラウドネイティブにおける監視プラットフォームで、監視のライフサイクル全体で企業を支援します。常にシンプルさを提供し、企業が頭痛に悩まされることなく、KubernetesとPrometheusのメトリクスを迅速にプルできるようにします。
Kubernetesとそのワークロードおよびサービスのすべてを監視することは、本当に難しいことです。現在、企業はアプリケーションと主要なビジネスプロセスをサポートする数十、数百、あるいは数千のKubernetesノードに依存しています。KubernetesでDIY(Do it Yourself)Prometheusデプロイを使用する場合、他のアドオンやエクスポーターもデプロイして設定する必要があります。これは、Kubernetesインフラストラクチャー、そのサービス、および独自のアプリケーションからメトリクスを取得するための方法です。これは、特に多くのKubernetesノードを運用している場合、
非常に時間がかかり、メンテナンスが大変です。さらに、
Prometheusを大規模に使用することは、
多くの企業にとって本当に困難であり、大きな苦痛となり得ます。
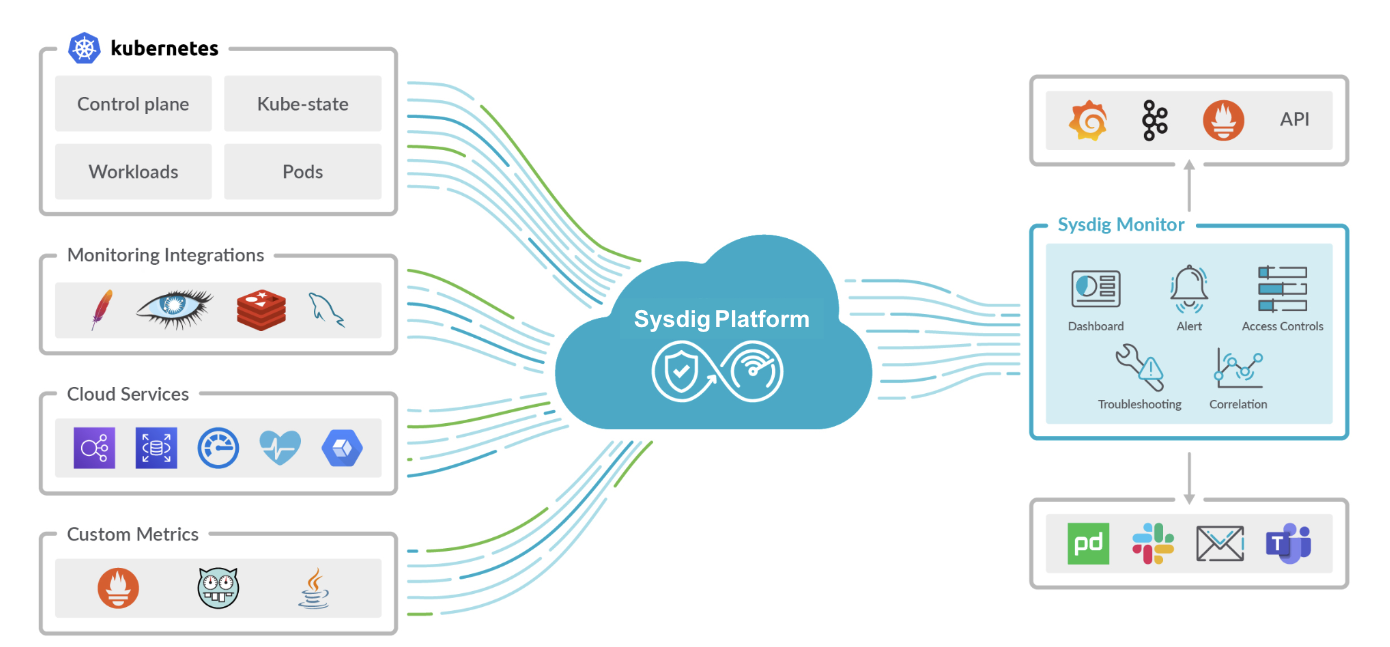
Sysdig Monitorは、完全で堅牢なクラウドネイティブの観測プラットフォームで、お客様はKubernetesのメトリクスだけでなく、Prometheusのメトリクスも最初から、ほとんどすぐに、余分な努力なしに引き出し始めることができます。そのPrometheusマネージドサービスは、大量のアウトオブボックスダッシュボードや、AdvisorやCost Advisorなどのユニークな機能とともに、企業のモニタリング、Kubernetesのトラブルシューティング、コスト削減を支援しています。
この記事では、Sysdig MonitorがKubernetesとPrometheusのメトリクス取り込みにどのように役立つか、またPrometheusマネージドサービスを利用する利点について詳しく説明します。もっと学びたいですか?では、読み進めてください
DIYでPrometheusのメトリクスを取り込む
Kubernetesを監視する場合、DIYのPrometheusインスタンス以外に、いくつかのものが必要です。
ノード、コンテナ、Kubernetesオブジェクトの状態に関するメトリクスやデータを取得したい場合、いくつかのエクスポーターをデプロイする必要があります。Prometheusは、独自のサービス・ディスカバリーによって発見された後、これらのターゲットからメトリクスをスクレイピングし始めます。

では、何が必要なのか、なぜ必要なのか、話を始めましょう。
cAdvisor
cAdvisor は、
コンテナリソースの使用状況とコンテナパフォーマンスデータの可視性を提供するツールです。とはいえ、Kubernetesで何かをデプロイする際に必要なものではありません。Kubelet 自体が自身の
/metrics エンドポイントを公開します。
/metrics/cadvisor経由でKubeletに埋め込まれたcAdvisorコードのおかげで、コンテナからパフォーマンスとリソース使用情報を取得できます。 cAdvisorデータは、コンテナのパフォーマンスをより深く理解するための鍵となるものです。
$ curl -k -H "Authorization: Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)" https://kubernetes.default.svc/api/v1/nodes/k8s-control-1.lab.example.com/proxy/metrics/cadvisor
# TYPE cadvisor_version_info gauge
cadvisor_version_info{cadvisorRevision="",cadvisorVersion="",dockerVersion="",kernelVersion="4.18.0-408.el8.x86_64",osVersion="CentOS Stream 8"} 1
# HELP container_blkio_device_usage_total Blkio Device bytes usage
# TYPE container_blkio_device_usage_total counter
container_blkio_device_usage_total{container="",device="",id="/",image="",major="11",minor="0",name="",namespace="",operation="Async",pod=""} 0 1675768595201
…
(output truncated)
Node exporter
node exporterプラグインは、
各ホストからカーネルとハードウェア関連のメトリクスを公開します。Kubernetesホストの状態やパフォーマンスに関するすべての重要な情報を取得したい場合は、node exporterを稼働させる必要があります。Kubernetesでは、ノードエクスポーターは
DaemonSet を通じてデプロイされ、すべてのホストが独自のエクスポーターインスタンスを実行していることを確認します。Node exporterはポート9100上でその
/metrics エンドポイントを公開します。メトリクスには
node_というプレフィックスがつきます。
$ kubectl get svc prometheus-node-exporter -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-node-exporter ClusterIP 10.110.189.50 <none> 9100/TCP 147d
$ kubectl get ep prometheus-node-exporter -n monitoring
NAME ENDPOINTS AGE
prometheus-node-exporter 192.168.119.30:9100,192.168.119.31:9100,192.168.119.32:9100 147d
$ curl http://k8s-control-1:9100/metrics
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.0106e-05
go_gc_duration_seconds{quantile="0.25"} 0.000102311
…
HELP node_arp_entries ARP entries by device
# TYPE node_arp_entries gauge
node_arp_entries{device="cali23d0a93a086"} 1
node_arp_entries{device="cali395ce2b1db4"} 1
node_arp_entries{device="cali64f632960f9"} 1
(output truncated)
Kube-state-metrics(KSM)とは?
KSMは、Kubernetes APIサービスをリッスンするサービスで、
Kubernetesオブジェクトの状態に関する独自のメトリクスセットを生成します。これらのメトリクスを取得したい場合は、すべてのクラスターにデプロイする必要があります。このサービスは、DaemonSets、デプロイ、ノード、ネームスペース、Podなどのオブジェクトから、状態やその他の関連情報を確認するための大量のメトリクスを提供します。KSMはデプロイメントを通じてデプロイされ、Podの中で実行されます。その
/metrics エンドポイントはポート8080で公開されています。
$ kubectl get svc prometheus-kube-state-metrics -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-kube-state-metrics ClusterIP 10.98.209.205 <none> 8080/TCP 147d
$ kubectl get ep prometheus-kube-state-metrics -n monitoring
NAME ENDPOINTS AGE
prometheus-kube-state-metrics 192.169.107.88:8080 147d
$ curl http://prometheus-kube-state-metrics.monitoring.svc:8080/metrics
kube_configmap_annotations{namespace="kube-system",configmap="extension-apiserver-authentication"} 1
kube_configmap_annotations{namespace="istio-system",configmap="istio-sidecar-injector"} 1
…
(output truncated)
Sysdig Monitorのメトリクス取り込み

Sysdigエージェント
Sysdig Monitorは、ノード上でエージェントを動作させます。Helm チャートやSysdigが提供するbashスクリプトを実行することで
簡単にデプロイすることができます。どちらの場合も、
DaemonSet が
各KubernetesノードにSysdig AgentのPodをデプロイする役割を担います。
$ kubectl get pods -n sysdig-agent
NAME READY STATUS RESTARTS AGE
sysdig-agent-6wfjv 1/1 Running 2 (62m ago) 6d2h
sysdig-agent-g2kg4 1/1 Running 2 (62m ago) 6d2h
sysdig-agent-h82d7 1/1 Running 2 (62m ago) 6d2h
エージェントのデプロイ後、Sysdig AgentがインフラストラクチャーからKubernetesのメトリクスを取得し始めるまで、1分もかかりません。余分なエクスポーターやアドオンをデプロイする必要は全くありません。Sysdig Agentは、Sysdigエンジニアリングチームによって管理・維持されているプリロードされた設定により、それ自体でKubernetesのエンドポイントに到達することが可能です。同様に、このデータはSysdigクラウドにあるPrometheusで管理されたサービスにプッシュされます。Kubernetesのメトリクスは、お客様独自のPrometheusやカスタムメトリクス、インフラストラクチャーからの他のデータとともに、ほぼ即座に利用できるようになります。
軽量なPrometheusインスタンス
Sysdig Agentは、Kubernetesから自動的にメトリクスをスクレイピングするだけでなく、
Prometheusのネイティブサービスのディスカバリーと自動スクレイピング機能により、
お客様のエンドポイントからPrometheusメトリクスをスクレイピングすることが可能です。軽量なPrometheusインスタンスはSysdig Agentに組み込まれ、各ノードで実行されます。Sysdigコンテナを調べると、このPrometheusのようなプロセスが表示されます。
$ kubectl exec -it sysdig-agent-6wfjv -n sysdig-agent -- /bin/bash
# ps -ef|grep prom
root 9945 5957 0 11:00 ? 00:00:16 promscrape_v2 --grpc.address=unix:/opt/draios/run/promscrape.sock --web.enable --web.listen-address=127.0.0.1:9990 --log.format=json --log.level=info --config.file=/opt/draios/etc/promscrape.yaml --source.label=pod_id,sysdig_k8s_pod_uid,remove --source.label=container_name,sysdig_k8s_pod_container_name,remove --source.label=sysdig_bypass,sysdig_bypass,remove --source.label=sysdig_omit_source,sysdig_omit_source,remove --cache.enable
独自のPrometheusインスタンスを持っているので、必要であれば、Kubernetesインフラクチャー内の任意の新しいエンドポイントからインジェストを開始するために、
独自のカスタムPrometheusジョブを追加することもできます。
prometheus.yaml 設定ファイルでの独自の設定も完全にサポートされています。同じように、Sysdig Agentはサードパーティソフトウェアを検出することができます。
Istioのように、これらの多くは統合され、デフォルトで有効になっています。その他は
統合によって利用可能です。
eBPF
一連の
eBPFプログラムは、Sysdigの可観測性計装に統合されています。
カーネルシステムコールはリアルタイムでキャプチャーされ、Kubernetesやクラウドインフラストラクチャーから必要と思われるすべての情報をSysdig Monitorバックエンドに供給します。ホストからパフォーマンス関連のデータを取得する必要があっても、コンテナから内部システムコールスレッドを追跡する必要があっても、
すべてはSysdig Agentによってキャプチャーされ、Sysdig Monitorのバックエンドにプッシュされます。
ここまではいいんです。しかし、KubernetesとPrometheusのメトリクスという観点では、セキュリティとパフォーマンスの強化以外に、eBPFの統合はSysdigのお客様に何をもたらし、競合他社の中でユニークな存在になるのでしょうか?
Sysdig Agentは、カーネルの知見をお客様のための実際のメトリクスに変えます。例えば、eBPFインスツルメンテーションのおかげで、Sysdig Monitorは、
システムコール間のレイテンシーを測定することによってカーネルレベルで計算された、インフラストラクチャーの新しいネットワークメトリクスを提供します。このデータは、cAdvisor、exporterノード、KSMのいずれからも取得できません。eBPFは、
ゴールデンシグナルのメトリクスにも使用されます。エージェントがカーネルから収集するシステムコールデータのおかげで、エラーやサチュレーション、トラフィック、レイテンシーを監視することができます。すでに述べたメトリクスに加えて、プロセスとIOメトリクスもeBPFを使用してシステムコールから取得されます。
同様に、カーネルのインサイトデータにより、Sysdig MonitorはKubernetes環境で実行されているあらゆるワークロードを検出することが可能です。アウトオブボックスのダッシュボードと
Sysdig Advisorにより、サードパーティ製のアプリケーションであっても、最初から監視とトラブルシューティングを行うことができます。
KSM、cAdvisor、ノードエクスポーターは必要ありません
その通りです! Sysdig Agentを使用する場合、これらのエクスポーターやアドオンをデプロイする必要はありません。同等のノードエクスポーターデータを取得する場合、上記のように、Sysdig AgentはすべてのKernelノードからこのデータを取得します。
cAdvisorのメトリクスに関しては、Sysdig AgentはすべてのKubernetesノードに統合されたKubelet cAdvisorモジュールから独自のメトリクスのセットをスクレイピングしています。
SysdigのノードエクスポーターとcAdvisorのメトリクスは、DIY Prometheusの名前とラベルと互換性がありません。
KSMはどうですか?Sysdig Agentには、Kubernetes APIサーバーからKSMメトリクスをスクレイピングするための独自のジョブがすでに設定されています。エクスポーターは全く必要ありません。KSMメトリクスをスクレイピングする際、注意しなければならないのはパフォーマンスです。大規模な環境では、Kubernetes APIサーバーからKSMメトリクスをスクレイピングしても、あまり良いパフォーマンスが得られないかもしれません。Sysdigは大規模環境向けにKSMに最適化されたメトリクスを提供しています。これらは、DIY Prometheusのデフォルトでは60秒ですが、10秒ごとに引き出されています。SysdigのKSMメトリクスはOSSのKSMメトリクスとほぼ互換性があるので、ユーザーは自分のダッシュボードやPromQLクエリーに活用することができます。
このように、Kubernetes内部データのインジェストは、DIY Prometheusを使用するよりも簡単です。Sysdigを使えば、ユーザーは追加のステップなしに自動的にデータの取り込みを開始することができます。Kubernetesクラスターに保守用のエクスポーターやアドオンをデプロイする必要はありません。
メトリクスエンリッチメント
インジェスト時に、あなたのメトリクスとクラウドインフラストラクチャーで、何かとてもエキサイティングなことが起こります。前述したように、Sysdig Agentは自動的に検出し、Kubernetesのメトリクスだけでなく、Prometheusのメトリクスも取得します。また、Kernel関連のデータやその他のインフラストラクチャーやクラウドのメトリクスも取得します。インフラストラクチャーからのすべての情報は、アノテーションによってすべてのメトリクスにタグ付けするために使用されます。そうすることで、
Kubernetesや自分のアプリケーションのメトリクスと、クラウドインフラストラクチャーの情報を相関させることができるのです。これが、私たちがメトリクス・エンリッチメントと呼ぶものです。
メトリクス・エンリッチメントのおかげで、データを取得するために無限の結合を行う必要はありません。また、データにはすでにKubernetesとクラウドのコンテキストが含まれているため、よりアクセスしやすくなっています。
このメトリクスエンリッチメントを使えば、コンテナID、IPインスタンス、クラウドプロバイダーのインスタンスタイプ、そしてコストまで簡単に取得することができます。メトリクスをクリックするだけで、結合やその他のPromQL シークレットマジックなしで、これらの情報やその他多くの情報をラベルとしてすぐに取得できます。
Sysdigは、Kubernetesとクラウドのコストと一緒にメトリクスを
収集し、フィードします。すべてアウトオブボックスで提供されるため、OpenCostや同様のツールをデプロイする必要はありません。
Sysdig remote write
Sysdig Monitorは、
remote writeに対応しています。DIY Prometheusと同じように、独自のメトリクスをプッシュすることができます。特に、Windowsノードや他のPrometheusインスタンスなど、Sysdigエージェントをインストールできない非Linux Kernel環境では有効です。
Sysdigでデータをインジェストするメリット
両方のメトリクスインジェストワークフローを経て、各コンポーネントの詳細がわかったところで、KubernetesのメトリクスインジェストにSysdigを使用するメリットをまとめてみましょう。
- Sysdig Agentのインストールは簡単で高速です。Helmチャート経由で数分でデプロイできます。
- Kubernetesメトリクス用のエクスポーターやアドオンをデプロイする必要がありません。Sysdig Agentは、Kubernetesのメトリクスとインフラストラクチャーのデータを自動的にスクレイプし始めます。
- Kubernetesのコントロールプレーン監視は重要です。Sysdig Agentは、追加の手順を踏むことなく、このすべてのデータを自動的に収集します。DIY Prometheusでは、コントロールプレーンコンポーネントごとにジョブを構成する必要があります。Sysdig Monitorのアウトオブボックスのダッシュボードのおかげで、Kubernetesのコントロールプレーンデータを探索することができます。
- Sysdigは、パフォーマンス、セキュリティ、インサイトなどの監視のために、独自のeBPFプログラムをSysdig Agentに統合しています。カーネルの監視は、Sysdig Monitorのメトリクスとして利用できるようになり、追加の手順は必要ありません。必要と思われるものはすべてアウトオブボックスで提供されます。
- Sysdig Agentは、独自のワークロードやサードパーティソフトウェアを検出することができます。アウトオブボックスのダッシュボードのおかげで、アプリケーションのパフォーマンスを最初から観察することができます。お客様側での特別な作業は必要ありません。
- メトリクスのリッチ化により、メトリクスのコンテンツが追加されます。インフラストラクチャーやクラウド関連のデータは、KubernetesやPrometheusのメトリクスに関連付けられます。アプリケーションはKubernetesのコンテキストを得ることができます。
- Kubernetesとクラウドのコストは、Sysdig Monitorのメトリクスとダッシュボードとして利用できるようになりました。あなたは、どれだけのお金を使いすぎているか認識していますか?Cost Advisorは、無駄な出費を減らすのに役立ちます。
- DIYでPrometheusインスタンスをデプロイし、維持する必要はありません。これは、Prometheusの大規模化に悩む多くのお客様にとって大きな痛手です。メトリクスが増えれば増えるほど、データを取り込み、処理、安全に保つためのリソースが必要になります。これはSysdigが管理しますので、お客様はもうこの重要なポイントをケアする必要はありません。
- DIY Prometheusのデフォルトは60秒ですが、Sysdigは10秒ごとにデータをインジェストします。
- Kubernetesクラスターからイベント、プロセス、ネットワークメトリクスを取得し、Kubernetesのコンテキストを得ることができます。
- DIY Prometheusと同様にremote writeでメトリクスをプッシュすることができます。
まとめ
Kubernetesクラスターからメトリクスを引き出すことは大したことではありませんが、ある程度のメトリクス量になると、DIY Prometheusでメトリクスをスクレイピングし、維持し、可用性を確保することは困難な場合があります。
Sysdig Monitorは、これらの大変な作業をすべて代行してくれます。Kubernetesのメトリクスやインフラストラクチャー情報の取得から、すべてのデータを(最初にメトリクスのリッチ化プロセスを経て)Sysdig Prometheus互換のマネージドプラットフォームにプッシュすることまで。KubernetesとPrometheusのメトリクスのパフォーマンス、スケーラビリティ、可用性について心配する必要はありません。さらに、Kubernetesの問題を分析しトラブルシューティングするために、
Sysdig Monitorがもたらすすべての機能の恩恵を受けることができます。
Sysdig MonitorがKubernetesのメトリクス取り込みにどのように役立つかを知りたい方は、Sysdig Monitorのトライアルページにアクセスし、
30日間の無料アカウントをリクエストしてください。数分で使い始めることができます!