

本文の内容は、2023年3月30にVICTOR HERNANDO が投稿したブログ(https://sysdig.com/blog/troubleshooting-application-issues)を元に日本語に翻訳・再構成した内容となっております。
Kubernetesにおける問題のトラブルシューティングは、多くの工数がかかります。このような問題を診断する場合、大量のマイクロサービスを確認することになります。しかし、複雑な問題に対処する場合、何度も行き来することで多くの時間を失う可能性があります。時間は、何事も炎上したときの貴重な資源にも関わらず、です。
Sysdig Agentは、eBPFを活用してきめ細かな遠隔測定を行っています。Kubernetesクラスターからメトリクスを取得するだけでなく、カーネルからリアルタイムでシステムコールをキャプチャーしてインサイトを取得します。このデータは、新しいメトリクスの生成や他のメトリクスの充実のために使用されます。その結果、アプリケーションのメトリクスは、Kubernetesとクラウドのコンテキストを得ることができるようになりました。
拡張ラベルは、クラスターで何が起こっているかをより広く可視化し、ビジネス・メトリクスとKubernetesおよびクラウドの貴重なデータを相関させ、コンテナ内のどのアプリケーション・プロセスがノイズを出しているかについての洞察を得ることができるようになります。Sysdigでは、アウトオブボックスで提供されるメトリクスエンリッチメントのおかげで、これらすべてのこと、そしてもっと多くのことを行うことができます。
もっと詳しく知りたいですか?Sysdigの拡張ラベルが問題のトラブルシューティングにどのように役立つのか、ぜひご覧ください。
拡張ラベルを活用し、問題のトラブルシューティングを行う
Sysdig Advisorは、Sysdig Monitor のトラブルシューティングの仕組みであり、Kubernetes環境における問題のトラブルシューティングを支援します。パフォーマンス関連のメトリクスだけでなく、Kubernetesのオブジェクト、ステータス、イベント、Podからのログなど、多くの情報を見つけることができます。問題の根本的な原因を見つけるために必要なものは、すべてAdvisorにあります。
このトラブルシューティングの使用例では、トラブルシューティングの演習の出発点としてSysdig Advisorを使用します。ここでは、問題そのものに関する手がかりを簡単に得ることができます。たとえば、関係するアプリケーションはどれか、問題はいつ始まったか、問題の手がかりとなるKubernetesイベントはあるか、すべてのPodでレポートされたアプリケーションログはあるか、などです。複雑な問題に対処する場合、メトリクス拡張ラベルを利用してさらに深く掘り下げる必要があるかもしれません。このトラブルシューティングでは、この機能がいかに強力であるか、それが提供する膨大な可能性、そしてSysdig Monitorでこれらのラベルをどのように活用するかを見ていきます。
私たちのKubernetesクラスターでは、デフォルトのネームスペースでいくつかのマイクロサービスが稼働しています。これらのアプリケーションには独自の依存関係がありますが、今回の使用例では、これらの関係について言及する価値はありません。では、本題に入りましょう!
Sysdig Advisorのコンソールで異常な動作が検出されました。次の画像でわかるように、レイテンシーが急上昇しています。アプリケーションの1つが何らかの問題に直面しているようで、レイテンシーが突然増加し始めたのです!😱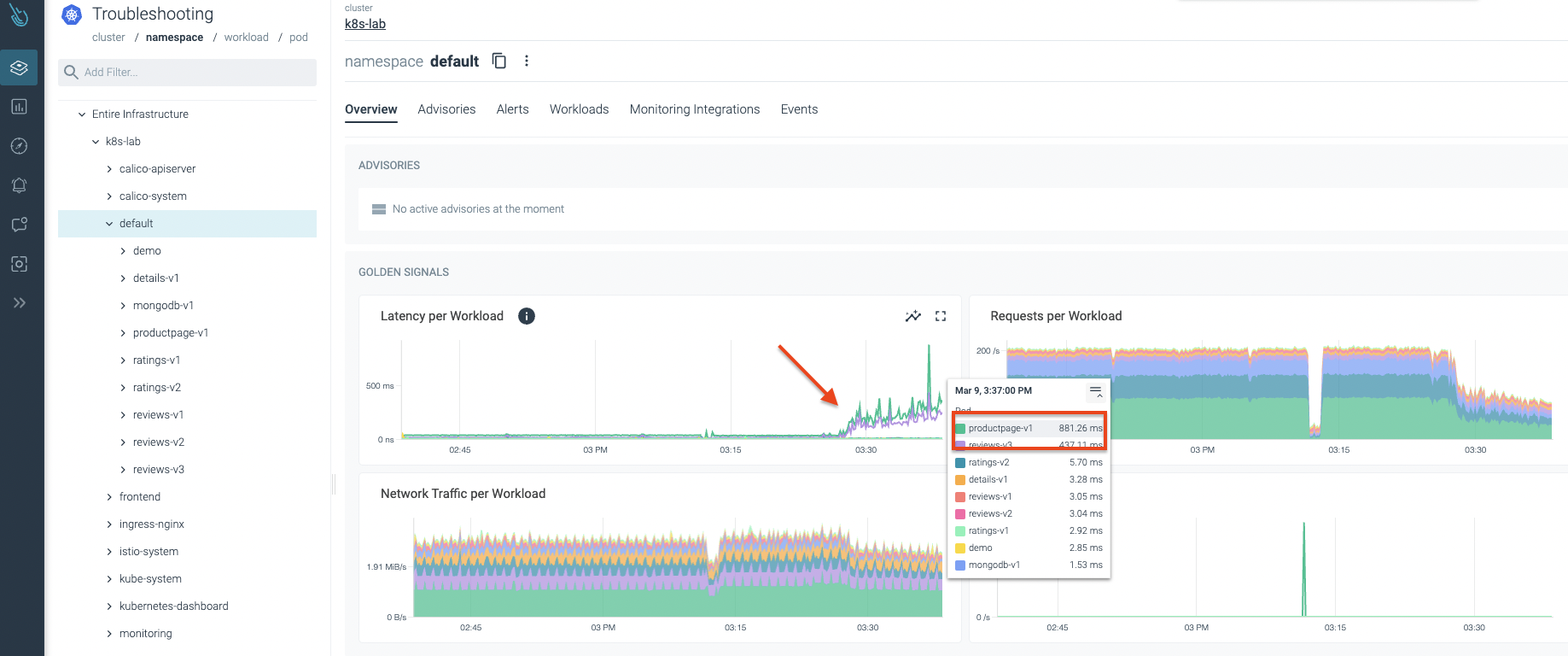
デフォルトのネームスペースをもっと掘り下げてみよう。問題が発生していると思われるワークロードのレビューを開始します。次の画像で確認できるように、このワークロードには潜在的な問題があることが確認できます。レイテンシーが大きくなり、トラフィックがドロップされるのは良いことではありません。😞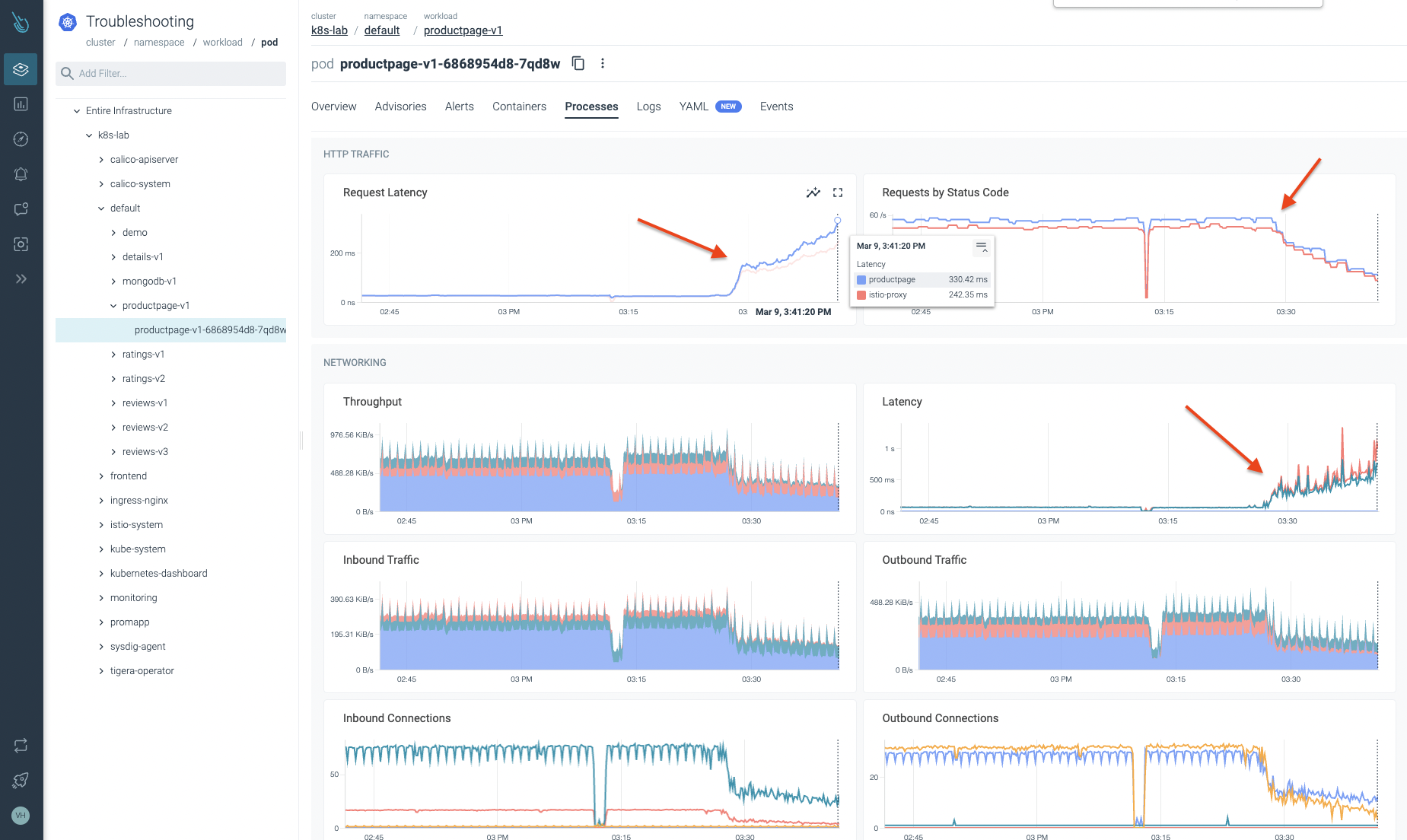
この記事で紹介したように、SysdigはKubernetesノードやクラウド環境からメトリクスを取得するだけでなく、eBPFを活用してSyscallsからカーネルデータを取得します。このデータを引き出した後、Sysdigエージェントはこれらの情報を結合してメトリクスにします。
今回は、ネットワークコンテナ検査用のSysdigメトリクスの1つであるsysdig_container_net_in_bytesを使用します。このメトリクスは、そのスコープのインバウンド・ネットワーク・バイト数を提供します。次の画像でわかるように、レイテンシーが大きくなり始めると同時に、ネットワーク・トラフィックが減少していることを確実に確認できます。メトリクスエンリッチメントのおかげで、すぐにわかるように、 kube_deployment_name, kube_pod_name, container, kube_replicaset_name, kube_workload_name,<span> </span>kube_workload_typeなど、貴重な情報を得ることができます。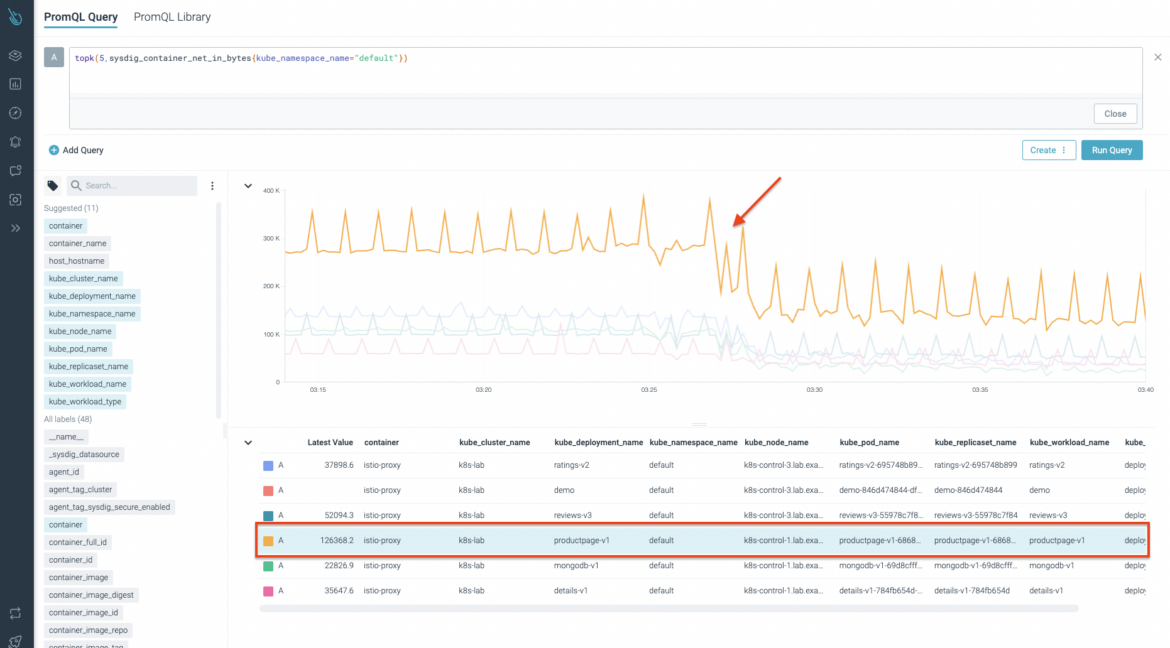
次に、 sysdig_program_net_in_bytes メトリクスを使用します。このメトリクスは、特定のコンテナの実行中のプロセス詳細である cmd_lineのような、さらなる情報を提供します。次の図では、一番上の結果が productpage-v1ワークロードに属し、より具体的にはenvoyプロセスであることがわかります。
このようなネットワーク問題の犯人を見つける必要があります。そのために、より一般的なメトリクスであるsysdig_connection_net_in_bytes を使用します。そうすることで、より広い範囲をチェックすることができます。イベントを関連付けるために必要な拡張ラベル( cmd_line, net_client_ip, net_local_endpoint, net_protocol, and net_remote_endpointなど)を賢く選択する必要がある。
下の画像では、一番上の結果は、promapp アプリケーションで実行されている curl プロセスに属することがわかります。Sysdigがアウトオブボックスで提供する拡張ラベルのおかげで、ソースIP、リモートIP、ポートを簡単に特定することができます。
私たちは、productpage-v1 サービスのネットワーク問題を引き起こしている問題のあるコンテナとそのプロセスを発見しました!🥳
promapp Podでcurlのプロセスが動いているかどうか確認してみましょう。はい!このプロセスは productpage-v1 サービスに大量のトラフィックを送っている犯人です。
root@promapp:/go# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 11:41 ? 00:00:03 /bin/prometheus-example-app
root 15 0 0 14:12 pts/0 00:00:07 /bin/bash
root 17725 15 0 14:59 pts/0 00:00:00 /bin/bash
root 17740 17725 0 14:59 pts/0 00:00:00 curl -s -o /dev/null http://192.168.119.31:30296/productpage
root 17741 15 0 14:59 pts/0 00:00:00 ps -ef
そのサービスを担当しているチームと話し合った結果、そのpromapp アプリケーションの再作成にゴーサインが出ました!その間に、彼らはそのサービスを検査し、修正するために手を動かしています。
ほらね!promapp Podを再作成した後、すべてが正常に戻ったようです。
まとめ
この記事では、アプリケーションのトラブルシューティングのための拡張ラベルの重要性について学びました。Sysdigがアウトオブボックスで提供するメトリクスエンリッチメントのおかげで、メトリクスはKubernetesとクラウドのコンテキストを得ることができます。コンテナ内で実行されているプロセス、デプロイ名、その他のKubernetesおよびクラウドラベルなどの情報は、Kubernetesで問題をトラブルシュートする際に重要な鍵となります。
Sysdig MonitorがKubernetesクラスターの監視とトラブルシューティングにどのように役立つかをもっと知りたい方は、30日間のトライアルアカウントをリクエストして、実際に試してみてください。数分で起動し、実行することができます!
2025年版クラウドネイティブセキュリティおよび利用状況レポート:企業はどのようにセキュリティを進化させているのか?
レポートを読む
2024 Gartner®️ Market Guide for Cloud Native Application Protection Platforms (CNAPP) Market Guide
詳細はこちら
2024年版Sysdigのグローバル脅威レポートが公開されました!
レポートを入手
Sysdig Sageのご紹介:初の会話型AIクラウドセキュリティアナリスト
さらに詳しく
Sysdig Secureに新しくCloud Identity Insightsが登場
さらに詳しく
ガートナー® VOCレポートでお客様がSysdig CNAPPを最上位と評価しました
さらに詳しく