
本文の内容は、2021年5月20日に Jesus Ángel Samitierが投稿したブログ(https://sysdig.com/blog/postgresql-monitoring)を元に日本語に翻訳・再構成した内容となっております。
PrometheusによるPostgreSQLの監視は、PostgreSQL Exporterのおかげで簡単に行うことができます。PostgreSQLはオープンソースのリレーショナルデータベースで、強力なコミュニティに支えられています。その強力な安定性と強力なデータ型により、非常に人気があります。
この記事では、KubernetesのPostgreSQLインスタンスとAWS RDSのPostgreSQLインスタンスの両方を対象に、PostgreSQLモニタリングのTop10メトリクスをアラートの例とともに学んでいきます。
PostgreSQLの監視におけるTop10メトリクス
可用性
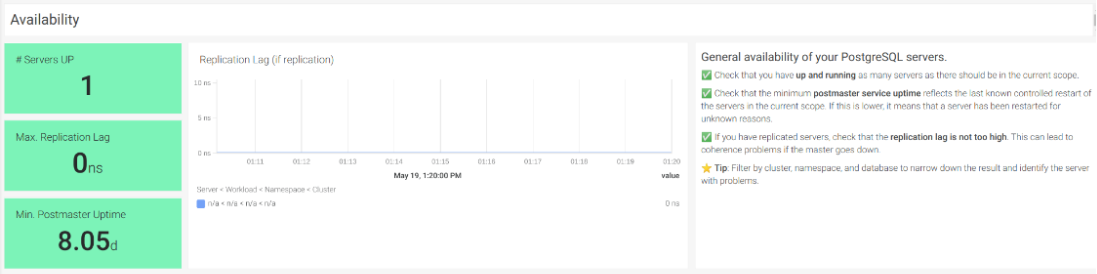
#1位 サーバーが稼働している
インスタンスが稼働していることを確認することは、PostgreSQL監視の最初のステップとなるはずです。エクスポーターは、PostgreSQLインスタンスの接続と可用性を監視します。PostgreSQL の可用性を監視するメトリクスは pg_up です。
PostgreSQLサーバがダウンした場合にトリガーするアラートを作成してみましょう。
pg_up == 0
#2 ポストマスターサービスの稼働率
また、最小のpostmasterサービス稼働時間が、最後に制御されたサーバの再起動を反映していることを確認することも重要です。そうでなければ、不明な理由でサーバが再起動されたことを意味します。PostgreSQLの可用性を監視するためのメトリクスは、pg_postmaster_start_time_secondsです。
過去1時間(3600秒)の間にPostgreSQLサーバが原因不明で再起動された場合に通知するアラートを作成してみましょう。
time() - pg_postmaster_start_time_seconds < 3600
レプリケーション
#3 レプリケーションの遅延
複製されたPostgreSQLサーバがあるシナリオでは、レプリケーションの遅延率が高いと、マスターがダウンした場合にコヒーレンスの問題が発生します。PostgreSQLの可用性を監視するためのメトリクスはpg_replication_lagです。
レプリケーションの遅延が10秒以上になったらトリガーするアラートを作ってみましょう。
pg_replication_lag > 10
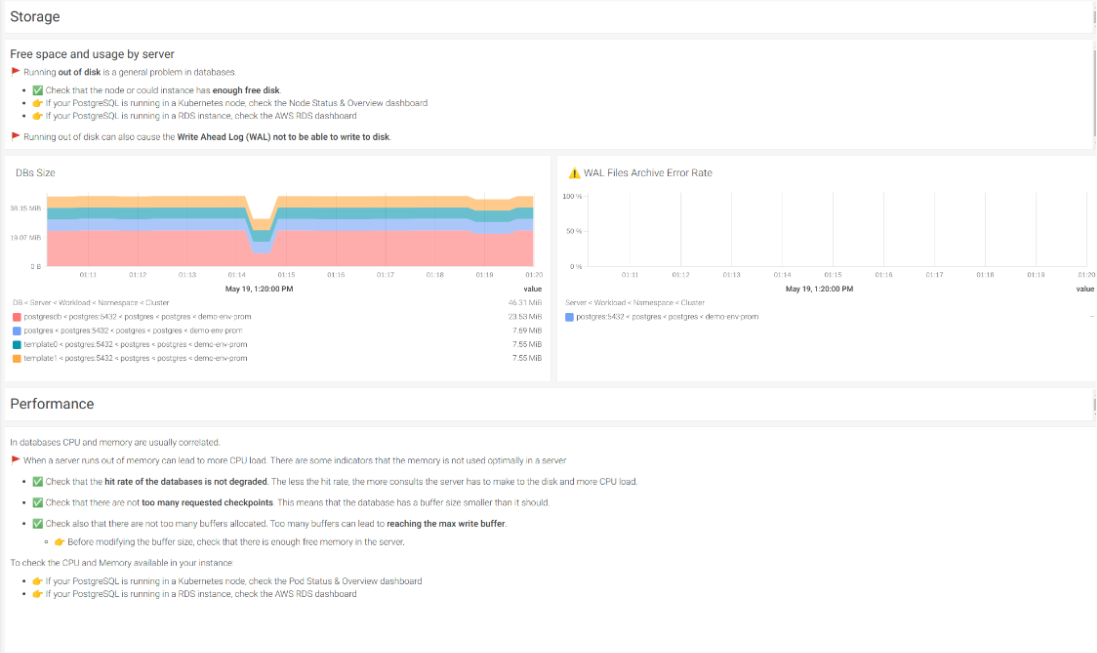
ストレージ
ディスクが足りなくなることは、すべてのデータベースに共通する問題です。また、Write Ahead Log (WAL)がディスクに書き込めなくなることもあります。これにより、永続的なデータに影響を与えるトランザクションの問題が発生する可能性があります。
幸いなことに、この問題は非常に簡単に監視することができます。ここでは、データベースのサイズと、使用可能なディスクを確認します。
#4 データベースサイズ
まず、インスタンス内の各PostgreSQLデータベースのストレージ使用量を把握しましょう。そのためには、pg_database_size_bytesというメトリクスを使います。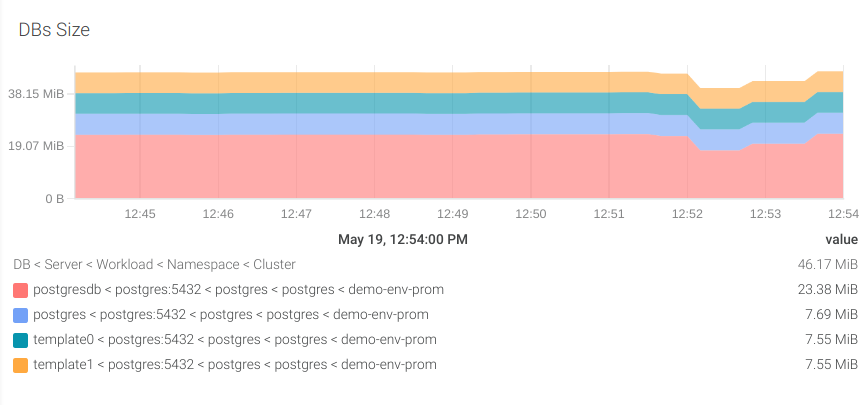
#5 利用可能なストレージ
PostgreSQLインスタンスの運用方法によって異なります。
KUBERNETES
node_exporterからnode_filesystem_free_bytesというメトリクスを使うことができます。PromQLのスタートアップガイドで未来を予測したことを覚えていますでしょうか?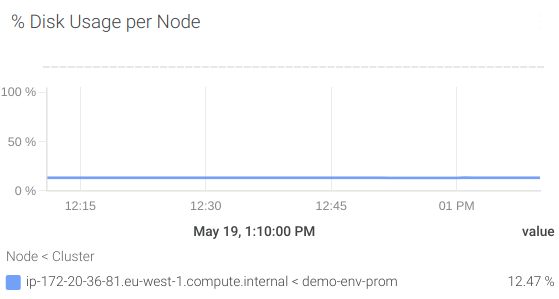
次の24時間で1Gb未満になりそうなときに通知するアラートを作ってみましょう。
predict_linear(node_filesystem_free_bytes[1w], 3600 * 24) / (1024 * 1024 * 1024) < 1
AWS RDS POSTGRESQL
AWS RDSのようなクラウドで管理されたデータベースソリューションは、ますます人気が高まっています。AWS RDSのPostgreSQLインスタンスを実行している場合、CloudWatchとYACEエクスポーターで監視することができます。
aws_rds_free_storage_space_averageというメトリクスを使うことができます。次の48時間でストレージが足りなくなりそうな場合のアラートを作ってみましょう。
predict_linear(aws_rds_free_storage_space_average[48h], 48 * 3600) < 0
ネットワーク
ネットワークのメトリクスを1つだけ残すとしたら、利用可能な接続数にすべきでしょう。
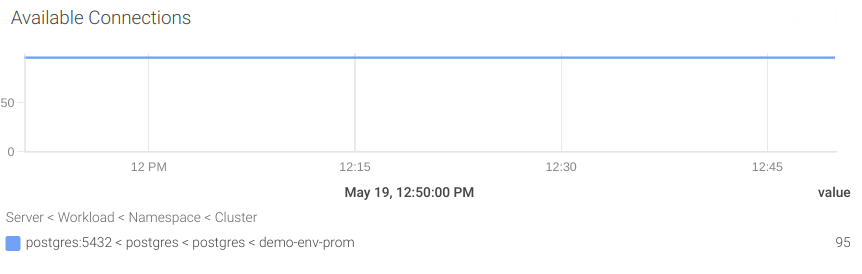
#6 利用可能な接続数
利用可能な接続数は、スーパーユーザの予約済み接続(pg_settings_superuser_reserved_connections)とアクティブな接続(pg_stat_activity_count)を最大接続数(pg_settings_max_connections)から差し引くことで計算します。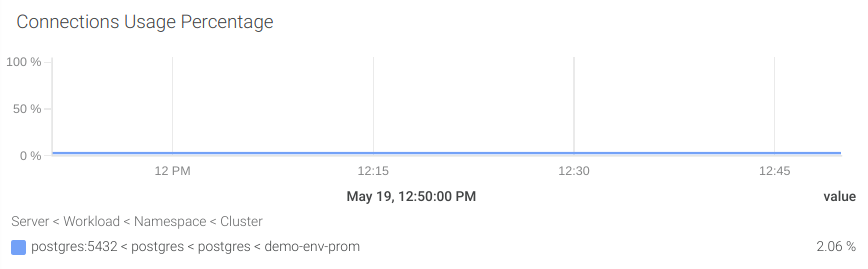
利用可能な接続数が全体の10%を下回った場合に通知するアラートを作成してみましょう。
((sum(pg_settings_max_connections) by (server) - sum(pg_settings_superuser_reserved_connections) by (server)) - sum(pg_stat_activity_count) by (server)) / sum(pg_settings_max_connections) by (server)) * 100 < 10
パフォーマンス
データベースのパフォーマンスをチェックするには、CPUとメモリを監視する必要があります。
サーバのメモリが不足すると、CPUの負荷が大きくなります。幸いなことに、メモリの使用量を最適化する必要がある場合、いくつかのメトリクスが警告を発します。
#7 レイテンシー
まず、最も遅いアクティブなトランザクションから結果を得るためにどれだけの時間がかかるかを計算することで、パフォーマンスを測定します。そのためには、pg_stat_activity_max_tx_durationメトリクスを使用します。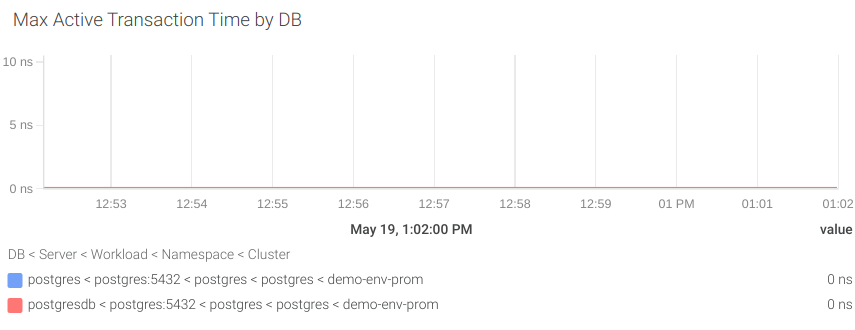
アクティブなトランザクションが完了するのに2秒以上かかったときに通知するアラートを作成してみましょう。
pg_stat_activity_max_tx_duration{state="active"} > 2
#8 キャッシュヒット率
低遅延は、メモリ内のキャッシュに問題があるため、ディスクの使用量が増加し、すべてが遅くなります。
キャッシュヒット率を分析するために、メモリ上のトランザクション(pg_stat_database_blks_hit)と、ディスク上のトランザクション(pg_stat_database_blks_read)をチェックします。
キャッシュヒット率が80%を下回った場合のアラートを作成してみましょう。
#9 使用可能なメモリ
ヒット率が低い場合の解決策は、インスタンスのメモリ使用量を増やすことです。しかし、潜在的なメモリの制限があるため、常にこれが可能とは限りません。そこでまず、十分な空きメモリがあるかどうかを確認する必要があります。
KUBERNETES
インスタンスで利用可能なメモリの合計(kube_pod_container_resource_limits{resource=”memory”})と、使用中のメモリ(container_memory_usage_bytes{container!=”POD”,container!=””})を組み合わせることができます。
これらのメトリクスを使用して、利用可能なメモリの合計を取得するPromQLを書いてみましょう。
sum by(namespace,pod,container)(kube_pod_container_resource_limits{resource="memory"}) - sum by(namespace,pod,container)(container_memory_usage_bytes{container!="POD",container!=""})これらの情報により、インスタンスのメモリ使用量をどれだけ増やせるかを確実にすることができます。
AWS RDS postgresql インスタンス
AWS RDS PostgreSQL を使用している場合、利用可能なメモリスペースを知るのはとても簡単です: aws_rds_freeable_memory_averageメトリクスを使用するだけです!
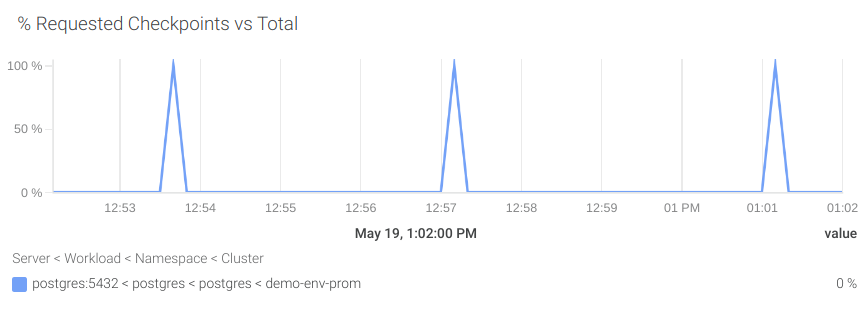
#10 バッファチェックポイントの要求
PostgreSQLは、ダーティなバッファをディスクに書き込むためにバッファチェックポイントを使用します。これらのチェックポイントは定期的にスケジュールされますが、バッファの容量が不足したときにオンデマンドで要求することもできます。
スケジュールされたチェックポイントの数に比べて要求されたチェックポイントの数が多いと、PostgreSQLインスタンスのパフォーマンスに直接影響を与えます。このような状況を避けるためには、データベースバッファのサイズを大きくすることができます。
バッファサイズを大きくすると、PostgreSQLインスタンスのメモリ使用量も増加することに注意してください。前のステップでメモリの使用量を確認してください。スケジュールされたチェックポイントの割合(pg_stat_bgwriter_checkpoints_timed)を、スケジュールされたチェックポイントと要求されたチェックポイントの両方の合計(pg_stat_bgwriter_checkpoints_req)と比較して視覚化するPromQLクエリを作成してみましょう。
rate(pg_stat_bgwriter_checkpoints_req[5m]) / (rate(pg_stat_bgwriter_checkpoints_req[5m]) + rate(pg_stat_bgwriter_checkpoints_timed[5m])) * 100
これは素晴らしいことですが、ところで、PostgreSQL監視ダッシュボードはどこにあるのでしょうか?
この記事では、postgres_exporterを使ったPrometheusによるPostgreSQLモニタリングを紹介しました。自分のPostgreSQLインスタンスをKubernetesで動かしても、AWS RDSのPostgreSQLインスタンスで動かしても構いません。
すでに設定されているPostgresSQL監視ダッシュボードをPromCatからダウンロードして、Grafanaのインストール(またはSysdig Monitor!)に追加することができます。
Sysdigを用いたPostgreSQLの監視
私たちSysdigは、毎日何百人ものお客様のクラスターをサポートしています。その専門知識をアウトオブボックスのダッシュボードでお客様と共有できることを嬉しく思います。適切なダッシュボードを使用すれば、PostgreSQLの監視やトラブルシューティングに専門家である必要はありません。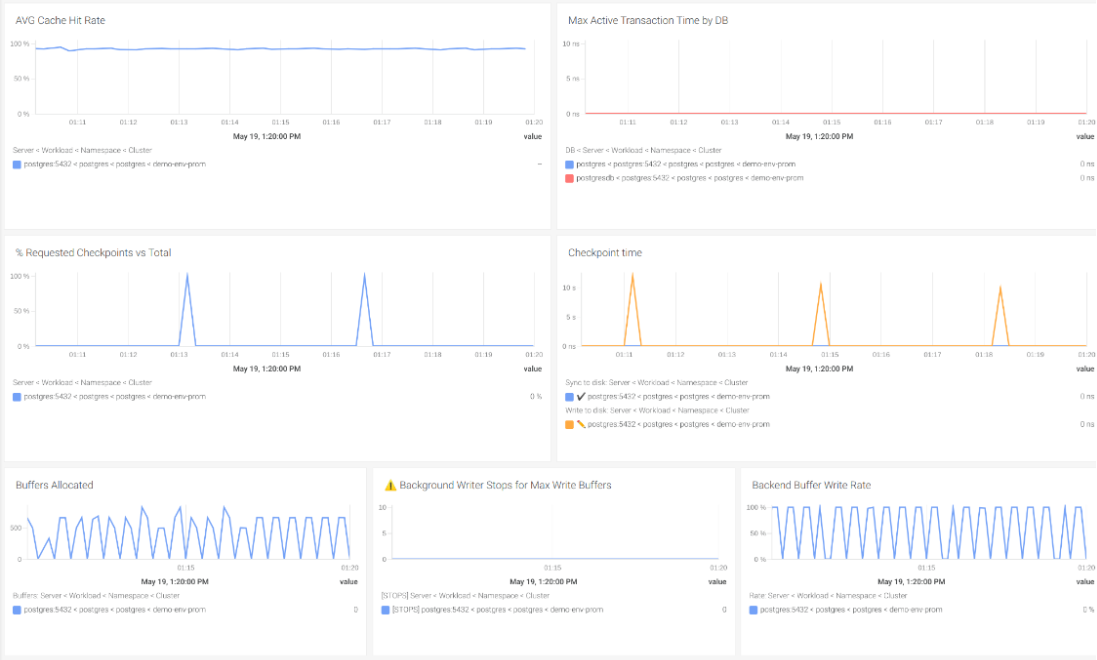
Sysdigのアウトオブボックスのダッシュボードでは、PostgreSQLインスタンスの健全性、ゴールデンシグナル、およびトラブルシューティングガイドを1つのガラス窓に表示します。
また、Sysdig Monitorの無料トライアルにサインアップして、アウトオブボックスKubernetesのダッシュボードをお試しいただけます。