
Red Hat OpenShiftの監視には、Vanilla Kubernetesディストリビューションと比較して課題が発生します。Sysdig Monitorを使うことで、OpenShiftにおける独自機能が、どのようにあなたの問題を迅速かつ容易に監視し、トラブルシュートするのに役立つか、その方法をご覧ください。
OpenShiftは、Kubernetesの基盤に多くのアウトオブボックスのアドオンを構築しています。例えば、OpenShift APIサーバー、Controller Manager、Ingress、またはMarketplaceエコシステムなどです。これが、より複雑な環境を生み出し、あなたが苦労する原因となってしまいます。
Sysdig Monitorは、この複雑さに秩序をもたらします。すぐに使えるダッシュボードで、Prometheusのメトリクスにアラートを設定できるようになります。また、Advisorの高度なトラブルシューティング機能は、隠れた問題を浮き彫りにし、スピーディに問題を解決することができます。
この記事では、以下のトピックを取り上げます:
- OpenShift監視スタック
- なぜSysdig Monitorなのか?
- Sysdig MonitorでOpenShiftクラスターをより効率的に監視する方法
- Sysdig MonitorでOpenShiftの問題をトラブルシュートする方法
OpenShift監視スタック
OpenShiftは、Kubernetesのオープンソースディストリビューション上に構築されたKubernetesのエンタープライズソリューションです。これには、すぐに使用できる他のコンポーネントが含まれており、OpenShift を顧客の間で最も人気のあるディストリビューションの 1 つにしています。また、OpenShiftは、市場をリードするディストリビューションの1つであり、広く採用され、上流プロジェクトのOKDを介したコミュニティのサポートに依存しています。
OpenShiftは、独自の監視スタック(一般にOpenShift Monitoringとして知られている)をすぐに利用でき、基本的な監視機能をカバーしています。
この監視スタックは、オープンソースプロジェクトをベースにしています:
- 時系列データを保存するためのバックエンドとしてPrometheus
- アラームを処理し、通知を送信するためのAlertmanager
- グラフ形式でデータを表現するためのGrafana
OpenShiftの監視は、インストール時にデフォルトでデプロイされ、Cluster Monitoring Operatorで管理されます。
ユーザーは、OpenShiftコンソールから直接、またはPrometheus UIにログインして、監視データにアクセスできます。
免責事項:以下のスクリーンショットは、OpenShift 4.9のバージョンに対応しています。オプション、グラフ、その他の情報は、将来のバージョンで変更される可能性があります。
OpenShiftコンソールは、OpenShiftクラスターステータスの簡単な要約、最近のイベントに関するいくつかの情報、および他のデータの中でリソースの消費量を表示するいくつかの小さなグラフを表示します。
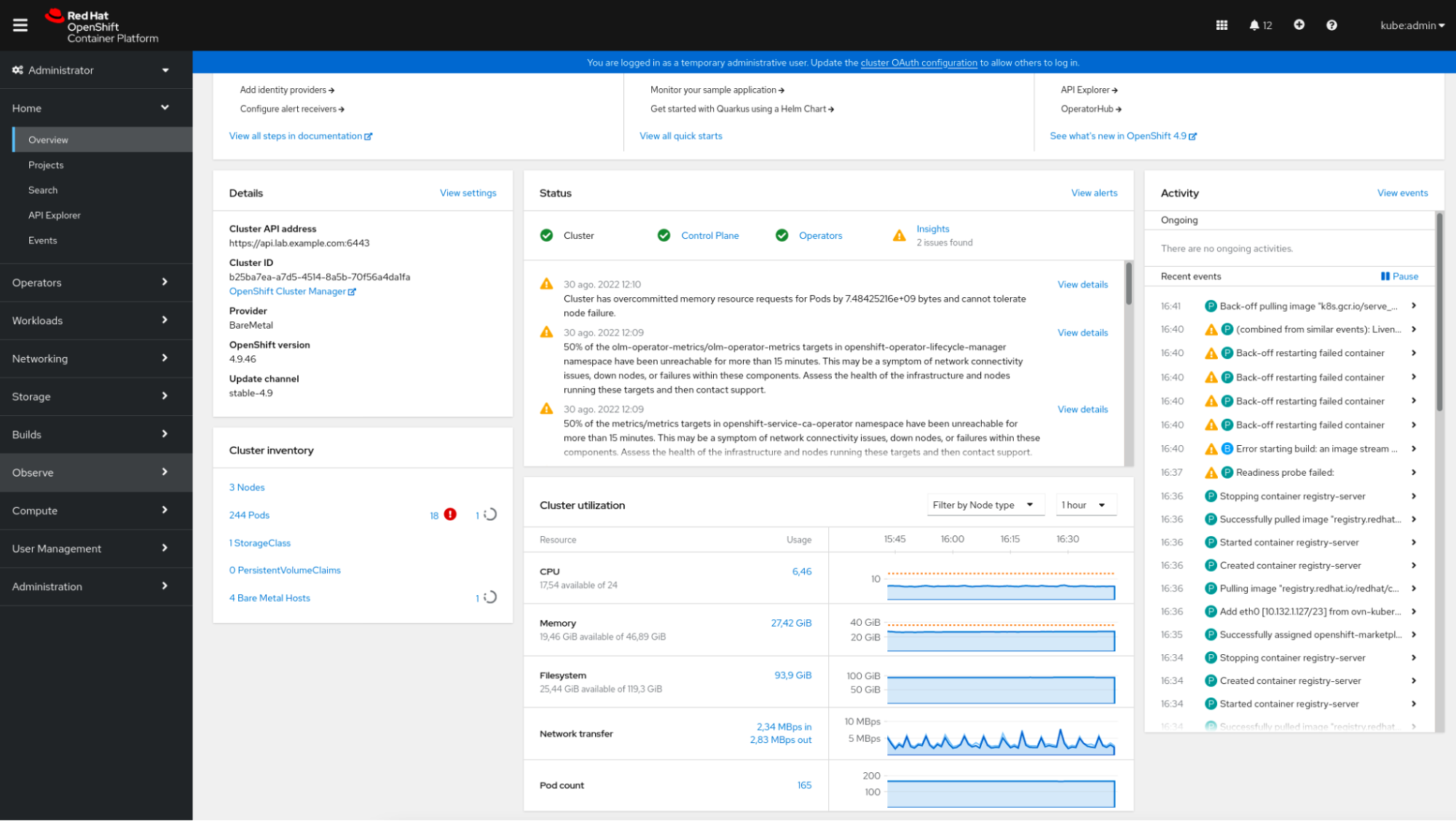 OpenShift コンソール
OpenShift コンソールOpenShiftコンソールは、Prometheusと統合されています。これは、ユーザーが独自のクエリーを実行できる”メトリクス”セクションを提供します。
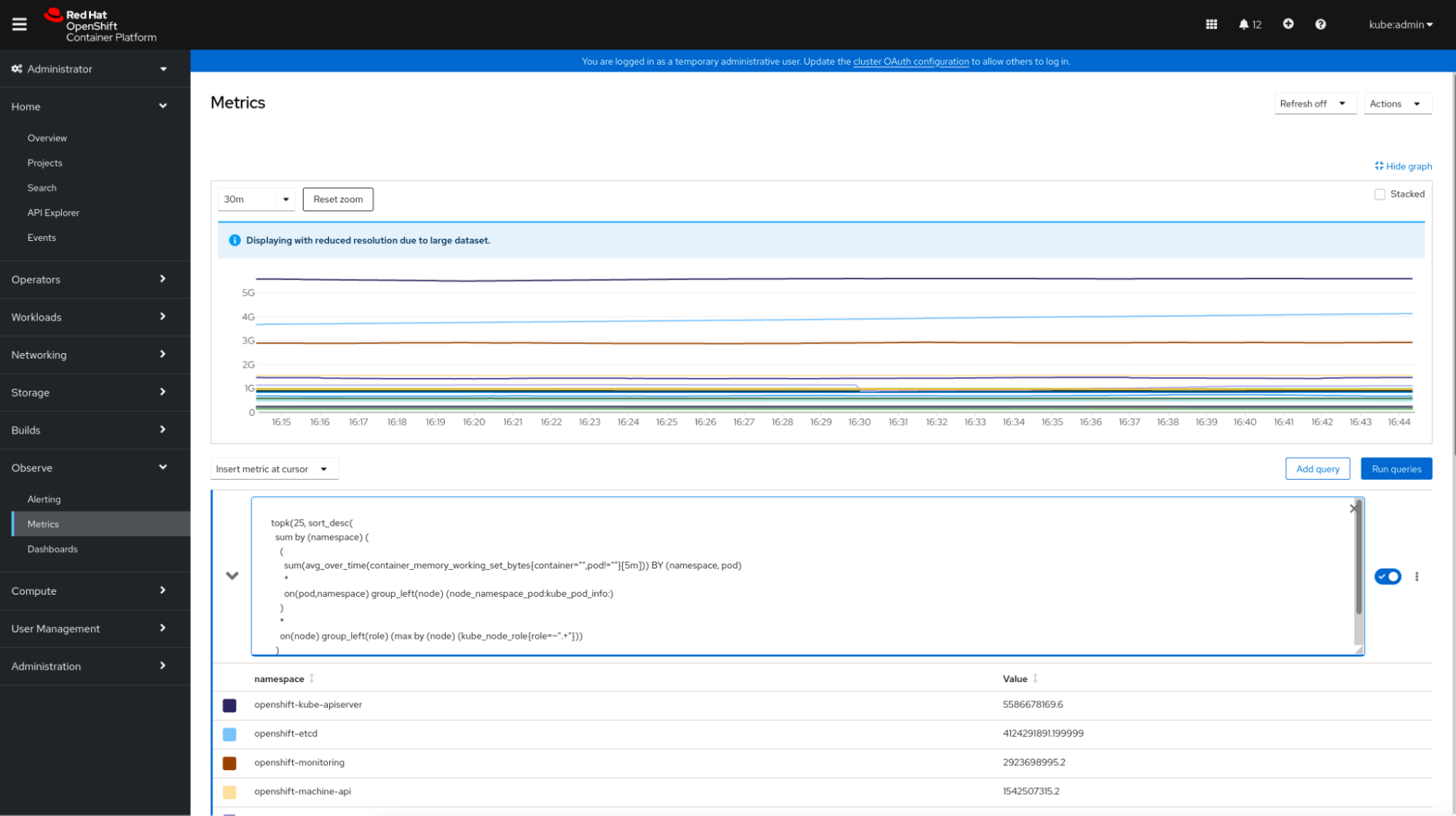 OpenShiftのメトリクスpromql
OpenShiftのメトリクスpromqlメトリクスの可観測性という点では、OpenShiftは独立してアクセスできるGrafanaインターフェースの他に、コンソールで統合されたダッシュボードビューを提供します。
これらのデフォルトダッシュボードとPrometheusによってスクレイピングされた関連データは、コンソール自体で確認することができます。”Observe”→”Dashboards”をクリックし、目的のダッシュボードを選択するだけです。
この例では、etcdメトリクスダッシュボードがどのように表現されるかを示しています。
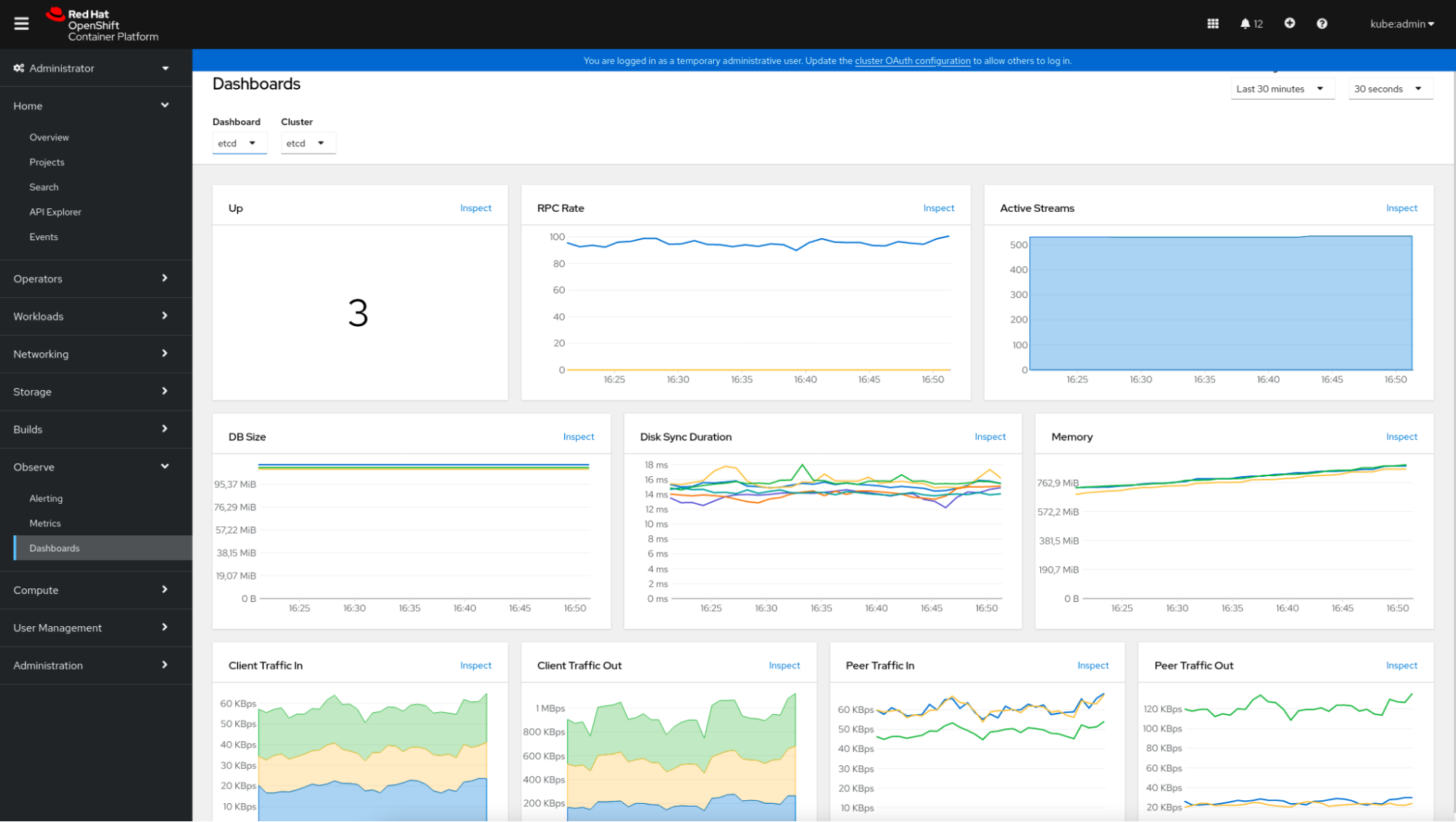 OpenShiftのメトリクスダッシュボード
OpenShiftのメトリクスダッシュボード最後に、OpenShift は、Alertmanager に基づくアラート システムを提供します。 この Alerting セクションで、管理者は OpenShift に含まれるデフォルトのアラート ルールを表示およびサイレンシングできます。OpenShiftでは、
PrometheusRule CRD(Custom Resource Definition)を介して、お客様が定義したプロジェクトに対して新しいアラートルールを作成することができます。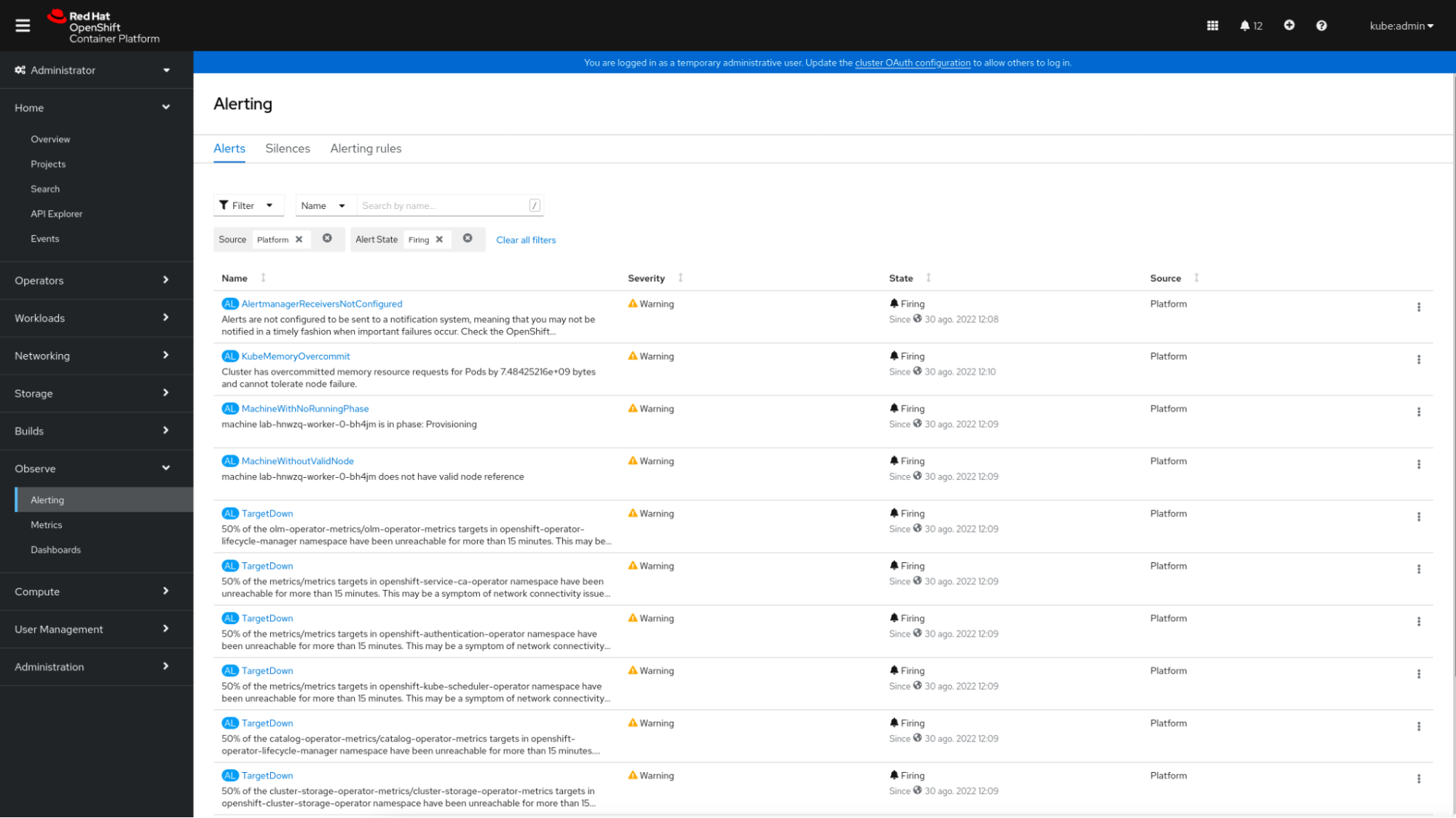 OpenShiftのアラート
OpenShiftのアラートなぜSysdig Monitorなのか?
OpenShiftの利用者であれば、そもそも論として「OpenShiftがすでに独自の監視ツールを提供しているのに、なぜSysdig Monitorを使用する必要があるのか?」という疑問を持たれるかもしれません。この疑問は、この記事の次のセクションで詳しく説明しますが、Sysdig MonitorをOpenShiftクラスターの監視と問題のトラブルシューティングのための優れたツールとして位置づける強力なポイントの下記に言及します。
- Sysdig Advisorは、優先順位付けされた問題リスト、ライブログ、YAMLビュー、ガイド付き修正手順により、OpenShiftの問題をより速くトラブルシューティングすることを支援します。
- Sysdigエンジニアリングチームが作成・監修した広範なダッシュボードライブラリーは、Sysdigエージェントをデプロイした後、数分でデータを表示します。
- 自動キャプチャーによりアクティビティデータを保存し、あらゆるコンテナイベントの事後分析が可能です。
- 事前定義されたアラートはクラスター全体で利用可能であり、お客様のニーズに合わせてカスタマイズすることも可能です。
- Exploreでは、Sysdig MonitorのフォームベースのUIやPromQLを使って、すべてのメトリクスを表示できます。
- サードパーティソフトウェアを統合します。Sysdig Monitorは、他のベンダーのソフトウェアを検出し、統合のプロセスをガイドします。
- キャパシティと利用率のダッシュボードは、プロビジョニングの不足または過剰な領域を特定するのに役立ちます。
- 単一のツールで、すべてのクラスターとクラウド環境を一箇所で監視することができます。
- スケーラブルなSaaSベースのソリューションであるため、Prometheusのスケーラビリティや長期保存について心配する必要はありません。これらの重要なポイントは、すでにSysdigがカバーしています。
Sysdig MonitorでOpenShiftを監視する方法
Sysdig Monitorは、Kubernetesのコントロールプレーンコンテナとお客様のワークロードの両方から、Prometheusの時系列データ、ログ、イベントを取り込みます。データ収集は、クラスター内のすべてのKubernetesノードにデプロイされた軽量エージェントによって実行されます。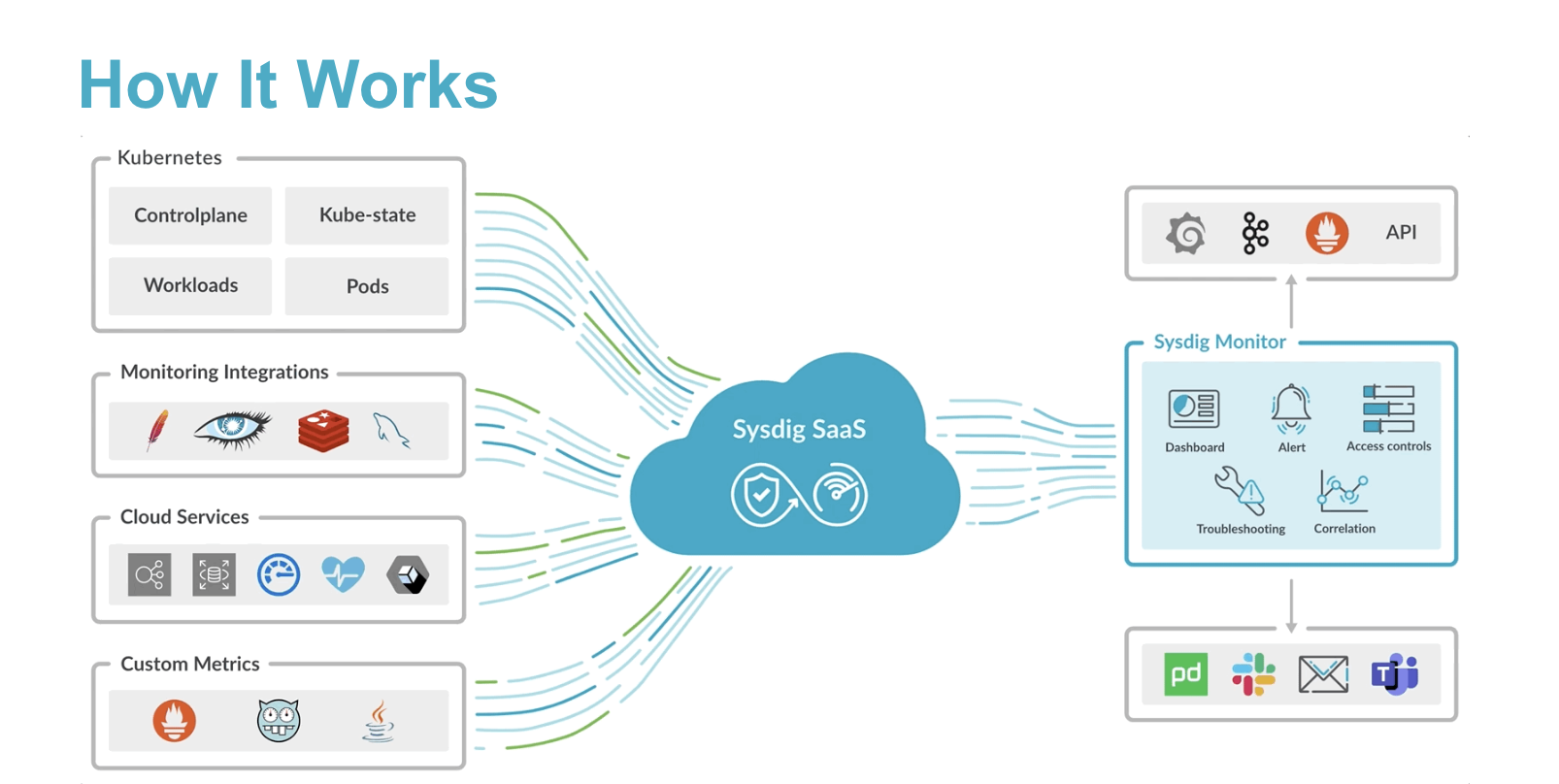 Sysdig Monitor、その仕組みは?
Sysdig Monitor、その仕組みは?Sysdigエージェントのインストールは、以下のように簡単です:
- Sysdigエージェントをインストールする(手動でいくつかのyamlファイルを適用するか、helmを使用する)。
- Sysdigエージェントをインストールし、ホストのシステムコールとPrometheusの時系列データを収集させます。
- Sysdig Monitor の out-of-the-box ダッシュボードでクラスターの状態をチェックし始めます。
エージェントの詳細については、この舞台裏のブログポストをご覧ください。
いかがでしょうか? Sysdig Monitorを試してみたい方は、30日間のトライアルアカウントをリクエストすることができます。30日間、無料ですべての機能を利用することができ、支払い方法の入力は必要ありません。
エージェントのインストール
今回、SysdigエージェントはSysdig-deploy helm chartを使用してインストールされます。エージェントのデプロイ方法について詳しく知りたい方は、Sysdig Monitorにログインして、”Get Started “をクリックしてください。
以下のインストール手順は、12.8.0 エージェントイメージを含むagent helm chart 1.5.19 をデプロイする sysdig-deploy helm chart 1.3.8 を使用して OpenShift 4.9.46 でテストされたものです。Sysdigの公式ドキュメントには、Sysdigエージェントをデプロイする手順が記載されていますので、最新版の手順を確認するためにご覧ください。
$ kubectl create ns sysdig-agent
$ helm repo add sysdig https://charts.sysdig.com
$ helm repo update
$ helm install sysdig-agent --namespace sysdig-agent \
--set global.sysdig.accessKey=aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee \
--set agent.sysdig.settings.collector=ingest-eu1.app.sysdig.com \
--set agent.sysdig.settings.collector_port=6443 \
--set global.clusterConfig.name=<CLUSTER_NAME> \
sysdig/sysdig-deployhelmでデプロイすると、数分でPodがいくつか立ち上がるはずです。
$ oc get pods -o wide ipibm-installer.lab.example.com: Wed Aug 31 13:13:03 2022 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES sysdig-agent-dvz5n 1/1 Running 0 1m 192.168.119.20 ipibm-master-01 <none> <none> sysdig-agent-h66t9 1/1 Running 0 1m 192.168.119.22 ipibm-master-03 <none> <none> sysdig-agent-mvgl8 1/1 Running 0 1m 192.168.119.21 ipibm-master-02 <none> <none> sysdig-agent-node-analyzer-k8wwm 3/3 Running 0 1m 192.168.119.20 ipibm-master-01 <none> <none> sysdig-agent-node-analyzer-v5q8j 3/3 Running 0 1m 192.168.119.21 ipibm-master-02 <none> <none> sysdig-agent-node-analyzer-x6j8b 3/3 Running 0 1m 192.168.119.22 ipibm-master-03 <none> <none>
この瞬間から、これらのコンテナはノードから多くのPrometheus時系列データを収集し、それらのメトリクスをクラウド上のSysdig Monitorサービスに送信しています。
OpenShiftの統合を設定する
エージェントはすでにデプロイされ、ノードからデータを収集しています。素晴らしい!エージェント構成を少し調整する時が来ました。OpenShiftのコントロールプレーンコンポーネントから関連情報をキャプチャーするには、ほんの数分しかかかりません。
以下の構成と手順は、12.8.0エージェントイメージを含むagent helm chart 1.5.19をデプロイするsysdig-deploy helm chart 1.3.8でテストされたものです。これらの手順は将来的に変更される可能性があることに注意してください。最新のSysdig Monitorの統合については、promcat.ioをチェックしてください。
Sysdig-agent ConfigMap の scrape_configs セクションに、以下の新しい Prometheus ジョブを追加してください。
- job_name: control-plane
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: /opt/draios/kubernetes/prometheus/secrets/token
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{sysdig="true"}'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
source_labels: [__meta_kubernetes_pod_host_ip]
regex: __HOSTIPS__
- action: keep
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_pod_name
separator: '/'
regex: 'openshift-monitoring/prometheus-k8s-0'
- source_labels:
- __address__
action: replace
target_label: __address__
regex: (.+?)(\\:\\d)?
replacement: $1:9091
# Holding on to pod-id and container name so we can associate the metrics
# with the container (and cluster hierarchy)
- action: replace
source_labels: [__meta_kubernetes_pod_uid]
target_label: sysdig_k8s_pod_uid
- action: replace
source_labels: [__meta_kubernetes_pod_container_name]
target_label: sysdig_k8s_pod_container_name
- job_name: etcd
honor_labels: true
scheme: https
bearer_token_file: /run/secrets/kubernetes.io/serviceaccount/token
tls_config:
insecure_skip_verify: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"etcd"}'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
source_labels: [__meta_kubernetes_pod_host_ip]
regex: __HOSTIPS__
- action: keep
source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_pod_name
separator: '/'
regex: 'openshift-monitoring/prometheus-k8s-0'
# Holding on to pod-id and container name so we can associate the metrics
# with the container (and cluster hierarchy)
- action: replace
source_labels: [__meta_kubernetes_pod_uid]
target_label: sysdig_k8s_pod_uid
- action: replace
source_labels: [__meta_kubernetes_pod_container_name]
target_label: sysdig_k8s_pod_container_name
# Remove extended labelset
- action: replace
replacement: true
target_label: sysdig_omit_source
metric_relabel_configs:
- action: replace
source_labels: [namespace]
target_label: kube_namespace_name
- action: replace
source_labels: [pod]
target_label: kube_pod_name
- action: replace
source_labels: [endpoint]
target_label: container_nameSysdig Agent Podsを再デプロイして、準備は完了です。
さて、次は何でしょうか?
特に目立ったことはありません。Sysdig Monitorにアクセスし、リージョンを選択し、認証情報を使ってログインするだけです。
Sysdig Monitorでメトリクスを監視する
左のメニューバーには、アドバイザー、ダッシュボード、Explore、アラート、イベント、キャプチャーなどの主要セクションが配置され、すっきりと整理された UI を見ることができます。Sysdig Monitor が提供するすべてのダッシュボードの中から、いくつかのダッシュボードをレビューしてみましょう。
EtcdはKubernetesで最も重要なコンポーネントの1つです。Sysdig MonitorでOpenShiftを監視することで、お客様はEtcdがどのように動作しているかを完全に可視化することができます。
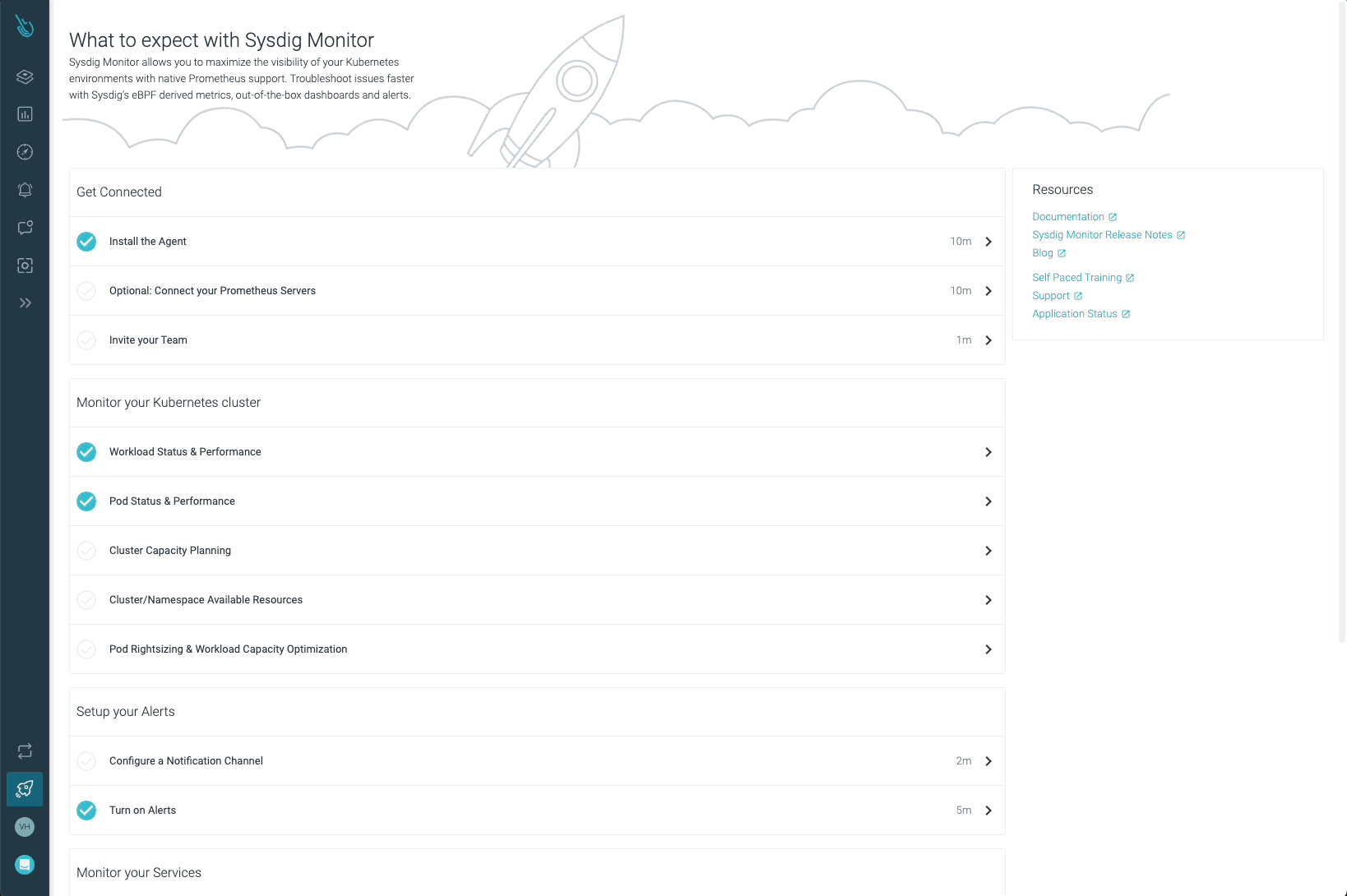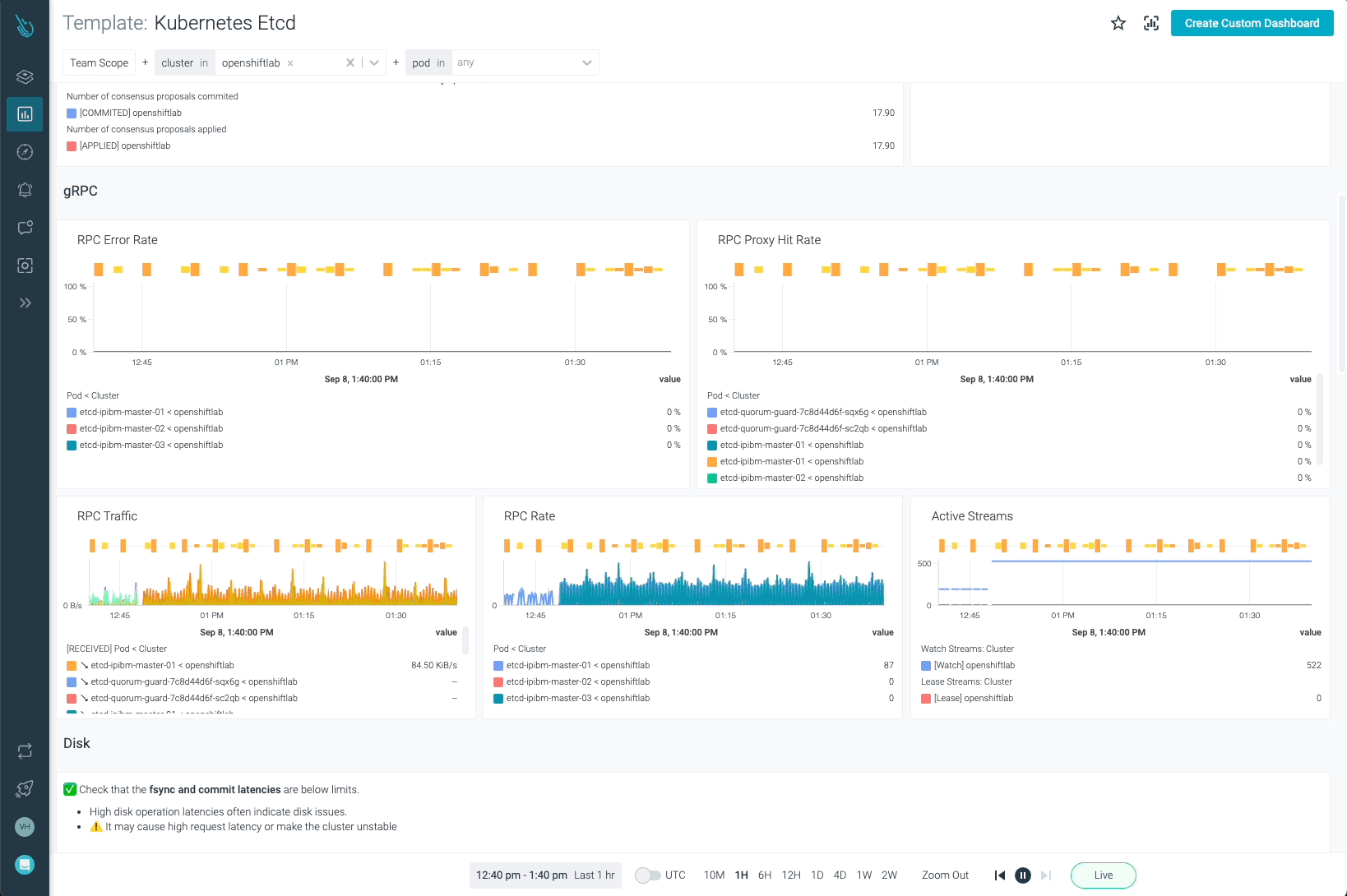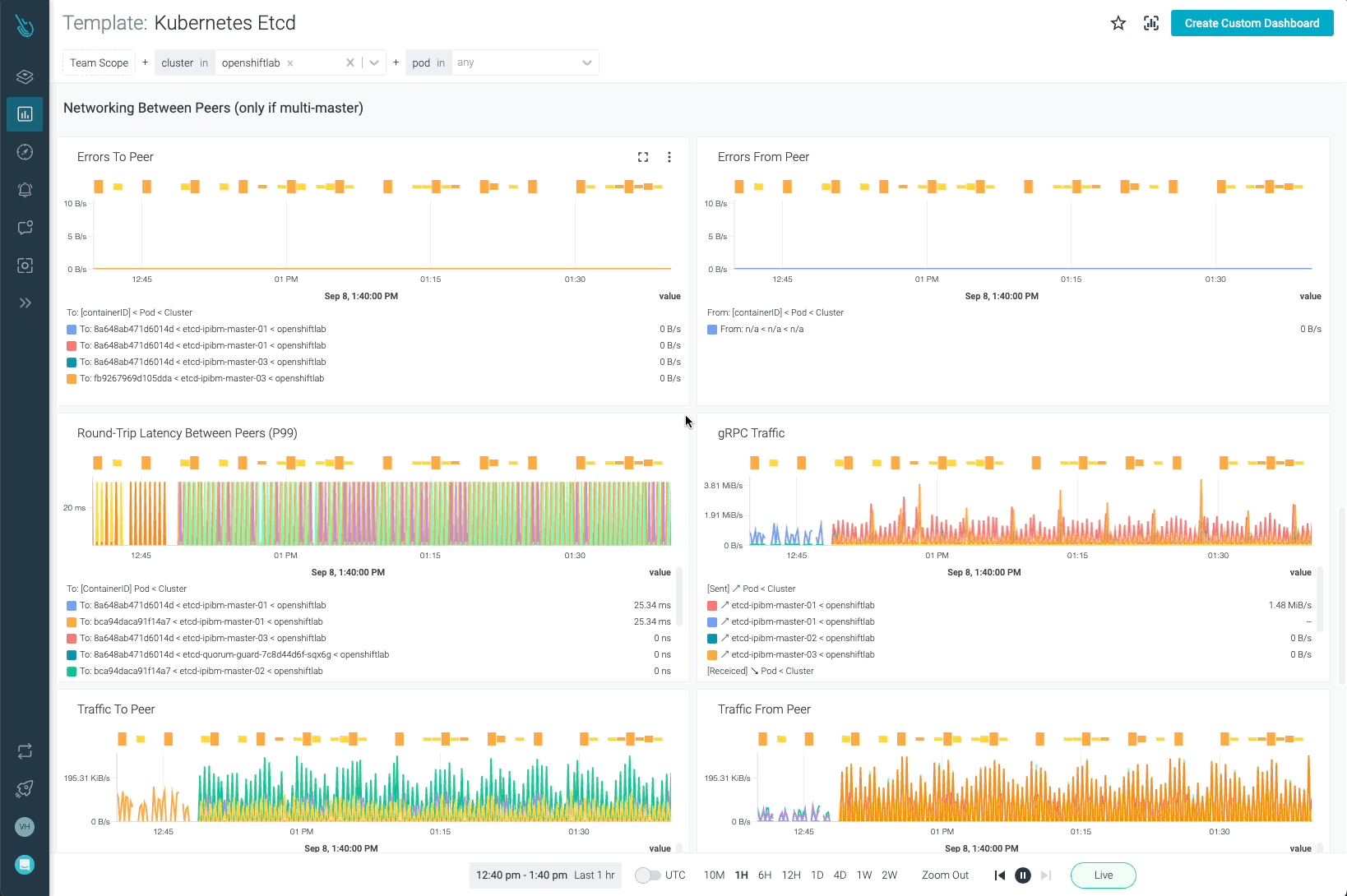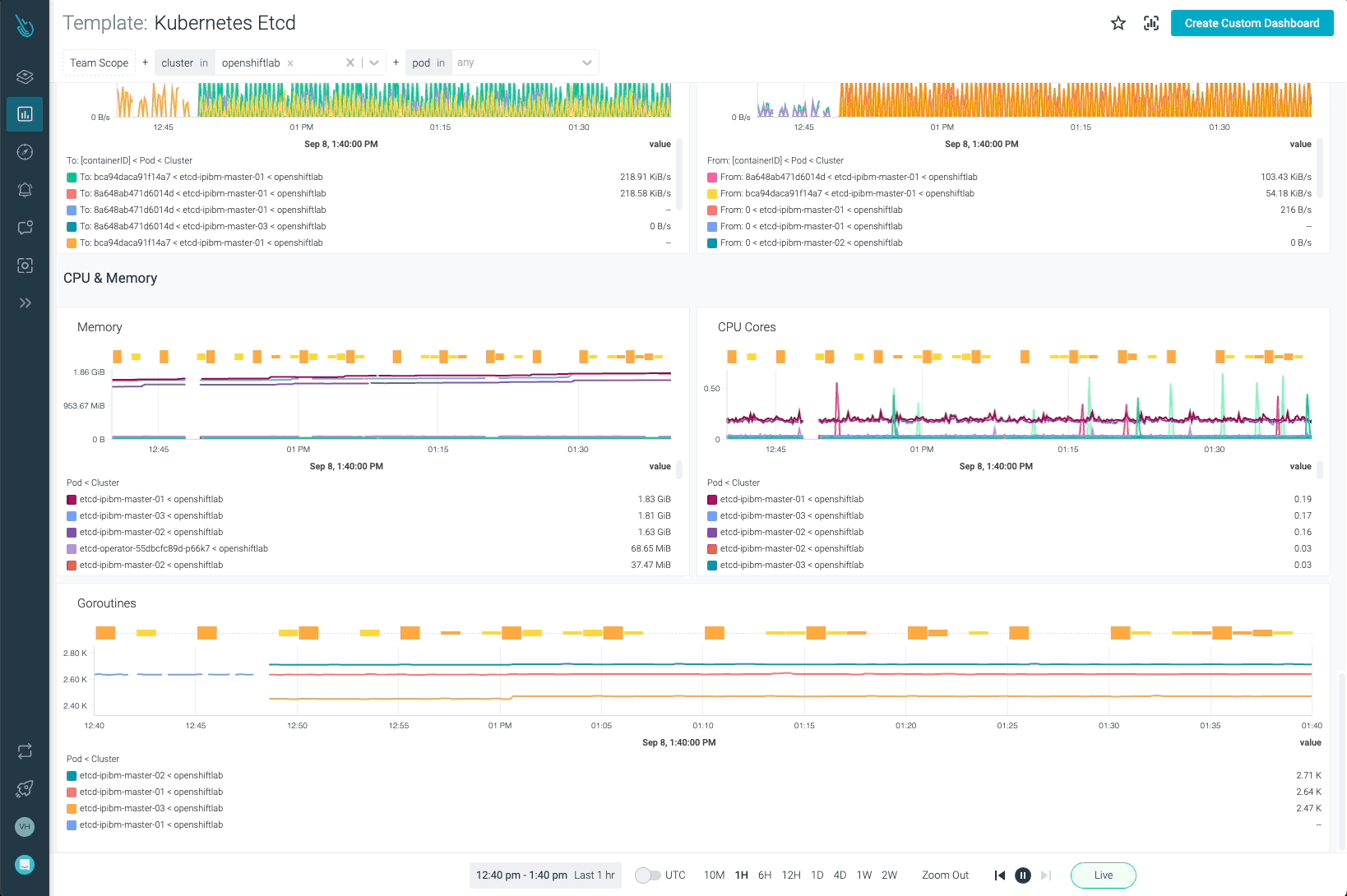 Etcdのダッシュボード
Etcdのダッシュボード
OpenShift APIサーバー、OpenShift Scheduler、OpenShift Controllerは、Sysdig Monitorで提供されるテンプレートで監視することが可能です。これらの新しいダッシュボードを自分で追加する必要はないことを覚えておいてください。エージェントから来るデータが取り込まれるとすぐに、ダッシュボードが自動的に表示されます。
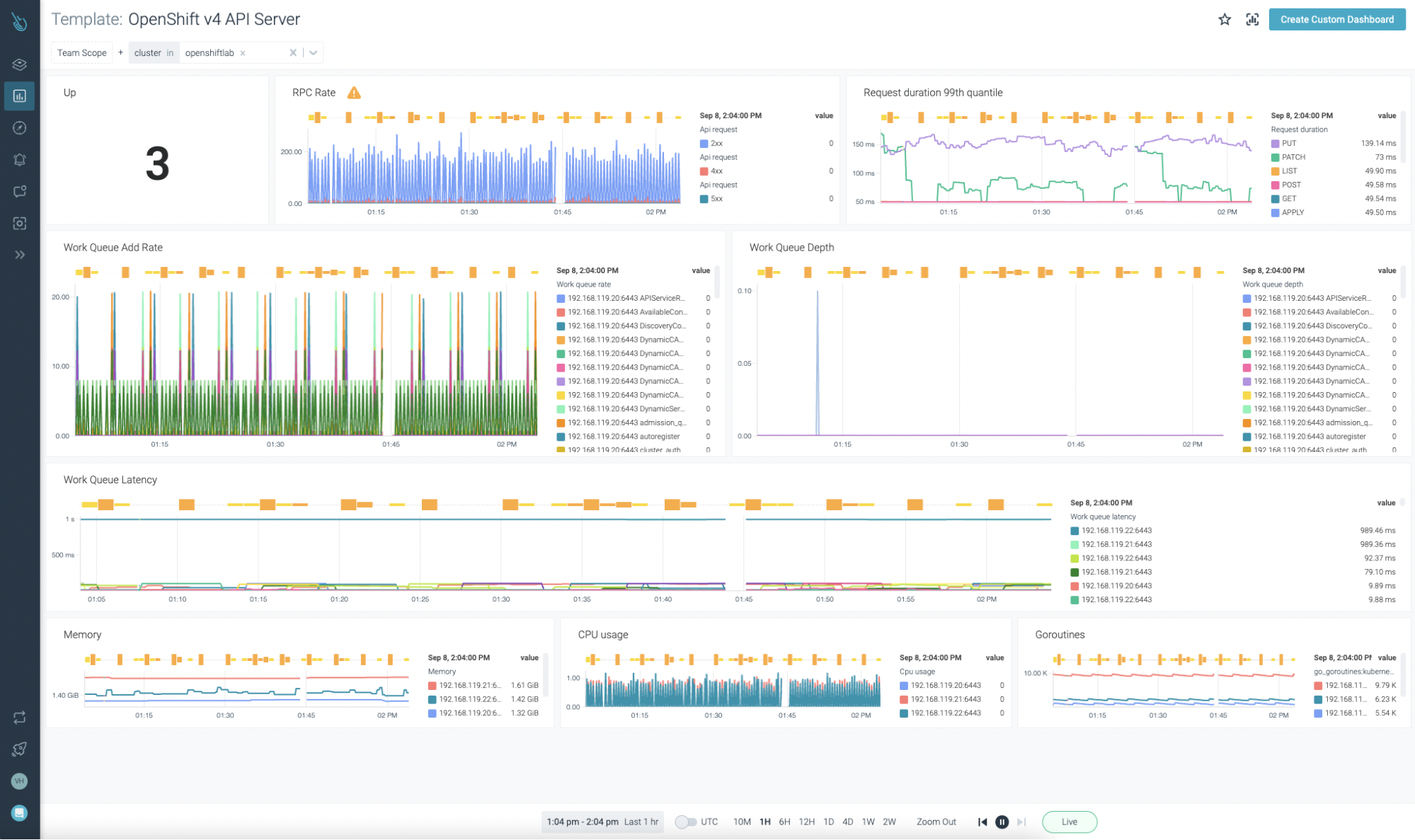 OpenShift API サーバーのダッシュボード
OpenShift API サーバーのダッシュボードクールですね! しかし、あなた自身のワークロードやサービスについてはどうでしょうか?
Sysdig Monitor のお客様は、その心配は無用です。Kubernetesのコントロールプレーンとユーザーのワークロード/サービスの両方に焦点を当てたダッシュボードの膨大なコレクションが、すぐに使える状態で提供されています。
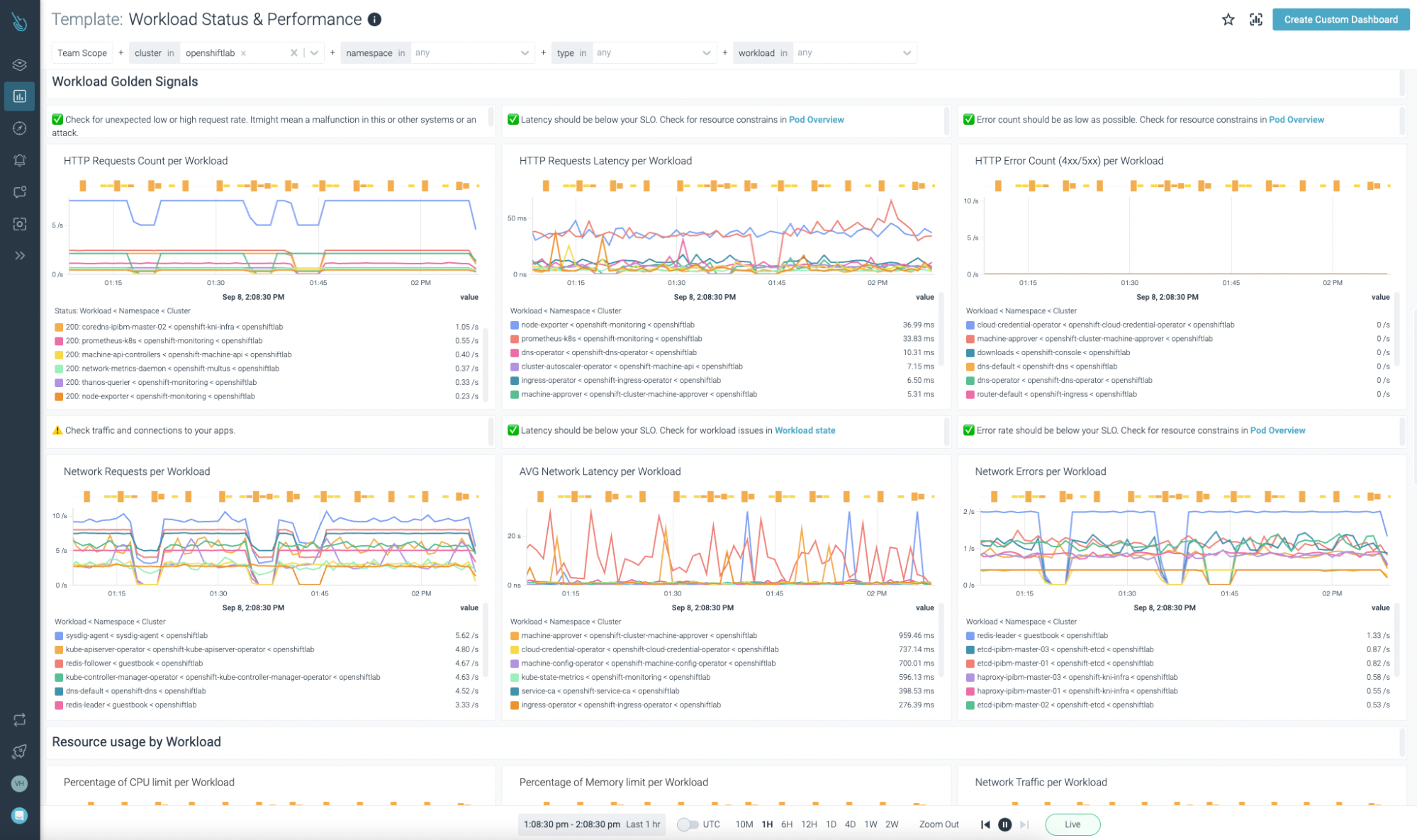 OpenShiftワークロードのダッシュボード
OpenShiftワークロードのダッシュボードSysdig MonitorでOpenShiftの問題をトラブルシュートする方法
Sysdig Agentは、前項で述べたように、Prometheusの時系列データ、ログ、イベントを収集するだけではありません。最も興味深い機能は、システムコールイベントの処理と、OpenShiftでのデータ分析や問題のトラブルシューティングのためのキャプチャー作成で構成されています。Sysdig Advisor機能はSysdig Monitorに含まれており、Kubernetes/OpenShiftインフラクチャーで検出された問題のトラブルシューティングでお客様を支援します。
クラスター、ノード、ネームスペース、ワークロードの状態を一目で簡単に確認することができます。
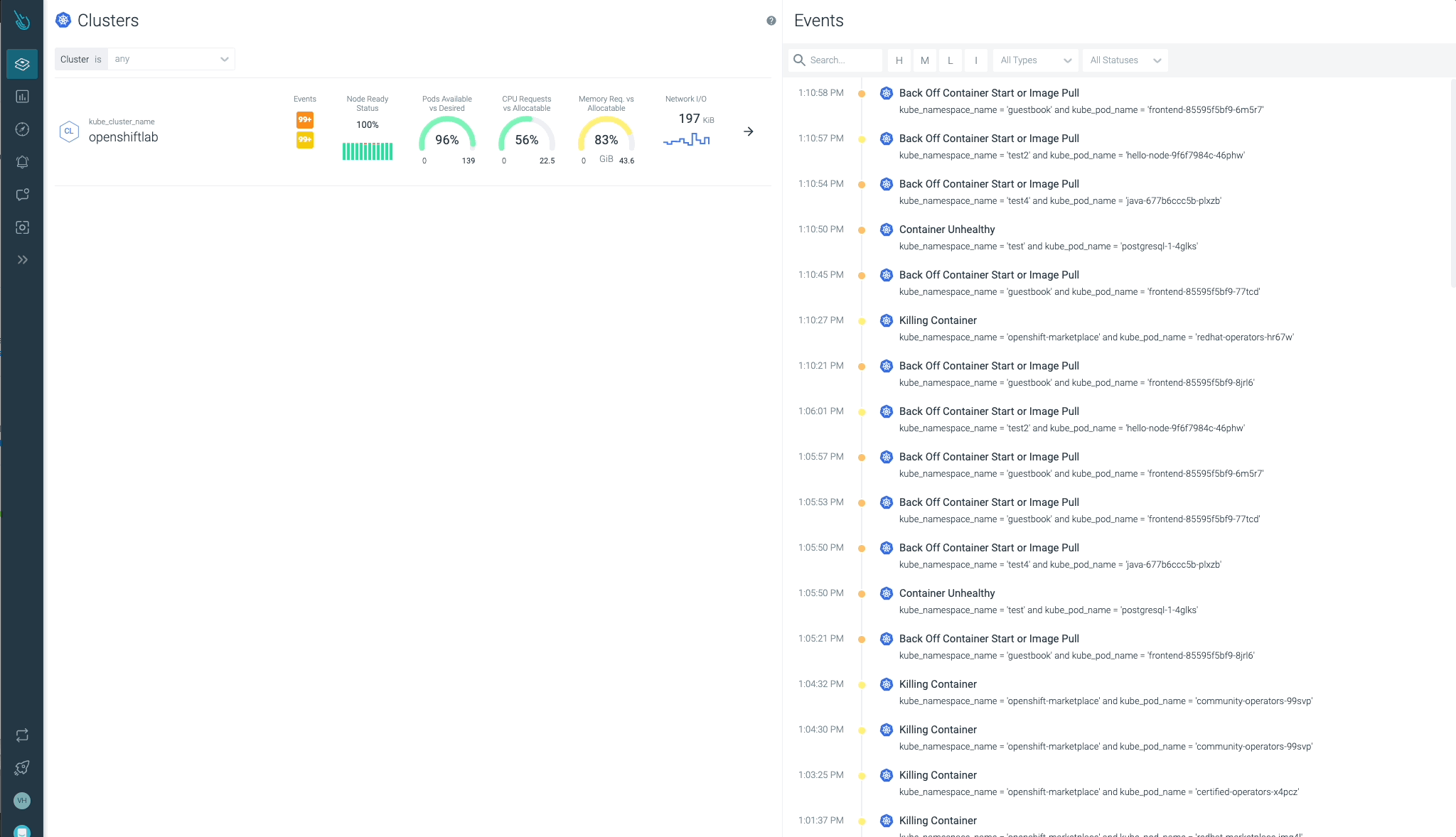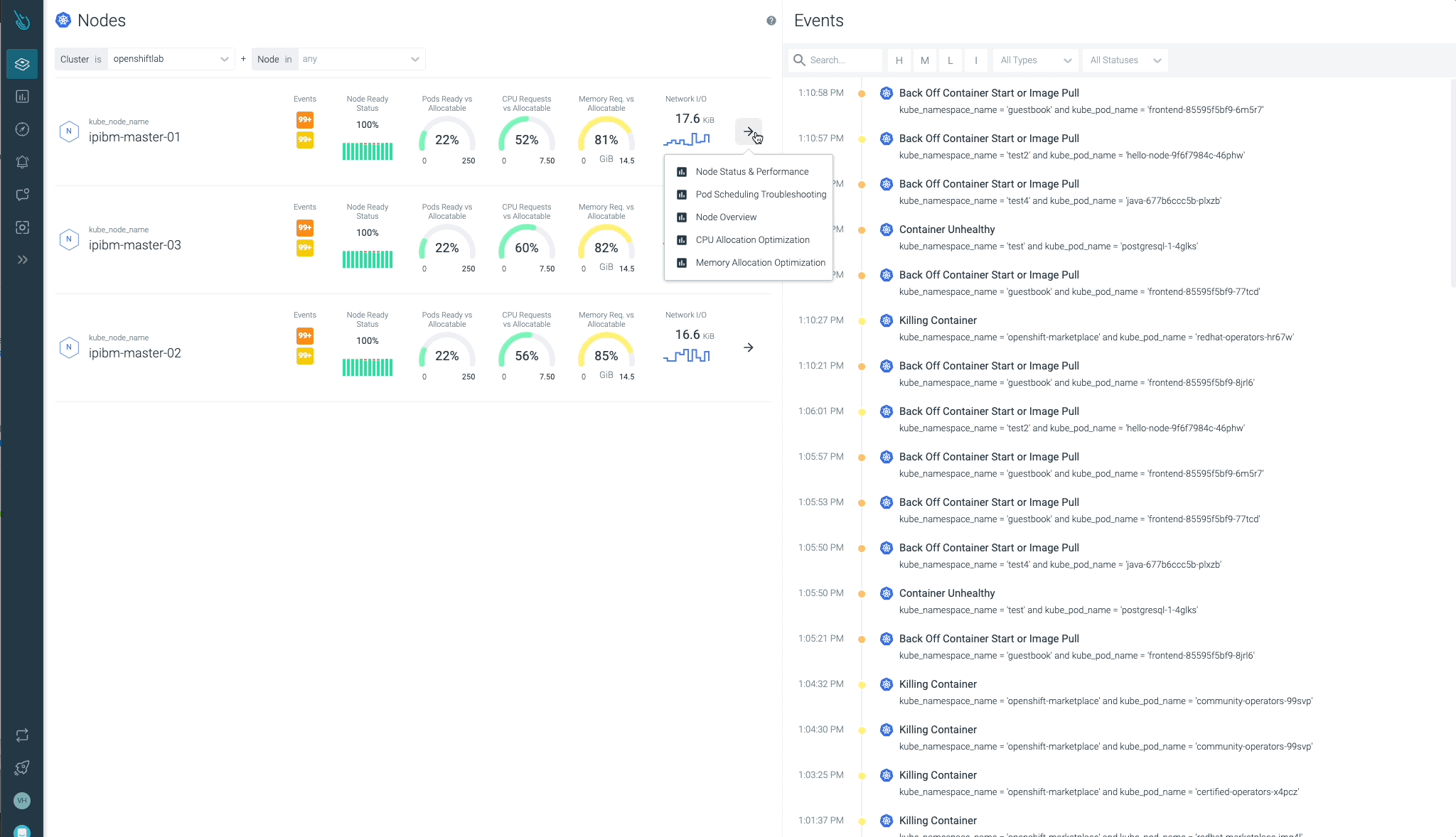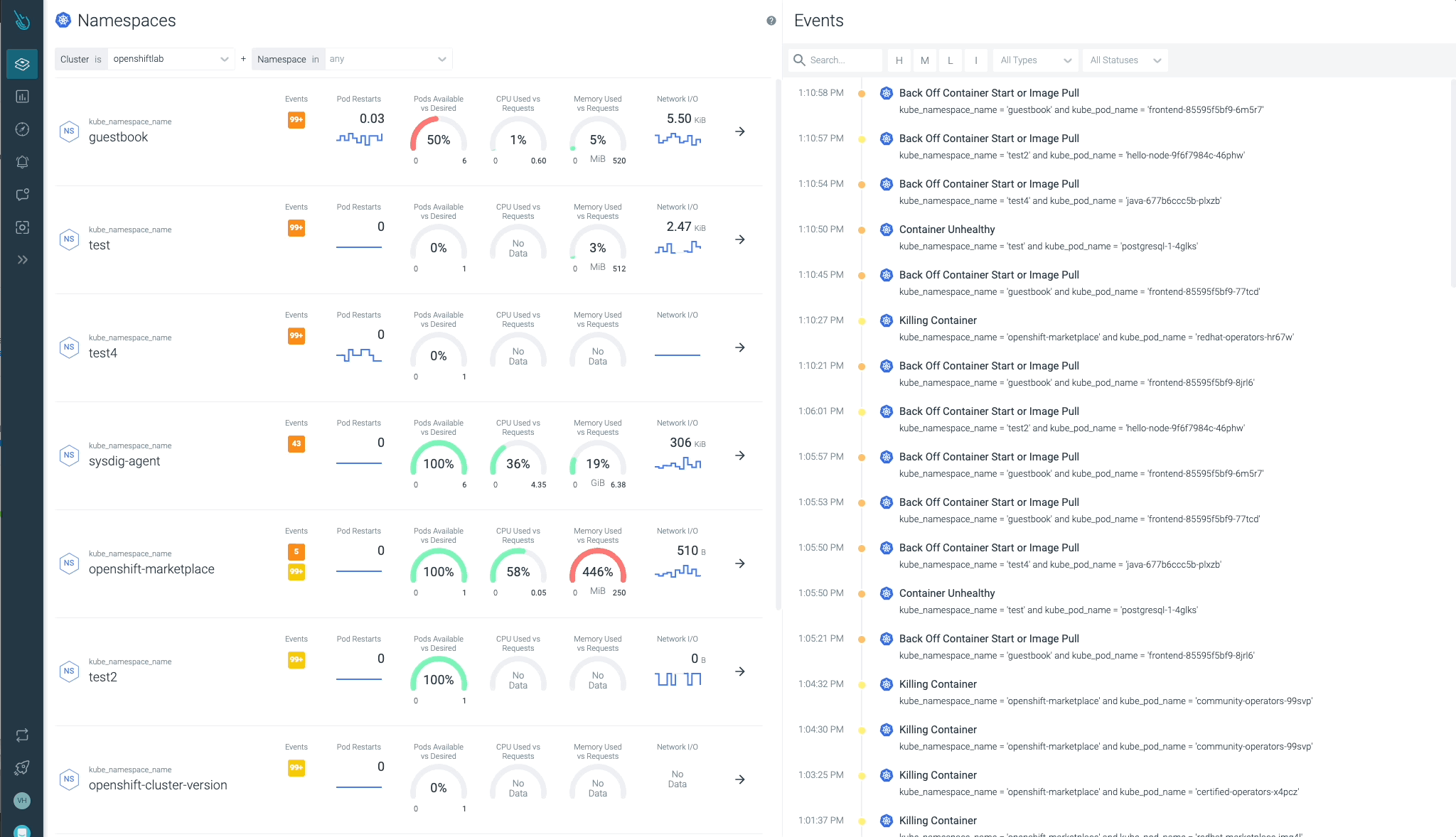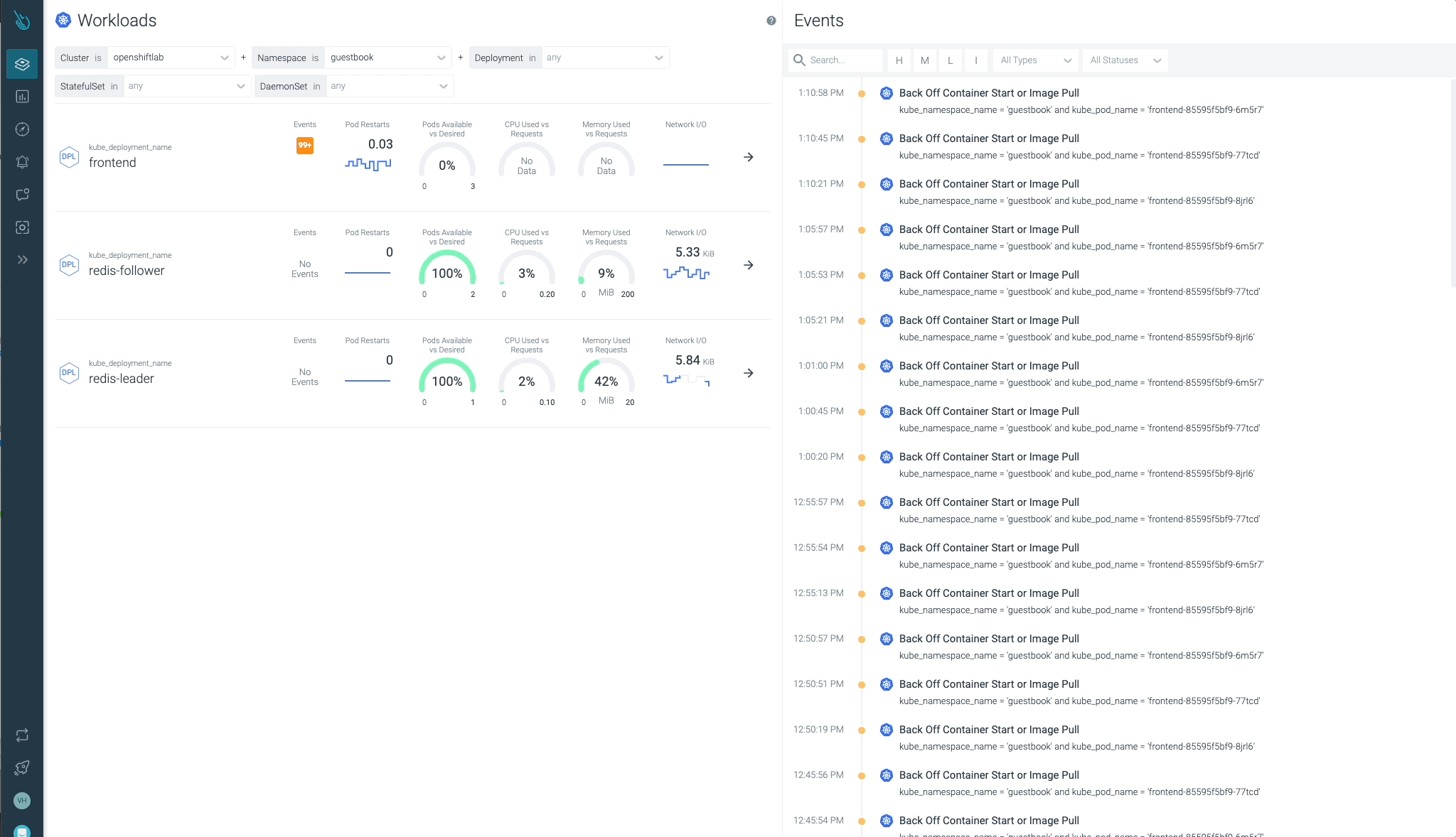
Sysdig Advisorは、ワークロードレベルである種のクリティカルな問題を検出することができますが、それだけではありません。Sysdig Advisorのお客様は、問題の発生頻度、どのコンテナが関係しているか、どれだけのリソースが使用されているか、さらに、何が起きていてどのように問題を修正するかについての簡単な説明についての洞察を得ることができます。
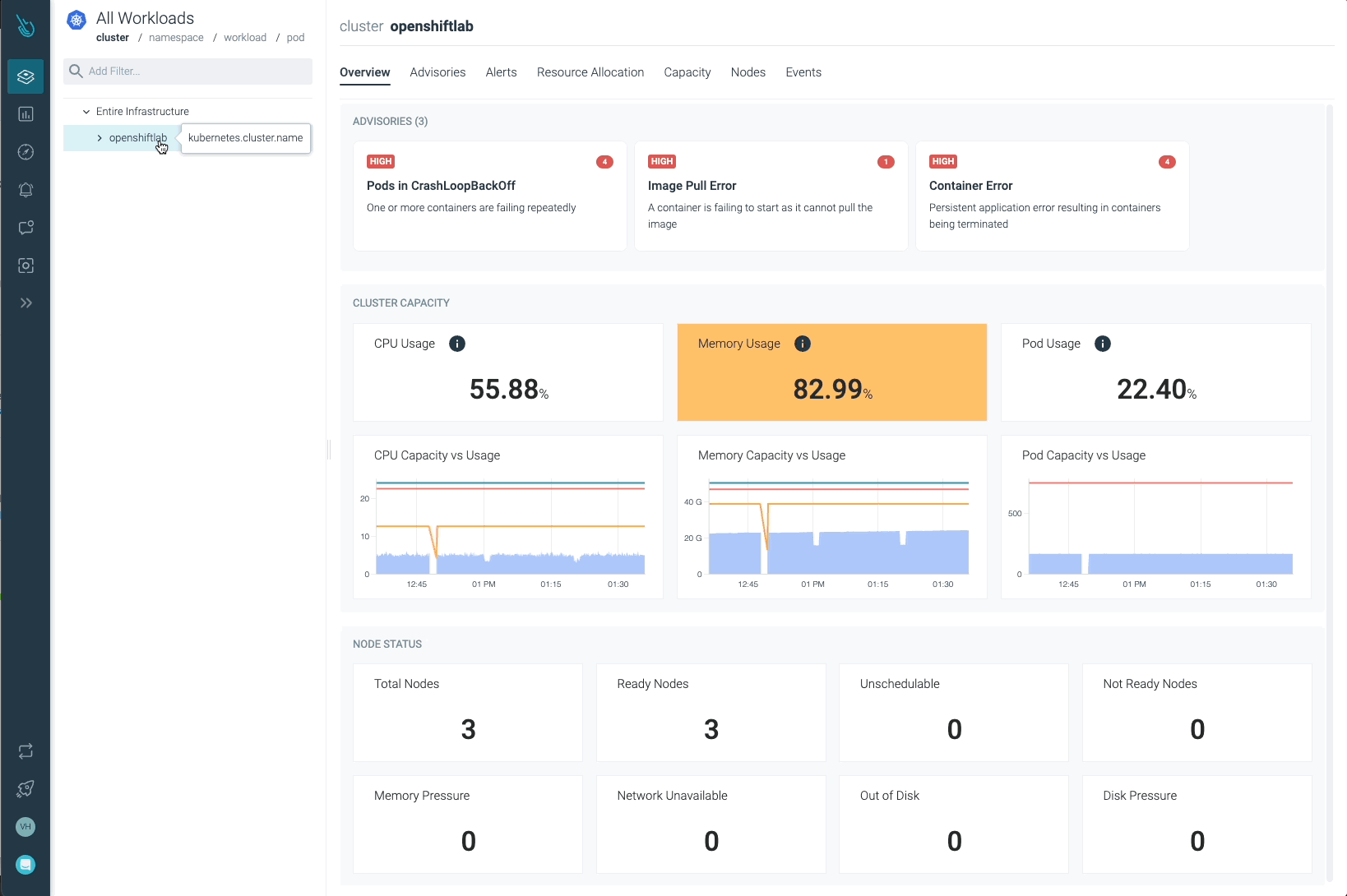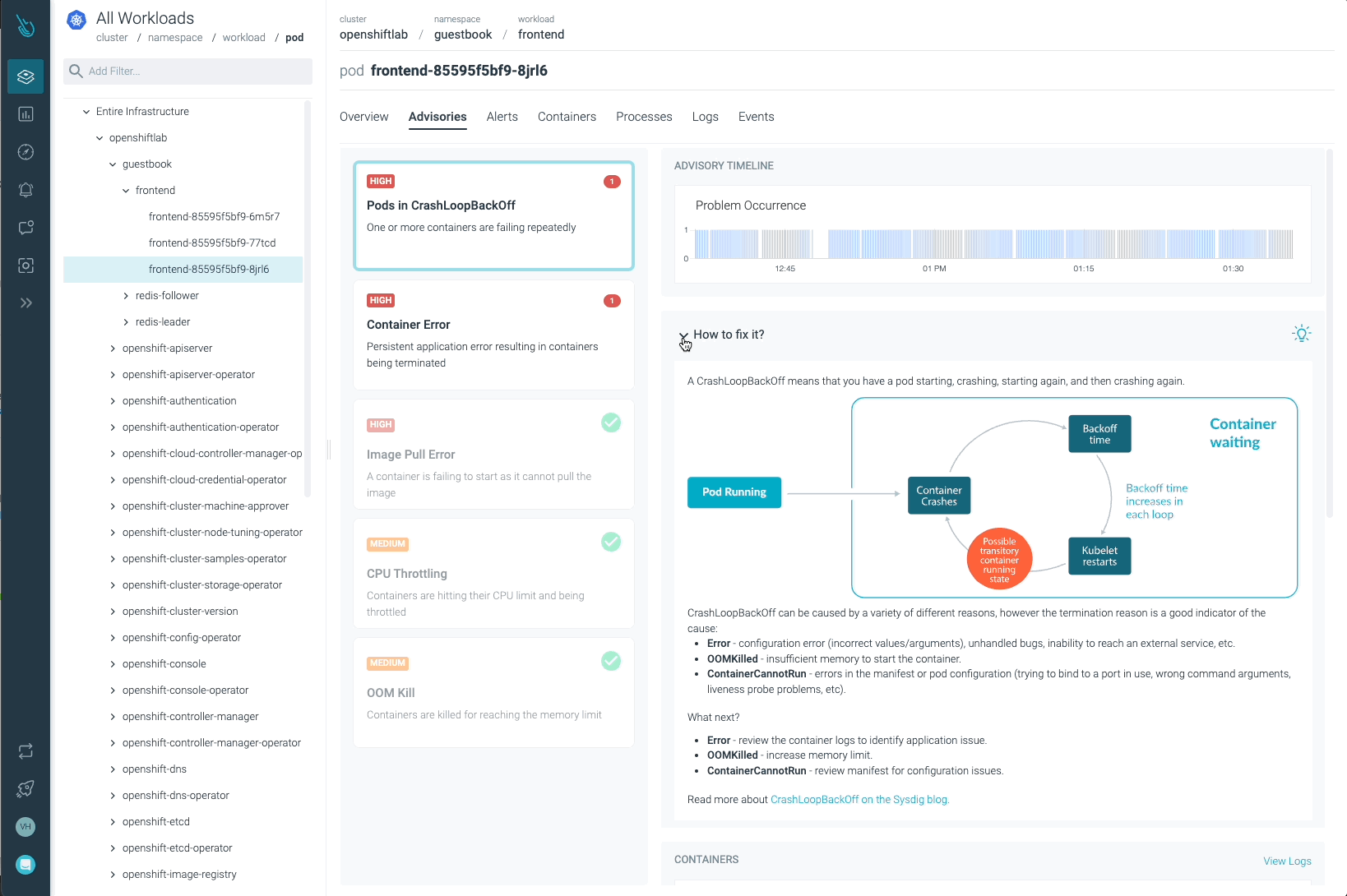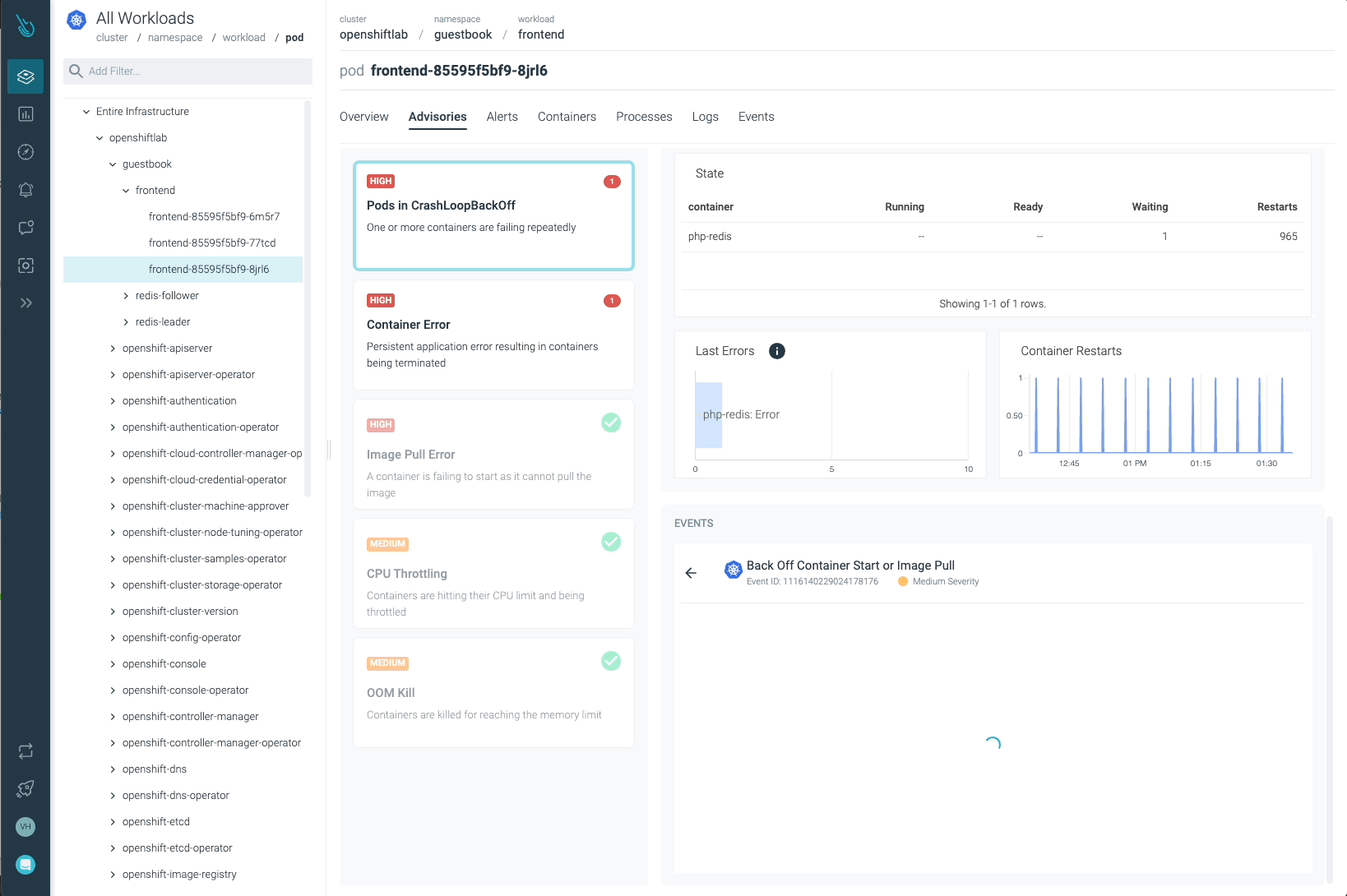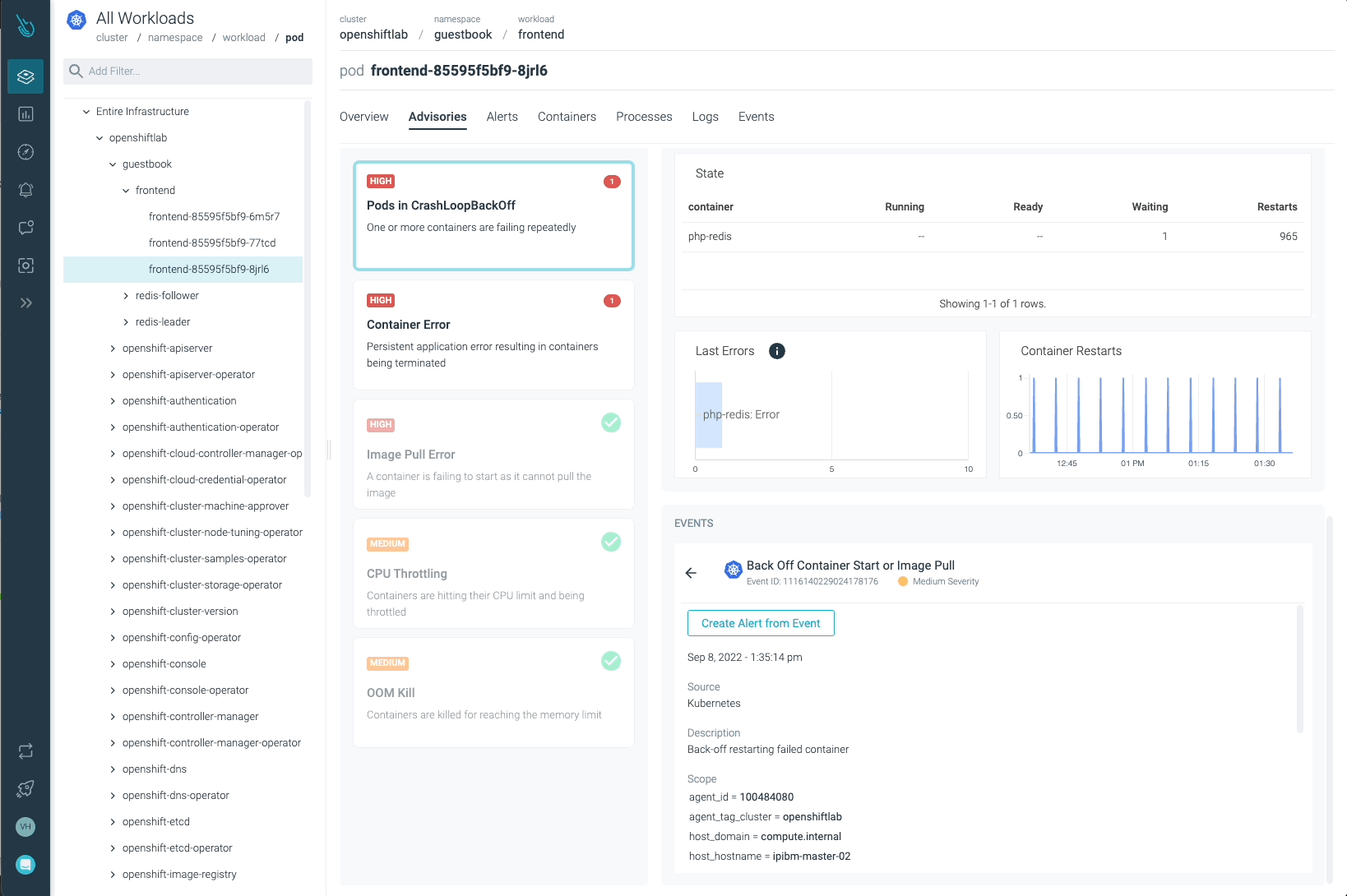
前の画像では、少なくとも1つのPodがCrashLoopBackOffの状態になっており、起動できないコンテナ(Container Error)が確認できます。Advisorは、お客様が問題を診断し、必要なアクションを取るために必要な重要な情報(関係するコンテナ、イベント、ログなど)を提供します。
ここまではいいのですが、、、Sysdig Monitorはどのように本当の問題を深く掘り下げるのに役立つのでしょうか?それは可能でしょうか?はい、可能です。
Sysdig Monitor は、コンテナデータ(コンテナ内の一定時間内に発生したすべてのアクティビティ)を、トラフィックネットワークキャプチャーのようにキャプチャーして分析することが可能です。
キャプチャーは、イベントがトリガーされるたびに収集することができます。新しいアラートが作成されると、キャプチャーデータオプションが利用可能になり、お客様はこの機能をオンデマンドで設定することができます。キャプチャーが収集されるたびに、クラウド上のSysdig Monitorのストレージに保存されます。
 Sysdig Monitorのキャプチャーを見る
Sysdig Monitorのキャプチャーを見る分析したいキャプチャーをクリックすると、Sysdig Inspectは、ノードカーネルから直接収集したすべてのデータをすぐに表示します。これはとても素晴らしいことです。
このすべてのデータを使って、問題の根本的な原因を確認し、見つけることができます。コンテナ内の問題を診断するために必要なものはすべてこのキャプチャーにあり(実行中のプロセス、ネットワークデータ、ファイル、システムコールなど)、自動的に収集されて Sysdig Monitor に保存されています。
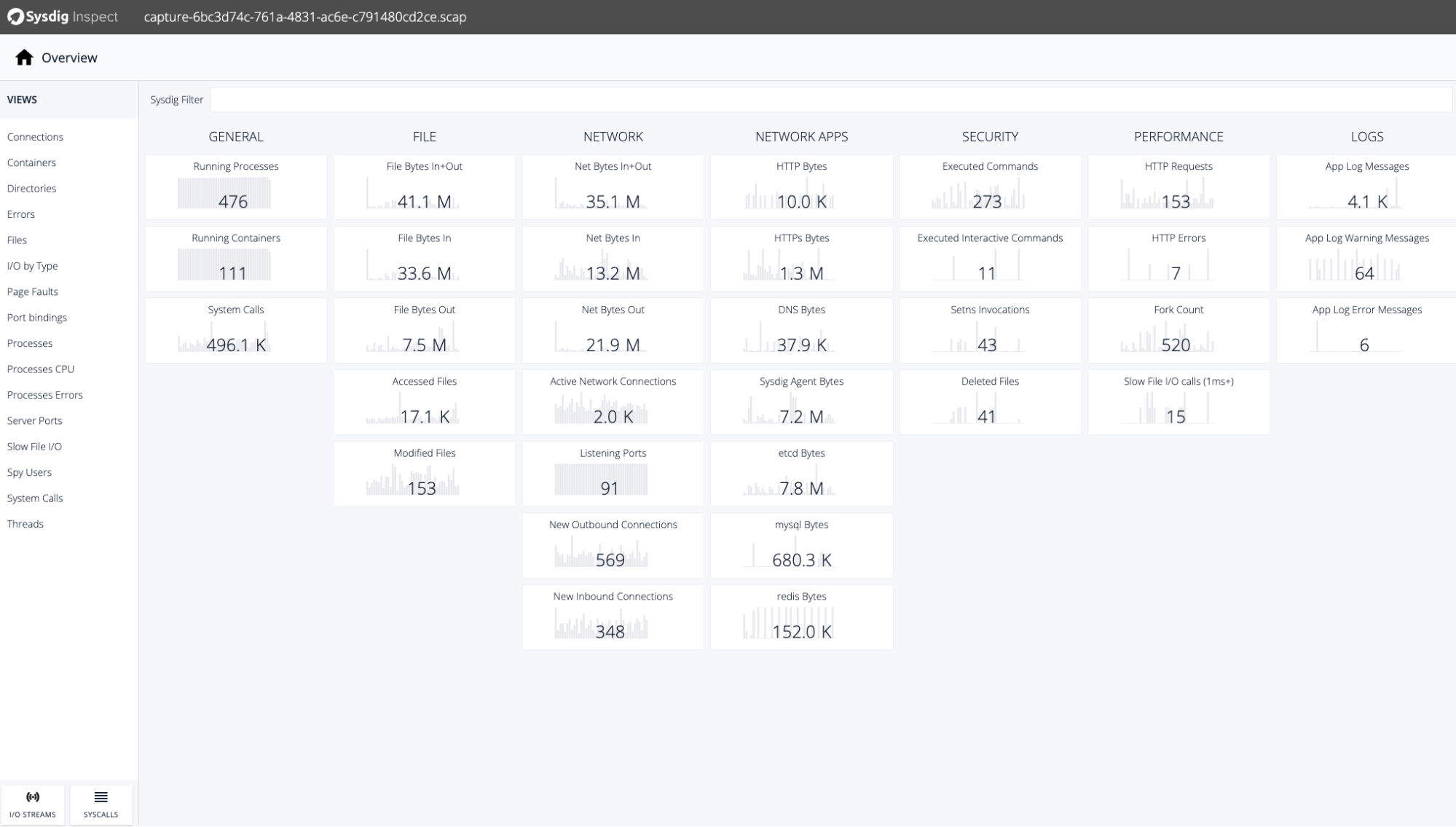 Sysdig Inspect
Sysdig Inspectまとめ
Sysdig MonitorでOpenShiftを監視することで、0日目から組織に即効性のある利益を提供します。お客様は手間をかけることなく、最も完全で堅牢、俊敏で多用途な監視プラットフォームを手に入れることができます。KubernetesとOpenShiftだけでなく、あらゆるクラウドサービスプロバイダーの他のすべてのKubernetesディストリビューションで利用可能です。Sysdig Monitorは、簡単、高速、かつ完全なOpenShift監視ソリューションを提供し、表面的な問題から難しい問題まで、検出とトラブルシューティングを可能にします。
Sysdig Monitor が Kubernetes クラスターの監視とトラブルシューティングにどのように役立つかを知りたい場合は、Sysdig Monitor のトライアルページにアクセスし、30日間の無料アカウントをリクエストしてください。数分で使い始めることができますよ!