
Kubernetesのリソースリミットは、リミットがきつすぎたり緩すぎたりする間のスイートスポットを見つける必要があるため、常に調整が難しい設定です。
この記事では、Kubernetesキャパシティプランニングシリーズの続編として、正しいKubernetesリソースリミットを設定する方法を学びます。リミットのないコンテナの検出から、クラスターに設定すべき正しいKubernetesリソースリミットの見つけ方までを学んでいきましょう。
ここでは、KubernetesクラスターのモニタリングにPrometheusを使用していることを想定しています。そのため、このガイドのすべてのステップは、PromQLクエリーの例で説明されています。
Kubernetesリソースリミットがないコンテナを検出する
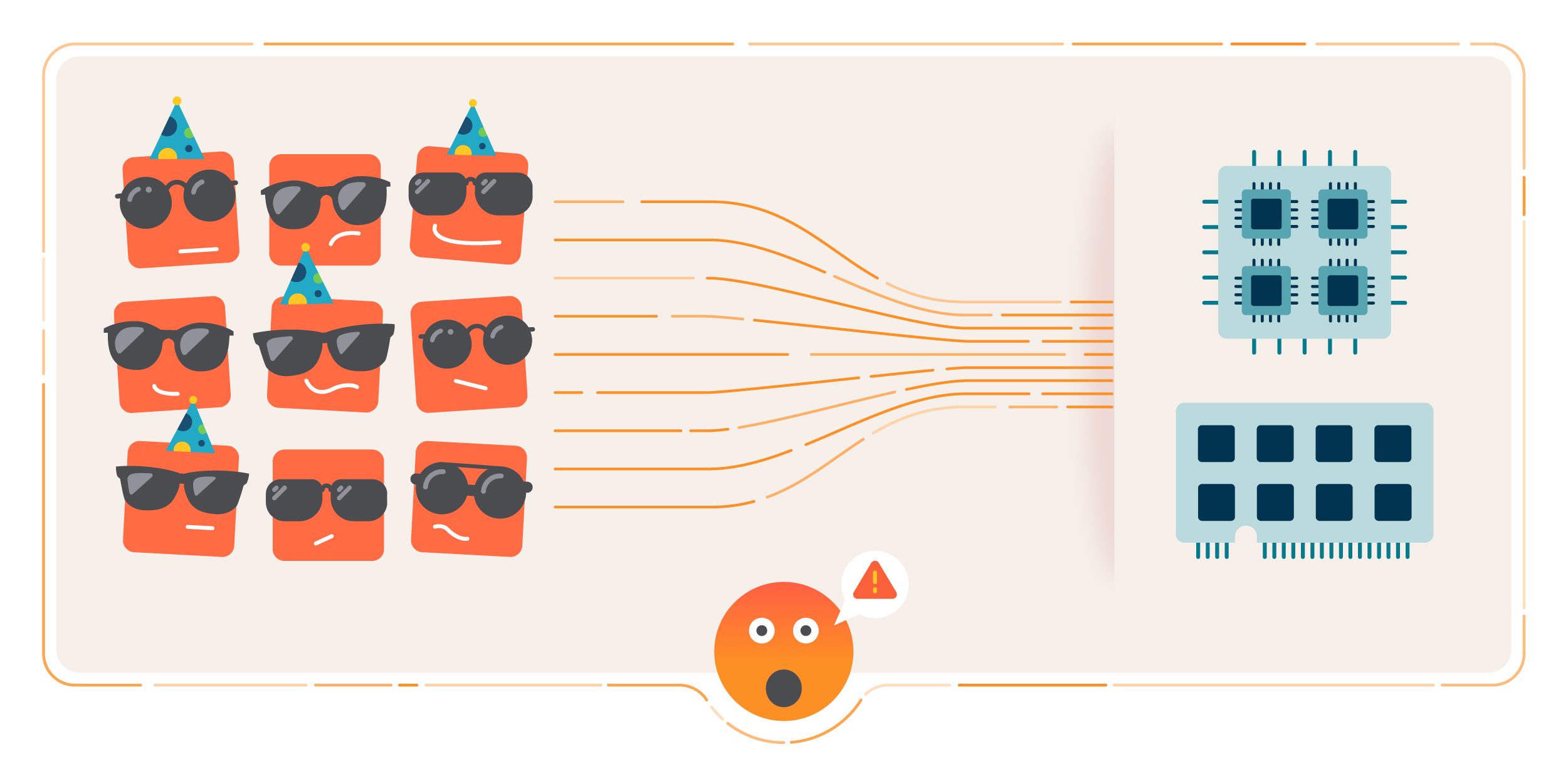 この図は、ノード内のコンテナがKubernetesのリソースリミットを受けていないため、ノードが危機的な状況にあることを示しています。
この図は、ノード内のコンテナがKubernetesのリソースリミットを受けていないため、ノードが危機的な状況にあることを示しています。適切なKubernetesリソースリミットを設定するための最初のステップは、リミットのないコンテナを検出することです。
Kubernetesのリソースリミットがないコンテナは、ノードに非常に重大な結果を引き起こす可能性があります。最良のケースでは、ノードはポッドを順番に退避させたり、スコアリングを開始します。また、CPUスロットリングによるパフォーマンス問題が発生します。最悪のシナリオでは、ノードはメモリ不足で停止します。
Kubernetesリソースリミットのないコンテナを探す
ネームスペース毎のCPUリミットのないコンテナ
sum by (namespace)(count by (namespace,pod,container)(kube_pod_container_info{container!=""}) unless sum by (namespace,pod,container)(kube_pod_container_resource_limits{resource="cpu"}))ネームスペース毎のメモリリミットのないコンテナ
sum by (namespace)(count by (namespace,pod,container)(kube_pod_container_info{container!=""}) unless sum by (namespace,pod,container)(kube_pod_container_resource_limits{resource="memory"}))Kubernetesのリソースリミットがないコンテナがたくさん見つかりましたか?
もしかしたら、Kubernetesのリソースリミットを受けていないコンテナが複数見つかったかもしれません。今のところ、最も危険なものに焦点を当てましょう。どうやって?簡単です、より多くのリソースを使用していてKubernetesリソースリミットのないコンテナのトップ10を見つけるだけです。CPUリミットがなく、より多くのCPUを使用しているコンテナのトップ10
topk(10,sum by (namespace,pod,container)(rate(container_cpu_usage_seconds_total{container!=""}[5m])) unless sum by (namespace,pod,container)(kube_pod_container_resource_limits{resource="cpu"}))メモリリミットのないコンテナで、より多くのメモリを使用しているトップ10
topk(10,sum by (namespace,pod,container)(container_memory_usage_bytes{container!=""}) unless sum by (namespace,pod,container)(kube_pod_container_resource_limits{resource="memory"}))
Kubernetesリソースリミットが非常にタイトなコンテナの検出
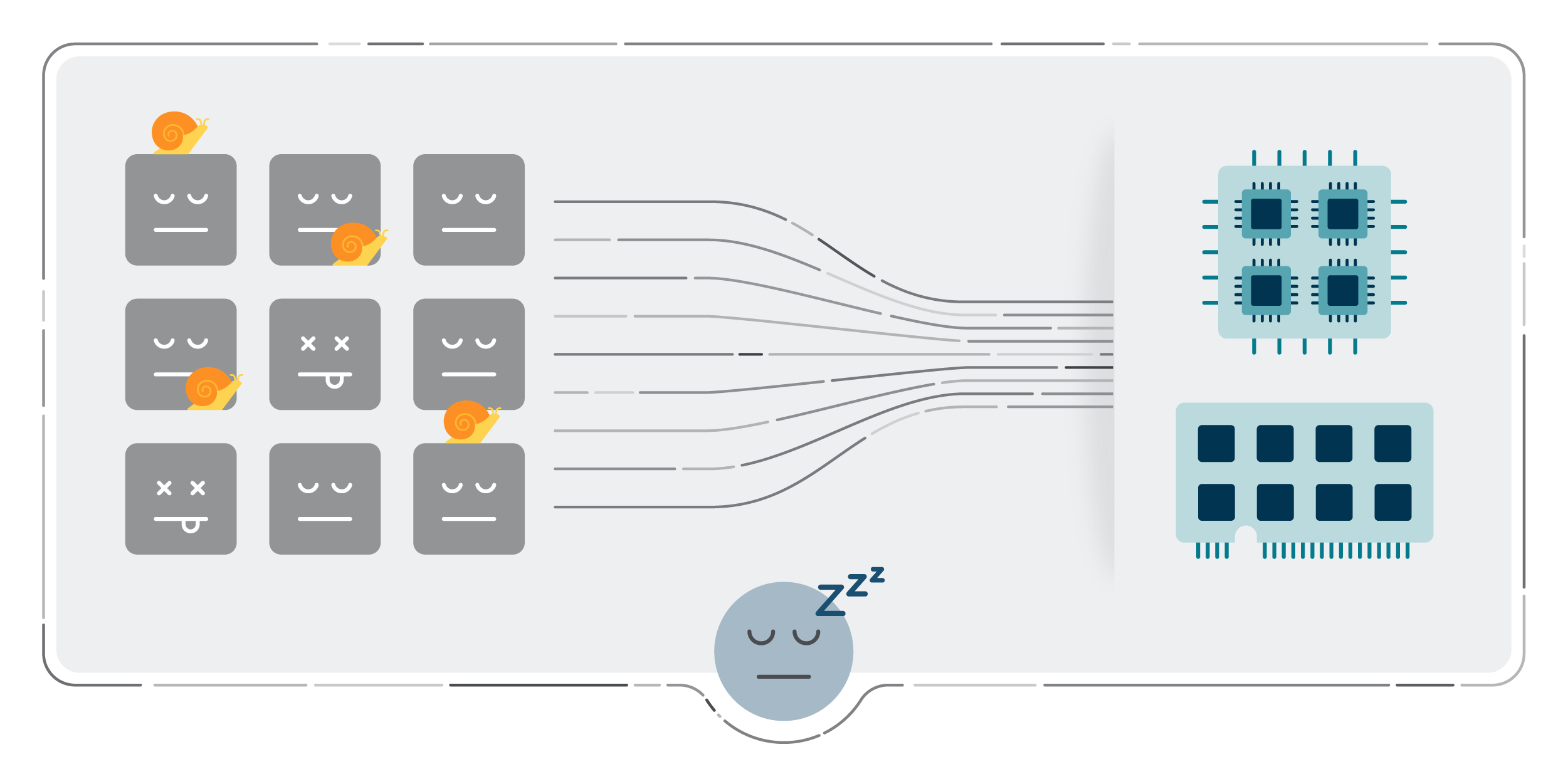 この図は、ノード内のコンテナが非常にタイトなKubernetesリソースリミットを持っているため、最適ではない状況にあるノードを示しています。
この図は、ノード内のコンテナが非常にタイトなKubernetesリソースリミットを持っているため、最適ではない状況にあるノードを示しています。CPUリミットが非常にタイトコンテナの検出
コンテナがCPUリミットに近づき、通常よりもCPUを必要とする処理を実行する必要がある場合、CPUスロットリングによりパフォーマンスが低下します。このクエリーを使用して、CPU 使用量がリミットに近いコンテナを見つけます。
(sum by (namespace,pod,container)(rate(container_cpu_usage_seconds_total{container!=""}[5m])) / sum by (namespace,pod,container)(kube_pod_container_resource_limits{resource="cpu"})) > 0.8メモリリミットが非常にタイトコンテナの検出
コンテナがメモリリミットに近づき、それを超えてしまった場合、そのコンテナはKillされます。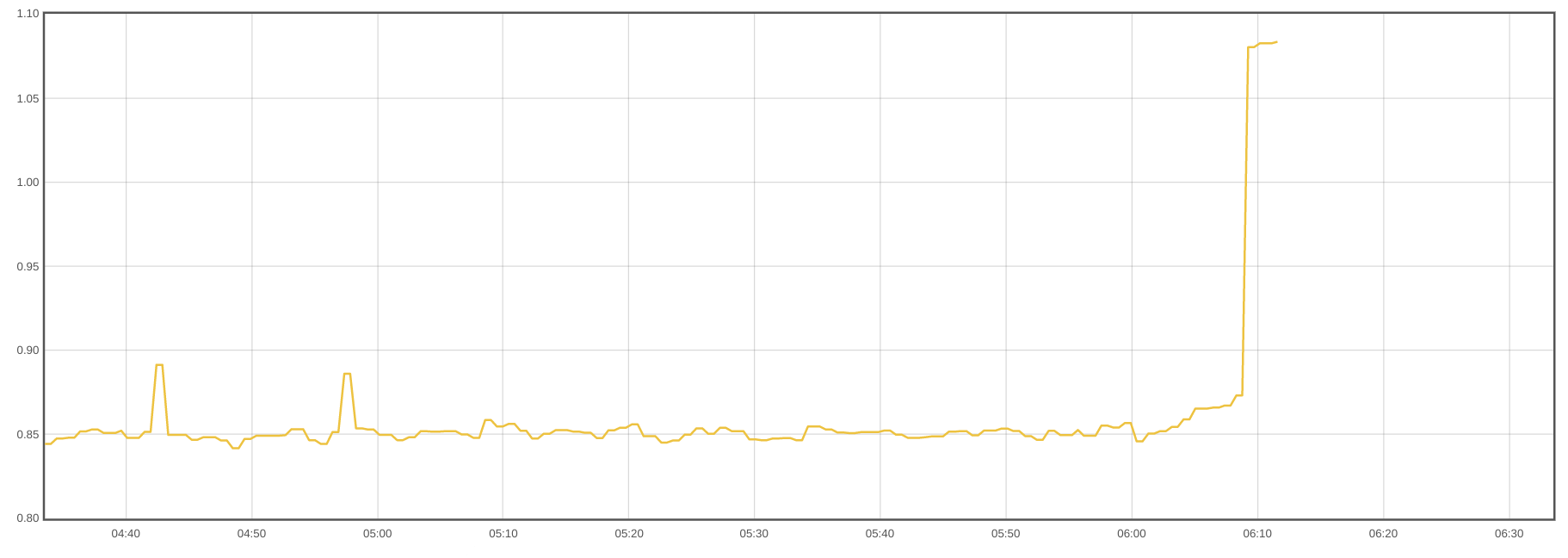
このグラフは、あるコンテナがメモリ使用量を大幅に増加させ、リミットに達して停止した様子を示しています。
このクエリーを使用して、メモリ使用量が限界に近いコンテナを見つけます。
(sum by (namespace,pod,container)(container_memory_usage_bytes{container!=""}) / sum by (namespace,pod,container)(kube_pod_container_resource_limits{resource="memory"})) > 0.8Kubernetesのリソースリミットを正しく設定するには?
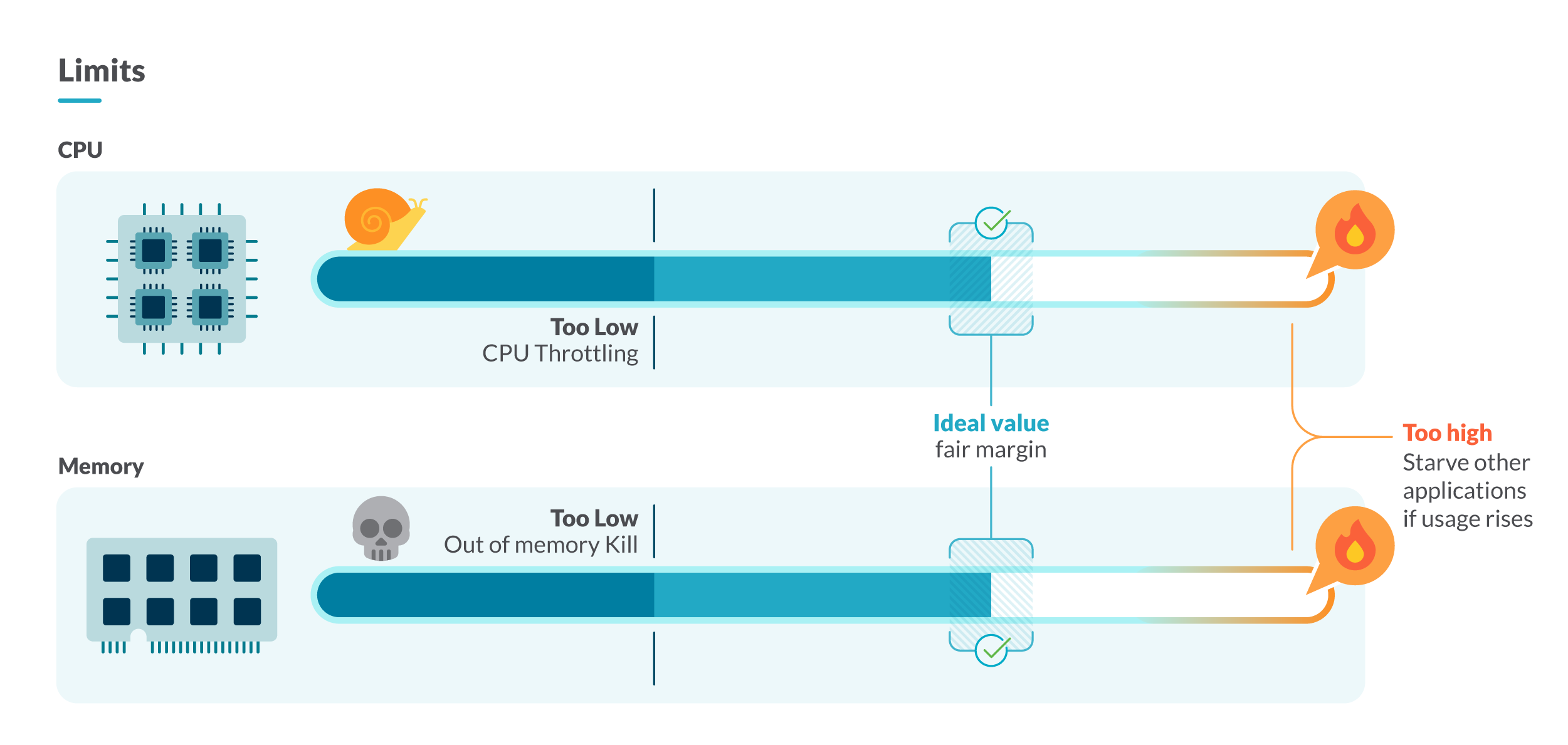 この図は、Kubernetesのリソースリミットを厳しく設定しすぎると、CPU Throttlingやメモリ不足の状況が発生し、緩く設定しすぎるとリソースの枯渇によりノードが停止することを示しています。
この図は、Kubernetesのリソースリミットを厳しく設定しすぎると、CPU Throttlingやメモリ不足の状況が発生し、緩く設定しすぎるとリソースの枯渇によりノードが停止することを示しています。一つの方法は、制限したいコンテナのリソース使用量をしばらく調査することです。そのためには、同じ種類とワークロード(ワークロードはデプロイメント、デーモンセット、ステートフルセットなど)のコンテナに注目します。ここでは、2つの戦略があります。
保守的
各瞬間に最も多く消費したコンテナの値を選択します。リミットをその値に設定すれば、コンテナがリソース不足になることはありません。保守的な戦略で適切なCPUリミットを見つける
max by (namespace,owner_name,container)((rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))保守的な戦略で適切なメモリリミットを見つける
max by (namespace,owner_name,container)((container_memory_usage_bytes{container!="POD",container!=""}) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))積極的
分位値99をリミット値として選択します。これにより、消費量の多い1%の人はリミットから外れます。これは、サポートしたくない異常値やピークがまばらにある場合に有効な戦略です。積極的な戦略で適切なメモリリミットを見つける
quantile by (namespace,owner_name,container)(0.99,(rate(container_cpu_usage_seconds_total{container!="POD",container!=""}[5m])) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))積極的な戦略で適切なメモリリミットを見つける
quantile by (namespace,owner_name,container)(0.99,(container_memory_usage_bytes{container!="POD",container!=""}) * on(namespace,pod) group_left(owner_name) avg by (namespace,pod,owner_name)(kube_pod_owner{owner_kind=~"DaemonSet|StatefulSet|Deployment"}))クラスターのキャパシティは足りていますか?
Kubernetesでは、ノードは各ポッドのコンテナリクエストに基づいて、その中でスケジューリングされたポッドが十分なリソースを持っていることを保証します。これは、ノードがすべてのコンテナに、そのリミット内で設定された量のCPUとメモリを与えることを約束していることも意味します。リミットが非常に緩いコンテナについて語ることは、リミットオーバーコミットについて語ることと同じです。これは、すべてのKubernetesリソースのリミットの合計が、そのリソースのキャパシティよりも大きい場合に起こります。
クラスター内のリソースをオーバーコミットしている場合、通常の状態ではすべてが完璧に動作するかもしれませんが、高負荷のシナリオでは、コンテナがCPUやメモリを限界まで消費し始める可能性があります。これにより、ノードはポッド退避を開始し、非常に危機的な状況では、クラスター内の利用可能なリソースが枯渇してノードが停止することになります。
クラスターのオーバーコミットを見つける
クラスターのメモリとCPUのオーバーコミットの割合を確認するには、次のようにします。クラスターのオーバーコミットされたメモリの割合
100 * sum(kube_pod_container_resource_limits{container!="",resource="memory"} ) / sum(kube_node_status_capacity_memory_bytes)クラスターのCPUオーバーコミットの割合
100 * sum(kube_pod_container_resource_limits{container!="",resource="cpu"} ) / sum(kube_node_status_capacity_cpu_cores)通常、すべてのコンテナが同時にすべてのリソースを消費するわけではないので、100%のオーバーコミットを持つことは、リソースの観点からは理想的です。その一方で、使用されることのないインフラに余分なコストがかかります。
クラスタのキャパシティをより適切に調整するには、オーバーコミットを125%以下に抑える保守的な戦略と、オーバーコミットをクラスターのキャパシティの150%にする積極的な戦略があります。
 この図は、クラスターのキャパシティをより適切に調整するための2つの戦略を示しています。オーバーコミットが125%以下になるようにする保守的な戦略と、オーバーコミットがクラスターのキャパシティの150%に達するようにする積極的な戦略を選択できます。
この図は、クラスターのキャパシティをより適切に調整するための2つの戦略を示しています。オーバーコミットが125%以下になるようにする保守的な戦略と、オーバーコミットがクラスターのキャパシティの150%に達するようにする積極的な戦略を選択できます。ノードのオーバーコミットを見つける
ノードごとのオーバーコミットを確認することも重要です。ノードのオーバーコミットの例としては、リクエストが2CPUでリミットが8のポッドがあります。そのポッドは4コアのノードでスケジューリングできますが、ポッドのリミットが8コアなので、そのノードのオーバーコミットは8 – 4 = 4コアとなります。ノードのオーバーコミットされたメモリの割合
sum by (node)(kube_pod_container_resource_limits{container!=””,resource=”memory”} ) / sum by (node)(kube_node_status_capacity_memory_bytes)
ノードの CPU オーバーコミットの割合
sum by (node)(kube_pod_container_resource_limits{container!=””,resource=”cpu”} ) / sum by (node)(kube_node_status_capacity_cpu_cores)
全てをまとめる
 この図は、Kubernetesのリソースリミットが適切に設定された、パフォーマンスの高いコンテナを持つ幸せなノードを示しています :)
この図は、Kubernetesのリソースリミットが適切に設定された、パフォーマンスの高いコンテナを持つ幸せなノードを示しています :)この記事では、なぜKubernetesのリミットとリクエストを理解することが重要である事とクラスター内の非効率性を検出する方法、そしてKubernetesのリソースリミットを正しく設定するための様々な戦略について学びました。
さらに詳しく知りたい場合は、Kubernetesのリミットとリクエストについて、またはクラスターのリクエストを適切なサイズにする方法について学ぶことができます。
Sysdigを用いたKubernetesキャパシティプランニングの方法
SysdigではKubernetesを使用しており、毎日何百人ものお客様のクラスターをサポートしています。これらの専門知識を、アウトオブボックスのKubernetesダッシュボードでお客様と共有できることを嬉しく思います。適切なダッシュボードがあれば、クラスターのトラブルシューティングやKubernetesのキャパシティプランニングを行うのに、専門家である必要はありません。アウトオブボックスのKubernetesダッシュボードを使えば、数回クリックするだけで活用されていないリソースを発見することができます。
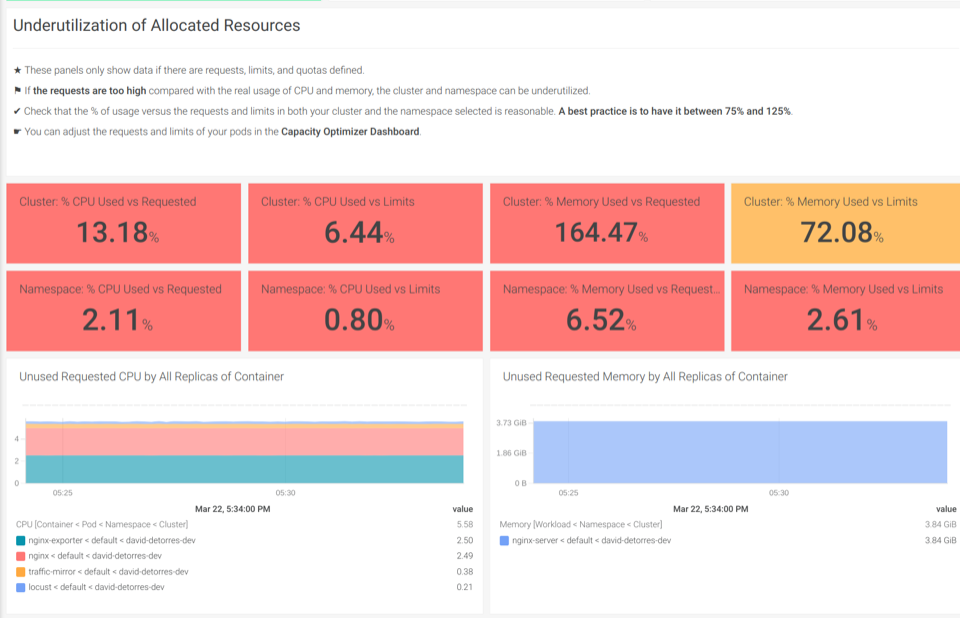
Underutilization of Allocated Resourcesのダッシュボードでは、使用されていないCPUやメモリがあるかどうかを見つけることができます
また、Sysdig Monitorの無料トライアルに登録して、アウトオブボックスのKubernetesダッシュボードをお試しいただけます。