
本記事での脆弱性評価と脆弱性管理のベストプラクティスを実施することで、インフラの攻撃対象を減らすことができます。
私たちは人間であり、私たちが作るものの多くは完璧ではありません。だからこそ、私たちは車を定期的に点検したり、製品が安全に使用できることを認証する機関があるのです。
それはソフトウェアも同じです。
この10年でソフトウェアは複雑化し、私たちは新機能よりもエラー修正を伴うような絶え間ないアップデートに慣れてしまいました。
ソフトウェアのエラーには、よくある厄介なバグから、一般ユーザーがインターネット全体を停止させる力を持ってしまうようなエッジケースまで、さまざまなものがあります。また、ソフトウェアのエラーには脆弱性が含まれていることが多く、設定ミスと相まって、インフラ全体を危険にさらす可能性があります。
最近では、脆弱なコンテナを悪用して、クラウドのアカウント全体を危険にさらすラテラルムーブメント攻撃を可能にする方法を紹介しました。また、CRI-OとPodmanに存在するCVE-2021-20291は、悪意のあるアクターが細工したイメージをリポジトリに置いた場合、ホストを完全に停止させることができることを紹介しました。
ソフトウェアの脆弱性は避けられないものだとしたら、それに対して何かできることはないのでしょうか。
以下の10の脆弱性評価と脆弱性管理のベストプラクティスに沿うことで、あなたのインフラストラクチャーは潜在的な攻撃にさらされる可能性が低くなり、新たに発見された脆弱性によってアプリケーションの提供に支障をきたすこともなくなるでしょう。
1. イメージスキャンによる脆弱性の評価と管理
脆弱性が自社のインフラにどの程度の影響を与えているかを評価する前に、また、脆弱性を管理するためのアクションプランを構築する前に、どのような脆弱性があるかを知る必要があります。このプロセスを可能にするツールが自動イメージスキャンです。
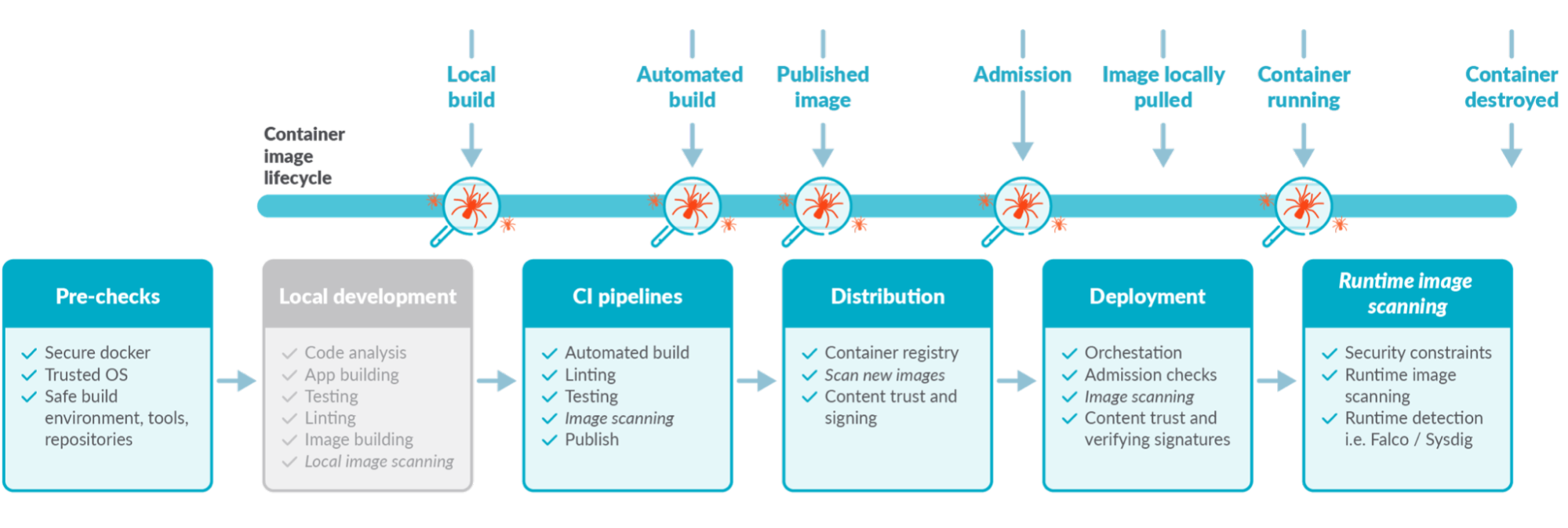
本番環境にデプロイするすべてのものをスキャンし、既知の脆弱性データベースと比較することで、どのような脆弱性が影響しているのかを把握することができます。これは、セキュリティ態勢を評価するための最初のステップです。
時々、イメージスキャンのベストプラクティスを見直すと良いでしょう。結局のところ、イメージスキャンがより深く掘り下げられれば、発見された脆弱性の評価と管理がより簡単になります。例えば、スキャナーはイメージのメタデータだけを見ているのか、それともイメージに含まれるサードパーティのライブラリもチェックしているのか?
2. 脆弱性が本番環境に到達するのを防ぐ
イメージのスキャンが脆弱性評価の基本であることには同意しましたが、次の問題は、いつスキャンを実行するべきかということです。答えは、いつでも可能なかぎりです。
脆弱性の検出が早ければ早いほど、行動も早くなり、修正も容易になります。
開発者がソフトウェアを書いている最中に警告を受ければ、すぐに対処することができ、脆弱性が本番環境に到達することはありません。
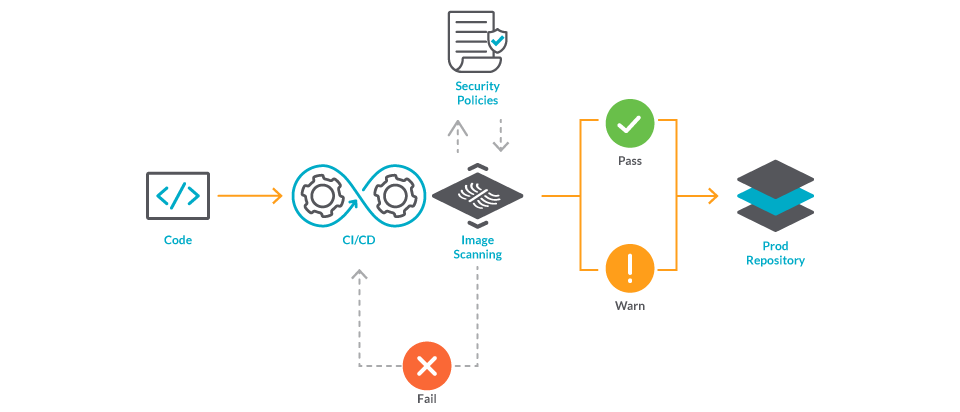
Harborのように、コンテナイメージのレジストリの中には、レジストリから直接イメージをスキャンしてくれるものもあります。さらにセキュリティを強化するために、スキャンに合格しなかったイメージを引き出せないようにサービスをブロックすることもできます。
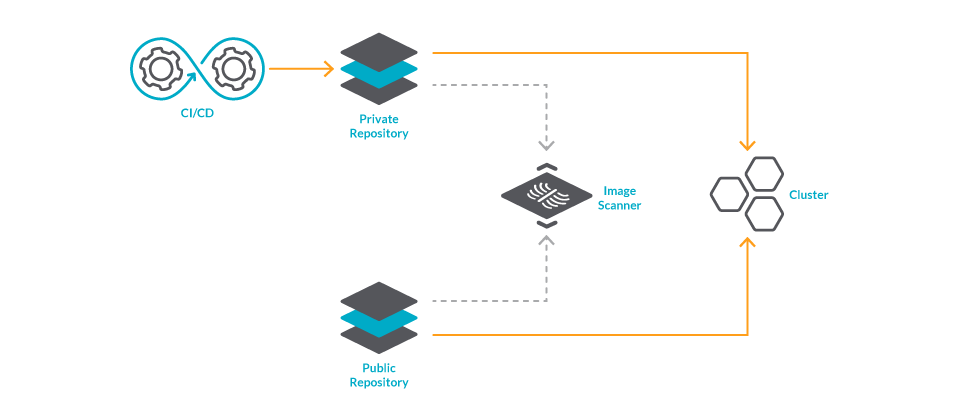
最後に、外部リポジトリからデプロイされたイメージをカバーするために、Kubernetesのアドミッションレベルでイメージスキャンを行うこともできます。
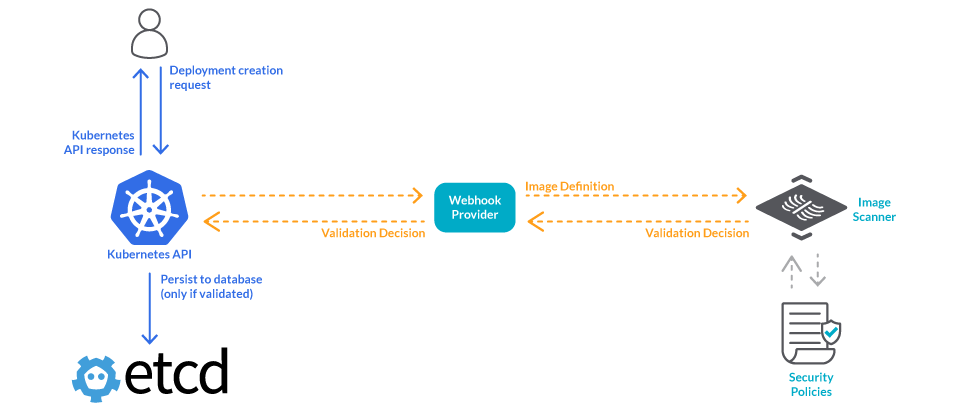
3. 新しい脆弱性をキャッチアップする
既知の脆弱性が本番環境に到達するのを防ぐために、イメージスキャンをどのように利用できるかを説明しました。しかし、まだ公表されていない脆弱性についてはどうでしょうか?
ランタイムワークロードを継続的にスキャンすることで、新たに発見された脆弱性を警告することができます。そのため、うまくいけば悪用される前に修正プログラムを導入することができます。
イメージスキャンはランタイムセキュリティに取って代わるものではないことに留意してください。脆弱性の発見には時間がかかります。それまでは、ランタイムの異常な動作を検出することによってのみ、脆弱性を軽減することができます。これについては後ほど説明します。
4. クラウドタスクをスキャンする
Fargateや新しく導入されたAWS App Runnerのようなサーバーレスサービスがトレンドになっています。これらのサービスを活用することで、チームはインフラをあまり気にせずにコンテナをデプロイすることができます。そうすれば、チームは本当に重要なこと、つまり新機能をより早く提供することに集中できます。マネージドサービスであれば、セキュリティを気にする必要はないと考える人もいるかもしれません。しかし、それは真実からかなり離れています。この例では、脆弱なコンテナによってラテラルムーブメントが可能になり、クラウドのアカウント全体が危険にさらされるというシナリオがあります。
クラウドプロバイダーは、共有責任モデルに基づいて運営されています。そのため、プロバイダーは基盤となるサービスのセキュリティを確保し、MeltdownやSpectreのような低レベルの脆弱性に対する修正プログラムを提供します。一方、ユーザーは、そのサービス上にデプロイするアプリケーションのセキュリティを確保します。ECS Fargateの脅威モデリングを確認することで、このテーマをより深く掘り下げることができます。
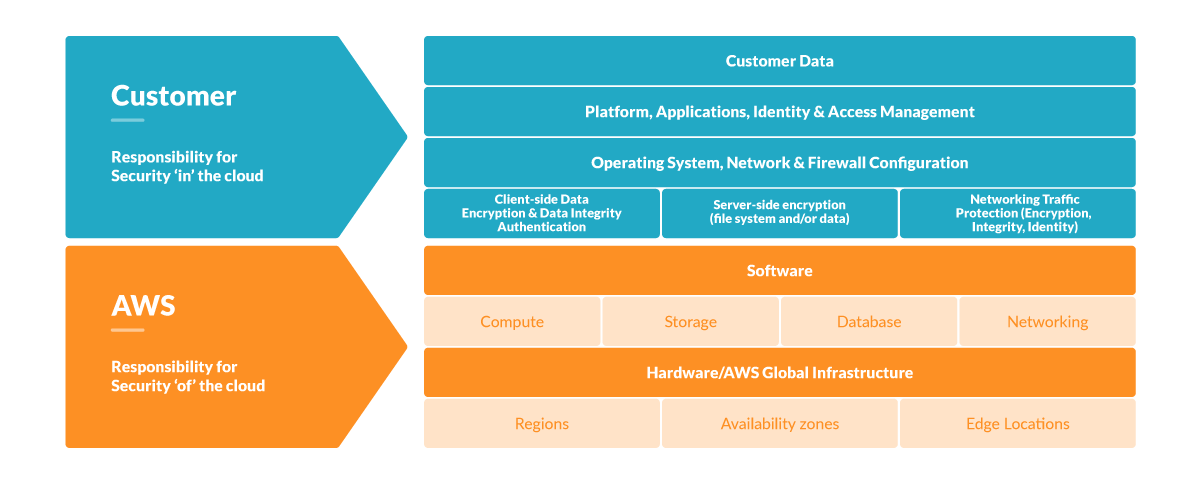
CI/CDパイプライン経由であれ、コンテナレジストリからであれ、サーバーレスサービスにデプロイするクラウドタスクをスキャンすることは、脆弱性管理のベストプラクティスです。
5. 脆弱性評価の一環としてホストスキャンを忘れずに
コンテナを実際に稼働させているホストのことを忘れてしまうのは簡単です。結局のところ、コンテナへのアクセスは高度に保護されており、ホスト上の脆弱性を悪用することはほぼ不可能です。その結果、チームがコンプライアンス検証のボックスをチェックするためだけに、ホストスキャンを実施しているのをよく見かけます。スキャンの結果を脆弱性の評価と管理のプロセスに組み込まないと、ホストスキャンは役に立たなくなります。
次の2つのシナリオを念頭に置いてください。
- 攻撃者は、1つのコンテナを侵害した後、コンテナから脱出できる脆弱性を探し、脱出に成功すると、ホストの脆弱性を利用してクラウドのラテラルムーブメントを行い、インフラ全体を侵害する可能性があります。
- CRI-OやPodmanのCVE-2021-20291のように、ホストにアクセスしなくても悪用できる脆弱性もあります。細工したイメージをレジストリにアップロードするだけで、影響を受けたホストに対してDoS攻撃を成功させることができます。
Sysdig Secureは、イメージ・スキャンとホスト・スキャンを統合し、修正を迅速化することで、インフラ全体のコンプライアンスを簡単に検証することができます。また、導入も非常に簡単です。
詳しくはデモをご覧ください→
6. 脆弱性の評価と管理のためのグローバルポリシーの定義
脆弱性には様々な種類がありますが、それら全てをブロックすべきでしょうか?グローバルポリシーがないと、重要な脆弱性への対応に時間がかかりすぎたり、重要でない脆弱性にリソースを使いすぎたりします。
脆弱性に優先順位をつけるために使用できる主なメトリクスは、報告された重大度です。
重大度の低い脆弱性は見逃すが、重大度が中よりも高い脆弱性を含むすべてのイメージをデプロイメントからブロックすることを決めることができます。
しかし、ランタイムワークロードに影響を与える脆弱性についてはどうでしょうか?
運が良ければ、しばらくの間、そのサービスを停止することができるかもしれません。しかし、すぐにサービスを停止できない場合は、いくつかの緩和策を実施することができます。例えば、ネットワークポリシーのようなツールを使って脆弱なサービスをさらに隔離したり、独自のクラスターに移動させたりすることができます。また、ランタイムセキュリティポリシーを導入して、脆弱性が悪用されたときに検出することもできます。
報告されている脆弱性のスコアだけでなく、その脆弱性が実際にどのような影響を及ぼすのかを評価する必要があります。中程度の重大度の脆弱性であれば、非常に特殊で珍しい設定が必要になるかもしれません。しかし、たまたまそのような設定をしてしまった場合、その脆弱性の重大度はあなたにとって重大なものになるかもしれません。
そして最後に、開発プロセスの一部をポリシーでカバーすることです。
dockerfileのベストプラクティスを導入することで、コンテナの攻撃対象を大幅に減らすことができます。例えば、ubuntu:xenial-20210114のイメージには約100個の脆弱性が含まれており、それをベースにしている他の人にも継承されている可能性があります。
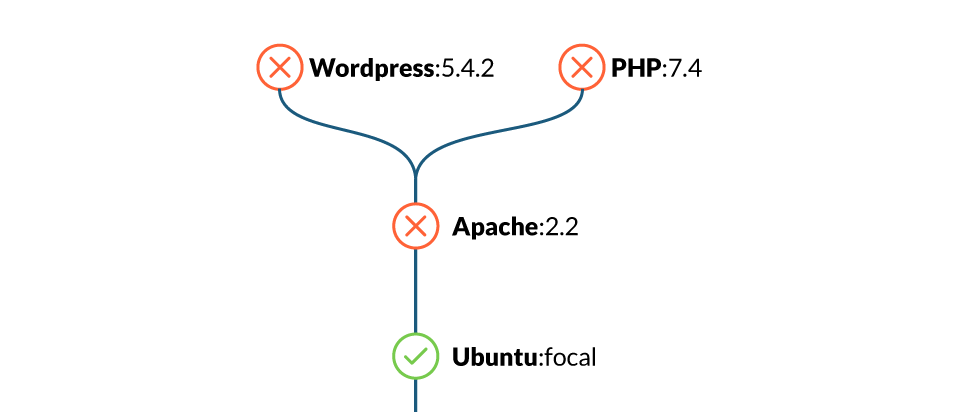
全社的に独自のディストロレスイメージを構築すれば、2つのメリットが得られます。
- 必要なものだけを搭載することで、ベースイメージから引き継がれる脆弱性の数を大幅に減らすことができる。
- ベースイメージを再利用することで、脆弱性が発見された場合、影響を受けるすべてのイメージを一度に修正することができます。
- デプロイメント前の脆弱性をどのように扱うか。いつブロックするか?いつパスするか?
- ランタイムの脆弱性をどのように扱うか。いつKillするか?隔離するには?
- 脆弱性のあるサービスを隔離するには?
- 攻撃対象を減らし、応答時間を短縮するための開発手法。
- 全社的なベースイメージの使用など。
- バージョニング戦略を定義する。
7. 脆弱性管理プロセスの一環としてアップデートを含める
脆弱性の修正として最も一般的なのは、新しいバージョンにアップデートすることです。しかし、しばらくの間アップグレードしていなかった場合、バージョン間で導入されたかもしれない破壊的な変更に対処するための顕著な開発努力を意味することがあります。
また、会社の方針として、このようなアップデートをスムーズに行うために、ソフトウェアのバージョン管理をどのように行うかということがあります。そのようなポリシーでは、以下のことをカバーする必要があります。
誰もがどのバージョンを使うべきか:ライブラリ、アプリケーション、ベースイメージのいずれについても、全員が同じバージョンを使用していれば、脆弱性を容易に把握することができ、修正プログラムを全員が同時に適用することができます。
いつアップデートすべきか:最新バージョンがリリースされたらすぐにアップデートしたくないという気持ちは理解できます。しかし、アップグレードしないと、1年前のライブラリをデプロイすることになり、チームの技術的負債を増やすことになります。
自信を持ってアップグレードできるように、いくつかのガイドラインを定義する必要があります。例えば、次のようなものです。
- セキュリティパッチがリリースされたらすぐに適用する。
- マイナーリリースのアップグレードは、リリースから2週間後に行う。
- メジャーリリースのアップグレードは、リリースから1ヶ月後に行う。
これは、Kubernetesのようにリリースが頻繁で、コアコンポーネントに大きな変更が加えられているような新しい技術では、より困難なことです。
Kubernetes 1.19からは、サポート期間が1年間に延長されました。最新のバージョンにアップグレードすれば、1年間はセキュリティアップデートを適用しても、変更が壊れる心配はありません。
このような取り組みにより、アップデートを開発プロセスに組み込むことが容易になります。例えば、1年のうち最も忙しくない月を選び、その月をソフトウェアコンポーネントのアップグレードと技術的負債への対処の両方に充てることができます。
8. 脆弱性評価と管理レポートを有用なものにする
脆弱性の棚卸しを行うことと、実際にそれを修正することの間には大きなギャップがあります。情報をどのように提示し、共有するかによって、このギャップをいかに早く、効率的に解消するかが決まります。経験則では、脆弱性について適切な人に通知するのに、あまりにも多くの時間や労力を要する場合、機会を逃していることになります。
重要な脆弱性については、できるだけ早く適切なチームに警告したいものです。
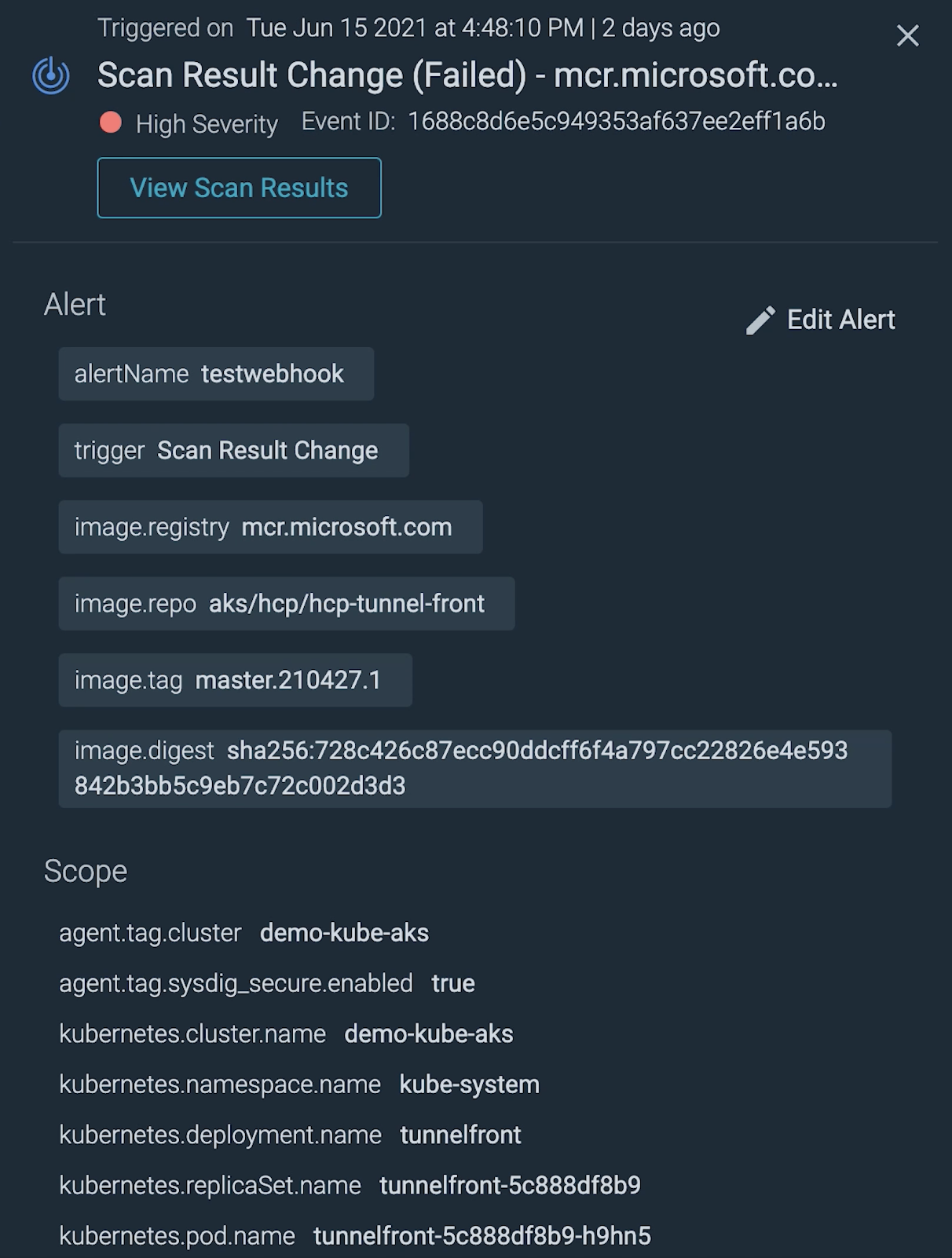
アラートを有用にするためのベストプラクティスをいくつか紹介します:
- 雑音を避ける:すぐに注意を払う必要のある項目についてのみアラートを出す。
- 特定の目標であること:行動を起こす必要のある人にのみ警告する。
- 適切なチャネルを使用する:あなたのチームは、緊急のメールを時間内に読むことができないかもしれません。
- コンテキストを提供する:どのイメージが影響を受けるか、どのネームスペースか、どのクラウドタスクかなど、必要な情報がすべてアラートに含まれていれば、重要な時間を節約できます。

レポートの内容は、完全かつ詳細であることが望まれます。
完全であれば、複数のスプレッドシートやツールを使い分けることなく、インフラ全体のコンプライアンスを検証することができます。
また、チーム、サービス、クラウドアカウントごとに脆弱性を簡単にグループ化し、どこから行動を開始すべきかを判断するのに役立つよう、十分な粒度が必要です。
例えば、各チームに週次レポートを提供し、修正を計画するのに必要な情報を含むすべての資産を統合することができます。
レポーティングに関しては、ツールの意見が通りすぎることがあります。レポーティングツールからは、コンプライアンス要件のボックスをチェックするだけでなく、何か役に立つことが得られることを確認してください。
また、レポートを作成するために複数のツールを使って何時間も作業していては、レポートの意味がありません。すべての脆弱性を統合するツールや、使用している他のツールとうまく連携するツールを探しましょう。
9. 脆弱な設定を警告する
すべてのソフトウェアの脆弱性にパッチを当てたとしても、構成がドアを開けたままであれば意味がありません。脆弱な構成をチェックし、警告することは、脆弱性評価のベストプラクティスです。
ほとんどのイメージスキャナーは、ポートの露出や認証情報の漏洩をチェックすることができます。これらの機能を活用してください。
静的構成がコードリポジトリで管理されている場合、ソフトウェアの他の部分と同じQAプロセスを通過することができます。レビュープロセスを経ずに設定を変更することは避けてください。
また、クラウドサービスの場合は、cloud custodianのようなツールを活用して、S3バケットが一般にアクセスできるようになっているなど、設定ミスを警告することができます。
ネットワークセキュリティは、サービスを隔離し、悪意のあるアクターがラテラルムーブメントを阻止するための主要なツールであるため、特に注意が必要です。ネットワーク設定の変更を監視することに特に注意してください。
10. 脆弱性の悪用に備える
この記事では、脆弱性管理の限界について何度か取り上げました。まだ発見されていない脆弱性や、まだ修正されていない脆弱性、さらには脆弱な構成など、うまくいかないことはたくさんあります。幸いなことに、マイクロサービスの動作はわりと予測可能なので、脆弱性が悪用されたときには簡単に発見することができます。それは、あなたがそれを探している場合です。
ランタイムセキュリティツールはシステムイベントを読み取ることができるので、コンテナ上でシェルがスポーンしたり、新しいプロセスがスポーンしたり、設定が変更されたりといった不審な点を検出することができます。
クラウドネイティブなランタイムセキュリティプロジェクトであるFalcoのように、それがKubernetesの脅威検知エンジンのデファクトとなっています。
ですから、ランタイムセキュリティツールを活用すべきです。
さらに一歩進んで、脆弱性管理とランタイムセキュリティツールは、脆弱性が悪用された後に行われるフォレンジック調査を可能にするべきです。
例えば、コンテナの脆弱性が悪用された場合、ランタイムセキュリティツールがそれを検知し、直ちにコンテナをKillして攻撃を阻止するとします。
アラートで通知を受けたとしても、再発防止のためにどうやってインシデントを調査すればよいのでしょうか。結局のところ、コンテナをKillしてしまえば、そのコンテナはもう存在しません。
コンテナに脆弱性があったことがわかれば、調査の範囲を大幅に狭めることができますが、インシデントを再現するには実際の証拠が必要です。そのためには、セキュリティツールの以下の機能が役立ちます。
システムアクティビティの取得:ランタイムセキュリティツールは、システム上で何が起こっているかを追跡するために、システムイベントに依存しています。いくつかのツールは、さらに進んで、セキュリティイベントの前後の時間にそれらのイベントを記録することができます。これにより、攻撃者がどのプロセスを実行したか、どのファイルを変更したか、どのようなネットワーク活動があったかを知ることができます。
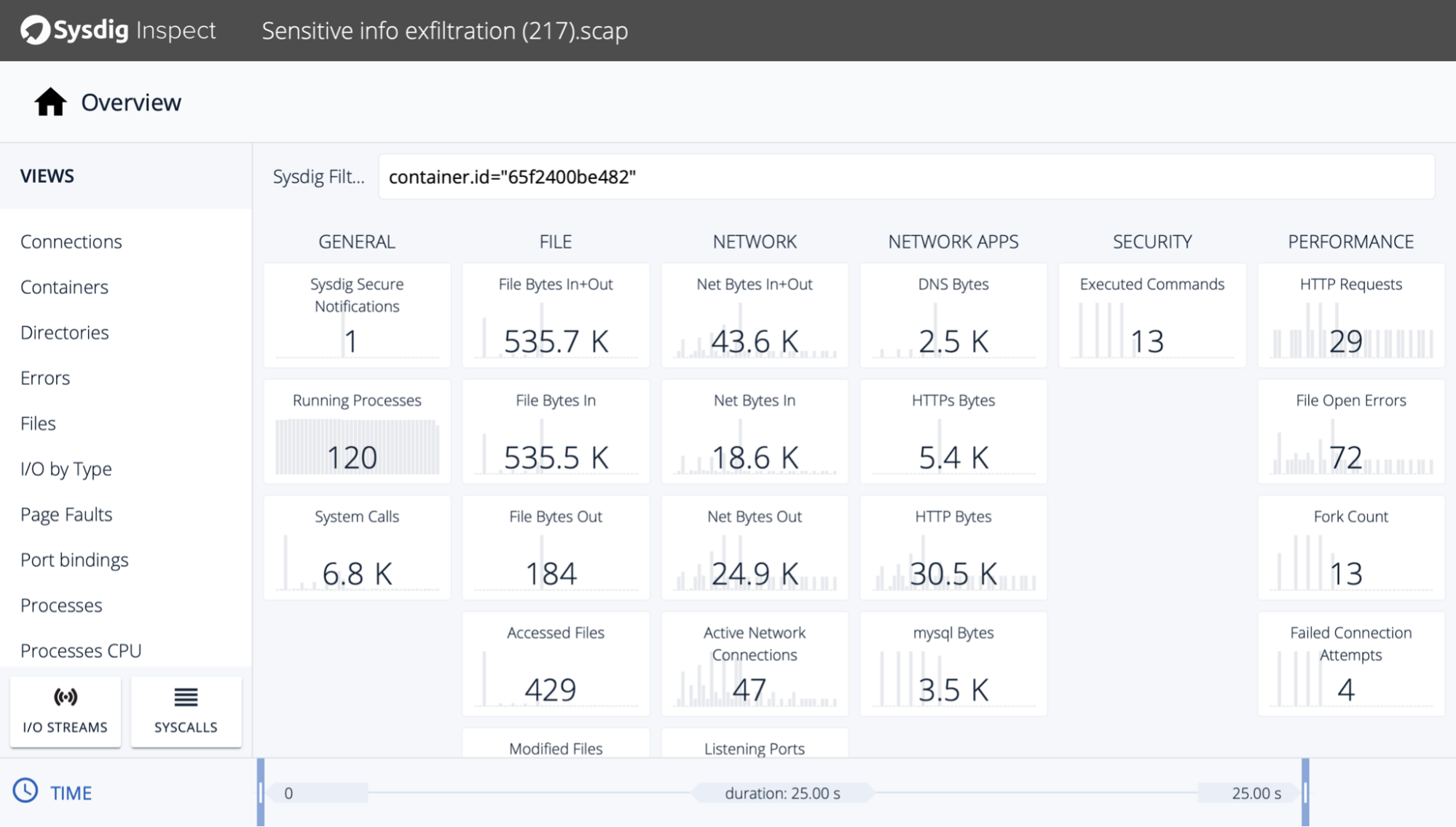
アクティビティの監査:イベントを調査するために、マシンのすべてのシステムアクティビティを必要としない場合があります。ワークロードごとに別々の監査ログを残すことで、ノイズの少ない補完が可能になります。特定のコンテナの監査ログをチェックした後、ギャップを埋める必要がある場合は、システムイベントキャプチャーにジャンプすることができます。

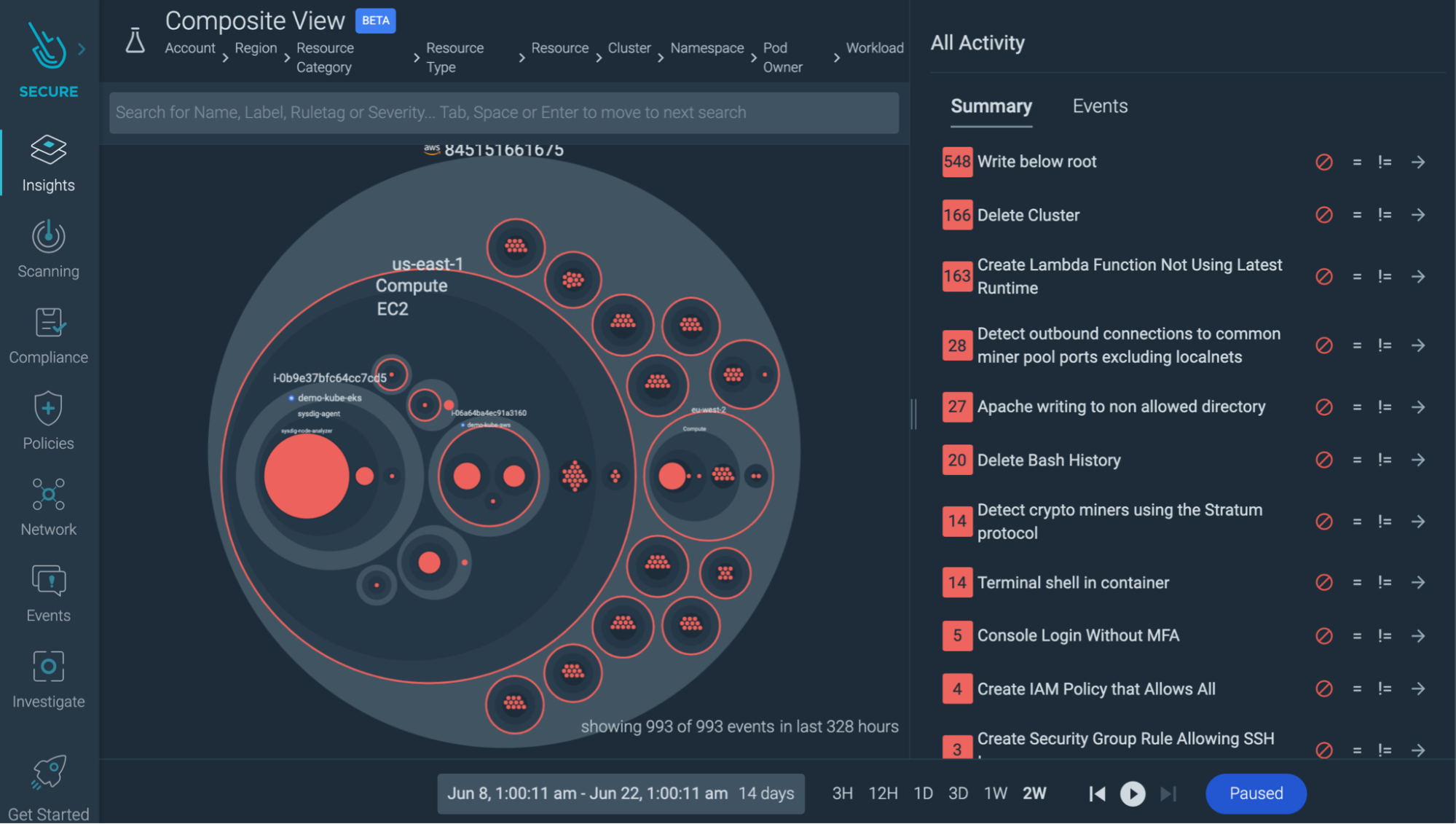
相関性のあるデータ:クラウドやマイクロサービスの世界では、インシデントが単独で発生することはほとんどありません。コンテナ内で実行されているクリプトマイナーを見つけて、そのコンテナをKillして、その日は終わりにするかもしれません。
しかし、インフラ全体のセキュリティイベントを1つのオーバービューで見ることができれば、攻撃の直前に、開発者の1人が多要素認証なしで認証していたこともわかるかもしれません。漏洩したのは単なるコンテナではなく、ユーザーの認証情報だったのかもしれません。このようにして、調査は新たな局面を迎えます。
設定ミスとセキュリティイベントとの関連付けを支援するツールを探してみてください。
まとめ
ソフトウェアは完璧ではなく、それがセキュリティ問題を引き起こします。ありがたいことに、イメージスキャンやその他のベストプラクティスにより、脆弱性の影響を軽減することができます。脆弱性をブロックするだけでは必ずしも十分ではありませんので、ランタイムセキュリティにも注意してください。
また、全体的に、生活を楽にしてくれるセキュリティツールを探しましょう。より優れたレポートと迅速な対応は、セキュリティインシデントがトレンドトピックになるかどうかの分かれ目になります。
Sysdig Secureによる脆弱性評価と脆弱性管理の実現
Sysdig Secureは、イメージスキャンとホストスキャンを統合することで、修正を迅速化し、インフラ全体のコンプライアンスの検証を容易にします。また、導入も非常に簡単です。Sysdig Secure for Cloudでは、悪意のある人が侵入する前に、クラウドの設定ミスに継続的にフラグを立てたり、流出した認証情報からの異常なログインなどの疑わしいアクティビティを検出したりすることができます。これらはすべて単一のコンソールで実行されるため、クラウドのセキュリティ態勢を簡単に検証することができます。しかも、わずか数分で始められます。
Sysdig Free Tierで無料でクラウドのセキュリティ対策を始めましょう!
https://www.youtube.com/watch?v=tT0sDT5eivM