本文の内容は、2023年2月21日にNIGEL DOUGLAS が投稿したブログ(
https://sysdig.com/blog/top-owasp-kubernetes )を元に日本語に翻訳・再構成した内容となっております。
Kubernetesを使用する際の最大の懸念は、セキュリティポスチャーを遵守し、考えられる脅威をすべて考慮に入れているかどうかです。このため、OWASPは、最も可能性の高いリスクを特定するのに役立つ「OWASP Kubernetes Top 10」を作成しました。
OWASP Top 10 プロジェクトは、セキュリティ専門家やエンジニアにとって有用な認識とガイダンスのリソースです。また、インシデント対応エンジニアがKubernetesの脅威を理解するのに役立つ他のセキュリティフレームワークにマッピングすることも可能です。MITRE ATT&CK テクニックも、攻撃者のテクニックを登録し、ブルーチームが環境を保護するための最適な方法を理解するためによく使用されます。さらに、Kubernetesの脅威モデルを確認することで、すべての攻撃面と主な攻撃ベクトルを理解することができます。
OWASP Kubernetes Top 10は、すべての可能なリスクを全体的な共通性または確率の高い順に並べています。このリサーチでは、この順序を少し修正します。誤設定、監視、脆弱性など、同じカテゴリーに分類しています。そして、設定を監査し、セキュリティポスチャーが最も適切であることを確認するために、いくつかのツールやテクニックを推奨します。
OWASP Kubernetesとは?
Open Web Application Security Project (
OWASP ) は、ソフトウェアのセキュリティを向上させるために活動している非営利財団です。OWASPはWebアプリケーションのセキュリティに重点を置いていますが(そのためこの名前がついています)、時が経つにつれ、現代のシステム設計の性質から範囲を広げています。
アプリケーションの開発が、従来はファイアウォールの背後に隠れたVM上で動作していたモノリシックなアーキテクチャーから、クラウドインフラクチャー上で動作する現代のマイクロサービスワークロードに移り変わるにつれ、それぞれのアプリケーション環境に対するセキュリティ要件を更新することが重要となってきているのです。
そこでOWASP Foundationは、Kubernetes環境に特化した最も一般的な10の攻撃ベクターのリストである「
OWASP Kubernetes Top 10 」を作成しました。
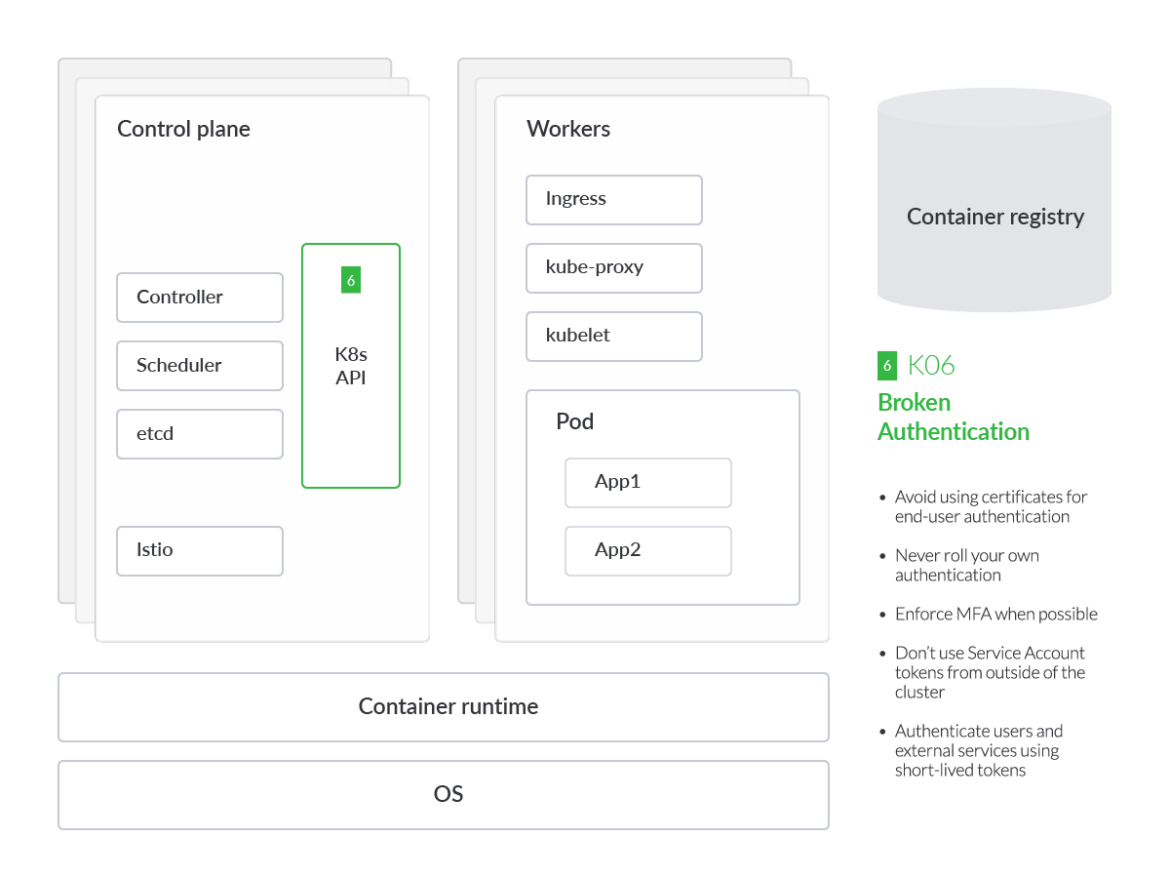
上記のビジュアルでは、理解を助けるために一般化されたKubernetes脅威モデルにマッピングされたOWASP Kubernetesに登場する各リスクによって影響を受けるコンポーネントまたはパーツにスポットライトを当てています。この分析では、各 OWASP リスクに深く入り込み、その脅威が顕著である理由や一般的な緩和策に関する技術的な詳細も提供します。また、リスクを3つのカテゴリーに分類し、可能性の高い順に並べることも有効です。リスクの分類は以下の通りです。
設定の誤り
可視性の欠如
脆弱性管理
設定の誤り
安全でないワークロードの設定
セキュリティは、すべてのクラウドプロバイダーが提供するサービスの最前線にあります。AWS、GCP、Azureなどのクラウドサービスプロバイダーは、サンドボックス機能、仮想ファイアウォール機能、基盤となるサービスの自動更新を数多く実装し、いつでもどこでもビジネスの安全性を確保できるようにしています。また、これらの対策により、オンプレミス環境における従来のセキュリティ負担の一部を軽減することができます。しかし、クラウド環境では、共有セキュリティモデルと呼ばれるものが適用されます。つまり、クラウドサービスの利用者は、自社の対応環境にこれらのセキュリティガードレールを実装する責任を一部負うことになります。また、クラウドの利用モデルや提供するサービスの種類によって、その責任は異なります。
テナントの管理者は、最終的に、ワークロードが安全なイメージを使用していること、パッチが適用され更新されたオペレーティングシステム(OS)上で実行されていること、インフラストラクチャーの設定が継続的に監査され是正されていることを確認する必要があります。クラウドネイティブのワークロードの設定ミスを利用することは、敵対者がお客様の環境にアクセスするための最も一般的な方法の1つです。
オペレーティングシステム
コンテナ化されたワークロードの良いところは、選択したイメージが、特定のOS向けにビルドされたアプリケーションのベースイメージで機能するために必要な依存関係をあらかじめロードしていることが多いことです。
これらのイメージには、ワークロードに必ずしも必要ではない一般的なシステムライブラリやその他のサードパーティコンポーネントがあらかじめパッケージされています。また、マイクロサービスアーキテクチャー(MSA)内などでは、与えられたコンテナイメージが肥大化しすぎて、マイクロサービスの俊敏性に影響を与えることがあります。
私たちは、コンテナ化されたワークロードにおいて、ファイルサイズがはるかに小さいAlpine Linuxイメージのような、最小限の合理化されたイメージを実行することをお勧めします。このような軽量なイメージは、ほとんどの場合において理想的です。パッケージ化されているコンポーネントが少ないので、妥協する可能性も少なくなります。パッケージやライブラリの追加が必要な場合は、ベースとなるAlpineイメージから始めて、期待する動作/性能を維持するために必要なパッケージ/ライブラリを徐々に追加していくことを検討してください。
ワークロードの監査
CIS Benchmark for Kubernetes は、設定ミスを発見するための出発点として使用することができます。例えば、オープンソースプロジェクトの
kube-bench は、テストを設定するためのYAMLファイルを使用して、(CIS) Kubernetes Benchmarkに対してクラスターをチェックすることができます。
CISベンチマークのコントロール例
Minimize the admission of root containers (5.2.6)
Linuxコンテナワークロードは、任意のLinuxユーザーとして実行できる機能を備えています。しかし、ルートユーザーとして実行されるコンテナは、コンテナエスケープ(Linuxホストにおける特権の昇格とその後の横移動)の可能性を増加させます。CISベンチマークでは、すべてのコンテナを定義された非UID 0ユーザーとして実行することを推奨しています。
VIDEO
ルートコンテナのアドミッションの最小化に役立つKubernetes監査ツールの一例として、
kube-admission-webhook があります。これはKubernetesのアドミッションコントローラーのWebhookで、受信したKubernetes APIリクエストを検証し、変換することを実現するものです。これを利用して、クラスター内でのルートコンテナの作成を禁止するなど、セキュリティポリシーを適用することができます。
OPAでワークロードの設定ミスをコントロールする方法
Open Policy Agent(OPA)などのツールをポリシーエンジンとして使用することで、これらの一般的な設定ミスを検出することができます。OPAアドミッション・コントローラーは、スタック全体のポリシーを作成および適用するためのハイレベルな宣言型言語を提供します。
例えば、先に述べた
alpine イメージのアドミッション・コントローラーをビルドしたいとしましょう。しかし、Kubernetesのユーザーの1人は、securityContextをprivileged=trueに設定したいのです。
apiVersion: v1
kind: Pod
metadata:
name: alpine
namespace: default
spec:
containers:
- image: alpine:3.2
command:
- /bin/sh
- "-c"
- "sleep 60m"
imagePullPolicy: IfNotPresent
name: alpine
securityContext:
privileged: true
restartPolicy: Always
これは、Kubernetesの
特権Pod の例です。特権モードでPodを実行することは、Podがホストのリソースやカーネル機能にアクセスできることを意味します。特権ポッドを防御するために、OPA Gatekeeperアドミッション・コントローラーの.regoファイルは以下のようなものにします。
package kubernetes.admission
deny[msg] {
c := input_containers[_]
c.securityContext.privileged
msg := sprintf("Privileged container is not allowed: %v, securityContext: %v",
[c.name, c.securityContext])
}
この場合、以下のような出力になるはずです:
Error from server (Privileged container is not allowed: alpine, securityContext: {"privileged": true}): error when creating "STDIN": admission webhook "validating-webhook.openpolicyagent.org"
クラスターコンポーネントの設定ミス
Kubernetesのコアコンポーネントにおける設定ミスは、予想以上によくあることです。これを防ぐために、IaCやK8s(YAML)マニフェストを手動で確認するのではなく、継続的かつ自動的に監査することで、設定ミスを減らすことができます。
最も危険な設定ミスの1つは、Kubeletの
Anonymous Authentication 設定で、Kubeletへの非認証のリクエストを許可してしまうことです。Kubeletの設定を確認し、以下に説明するフラグがfalseに設定されていることを確認することが強く推奨されます。
ワークロードを監査する場合、アプリケーションをデプロイするさまざまな方法があることを念頭に置くことが重要です。さまざまなクラスターコンポーネントの設定ファイルを使用すると、それらのコンポーネントに対して特定の読み取り/書き込み権限を認可できます。Kubeletの場合、デフォルトでは、他の設定された認証方法で拒否されなかったkubeletのHTTPSエンドポイントへのすべてのリクエストは、匿名リクエストとして扱われ、
system:anonymous というユーザー名と
system:unauthenticatedというグループが付与されます。
これらの未認証リクエストに対する匿名アクセスを無効にするには、
feature flag –anonymous-auth=false を指定して kubelet を起動するだけです。kubeletのようなクラスターコンポーネントを監査すると、kubeletがAPIサーバーと同じリクエスト属性アプローチでAPIリクエストを認証していることがわかります。その結果、以下のようなパーミッションを定義することができます。
POST
GET
PUT
PATCH
DELETE
しかし、kubeletだけでなく、他にも注目すべき
クラスターコンポーネント がたくさんあります。例えば、
kubectlプラグイン はkubectlコマンド自体と同じ権限で実行されるため、プラグインが侵害された場合、特権の昇格やクラスター内の機密リソースへのアクセスに利用される可能性があります。
CIS Benchmark report for Kubernetesに基づき、すべてのクラスターコンポーネントで以下の設定を有効にすることをお勧めします。
etcd
etcd データベースは、Kubernetesがすべてのクラスターデータを集中的に格納するために使用する、高可用性のキー/バリューストアを提供します。etcdは、K8s Secretsと同様に設定データを保存するため、安全に保つことが重要です。データ損失を避けるために、
etcdのデータを定期的にバックアップ することを
強くお勧めします。
ありがたいことに、etcdはビルトインのスナップショット機能をサポートしています。スナップショットは
etcdctl snapshot save コマンドでアクティブなクラスターメンバーから取得することができます。スナップショットを取ることは、パフォーマンスに影響を与えません。以下は、
$ENDPOINT によって提供されるキースペースのスナップショットをファイルsnapshotdbに取る例です。
ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshotdb
kube-apiserver
Kubernetes APIサーバー は、Pod、サービス、ReplicationControllerなどを含むAPIオブジェクトのデータを検証し、設定するものです。APIサーバーはREST操作を提供し、他のすべてのコンポーネントが相互作用するクラスターの共有状態へのフロントエンドを提供します。これはクラスターの運用に不可欠であり、攻撃対象として高い価値を持つものであることは言うまでもありません。セキュリティの観点から、APIサーバーへのすべての接続、Control Plane内部での通信、およびControl Planeとkubeletコンポーネント間の通信は、TLS接続を使用して到達できるようにのみプロビジョニングする必要があります。
デフォルトでは、TLSはkube-apiserverに対して未構成になっています。Kube-benchの結果でこのフラグが立った場合は、kube-apiserverの機能フラグ
--tls-cert-file=[file] と
--tls-private-key-file=[file] でTLSを有効にするだけでよいでしょう。Kubernetesクラスターは定期的にスケールアップ、スケールダウンする傾向があるため、
KubernetesのTLSブートストラップ機能 を利用することをお勧めします。これにより、上記の手動ワークフローに従うのではなく、Kubernetesクラスター内部で自動的に証明書の署名とTLSの設定を行うことができます。
また、特に長寿命のKubernetesクラスターでは、これらの証明書を定期的にローテーションすることが重要です。
幸い、Kubernetes v.1.8以上のバージョンでは、これらの
証明書のローテーションを支援する自動化 が用意されています。APIサーバーのリクエストも認証される必要がありますが、これについては「壊れた認証メカニズム」のセクションで後述します。
CoreDNS
CoreDNS は、KubernetesクラスターDNSとして機能するDNSサーバー技術で、
CNCF によってホストされています。Kubernetesのバージョンv.1.11以降、CoreDNSはkube-dnsに取って代わられました。クラスター内の名前解決は、K8sに固有のオーケストレーテッドでエフェメラルなワークロードやサービスの場所を特定するために重要です。
CoreDNSは、kube-dns、特にdnsmasq(DNSリゾルバー)で見つかったセキュリティ脆弱性の束に対処しました。このDNSリゾルバーは、最終的なDNS解決サービスの実行を担うコンポーネントであるSkyDNSからの応答をキャッシュする役割を担っていました。
CoreDNSは、kube-dnsのdnsmasq機能のセキュリティ脆弱性への対処のほか、SkyDNSのパフォーマンス問題にも対応しています。kube-dnsを使用する場合、DNSサービスの健全性を監視し、メトリクスレポートを処理するためのサイドカープロキシーも含まれます。
CoreDNSは、単一のコンテナ内でkube-dnsのすべての機能を提供することで、これらのセキュリティやパフォーマンス関連の問題の多くに対処しています。しかし、それでも妥協することは可能です。その結果、CoreDNSのコンプライアンスチェックには、再びkube-benchを使用することが重要です。
過剰に寛容なRBAC設定
Role-based access control (RBAC)は、組織内の個々のユーザーの役割に基づいて、コンピュータまたはネットワークリソースへのアクセスを規制する方法です。RBACの設定を誤ると、攻撃者が特権を昇格させ、クラスター全体を完全に制御できるようになる可能性があります。
RBACルールの作成は、比較的簡単です。たとえば、
Kubernetesクラスター の「default」ネームスペースにあるPodに対して読み取り専用のCRUDアクション(
get, watch, list など)を許可し、それらのPodに対するCreate、Updated、Deleteアクションを禁止する寛容なポリシーを作成するには、次のようになります。
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
Metadata:
namespace: default
name: pod-reader
Rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]
これらのRBACルールを長期的に管理する場合、問題が発生します。管理者は、上で見たように各ネームスペースに個別のロールをビルドするのを避けるために、
ClusterRole リソースを管理する必要がありそうです。ClusterRoleを使えば、ワークロードへのアクセスを許可するための、クラスタースコープのルールをビルドすることができます。
RoleBindingsは、上記のロールをユーザーにバインドするために使用されます。
他のIdentity & Access Management (IAM) の実践と同様に、個々のリソースに過剰な権限を付与することなく、各ユーザーがKubernetes内のリソースに正しくアクセスできることを確認する必要があります。以下のマニフェストは、Kubernetesのサービスアカウントまたはユーザーにロールをバインドすることを推奨する方法を示しているはずです。
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
Metadata:
name: read-pods
namespace: default
Subjects:
- kind: User
name: nigeldouglas
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.io
RBACの設定ミスをスキャンすることで、クラスターのセキュリティ姿勢を積極的に強化し、同時にパーミッション付与のプロセスを効率化することができます。クラウドネイティブチームが過剰な権限を付与する主な理由の1つは、本番環境での個々のRBACポリシーの管理が複雑であるためです。つまり、クラスター内のユーザーとロールが多すぎて、マニフェストコードを手動でレビューして管理することができない場合があります。そのため、RBAC の管理、監査、およびコンプライアンス チェックを処理するために特別に構築されたツールがあります。
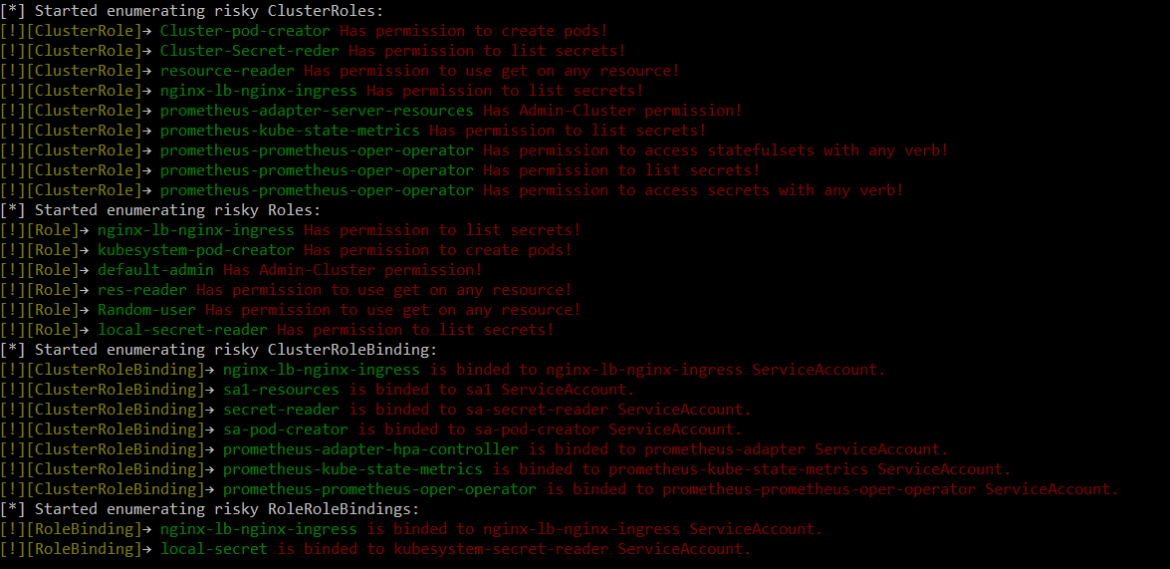
Audit RBAC
RBAC Audit は、CyberArkのチームによって作成されたツールです。このツールは、RBAC内のリスクのあるロールについてKubernetesクラスターをスキャンするために設計されており、python3が必要です。このpythonツールは、1つのコマンドで実行することができます。
ExtensiveRoleCheck.py --clusterRole clusterroles.json --role Roles.json --rolebindings rolebindings.json --cluseterolebindings clusterrolebindings.json
以下のような出力になるはずです:
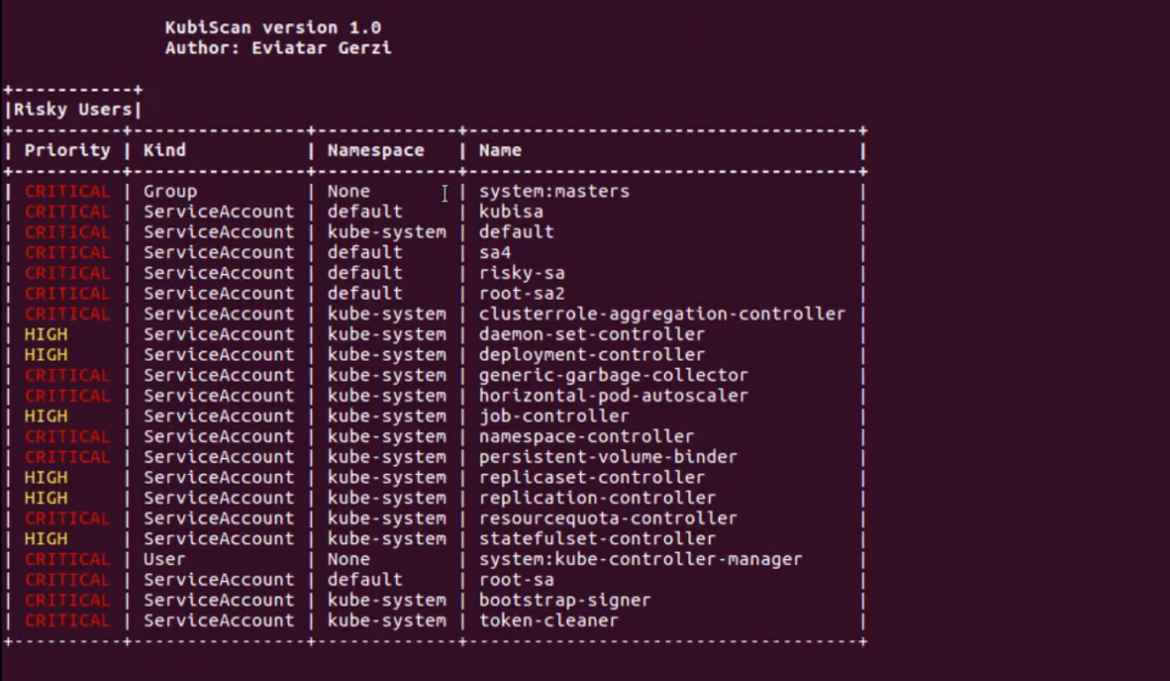
Kubiscan
Kubiscan は、CyberArkのチームによってビルドされた別のツールです。RBAC Auditとは異なり、このツールはKubernetesのRBAC認可モデル(RBACロールではなく)のリスクのあるパーミッションについてKubernetesクラスターをスキャンするために設計されています。繰り返しになりますが、このツールを動作させるには、Python v.3.6以上が必要です。
すべての例を見るには、python3 KubiScan.py -eを実行するか、コンテナ内で、kubiscan -eを実行してください。
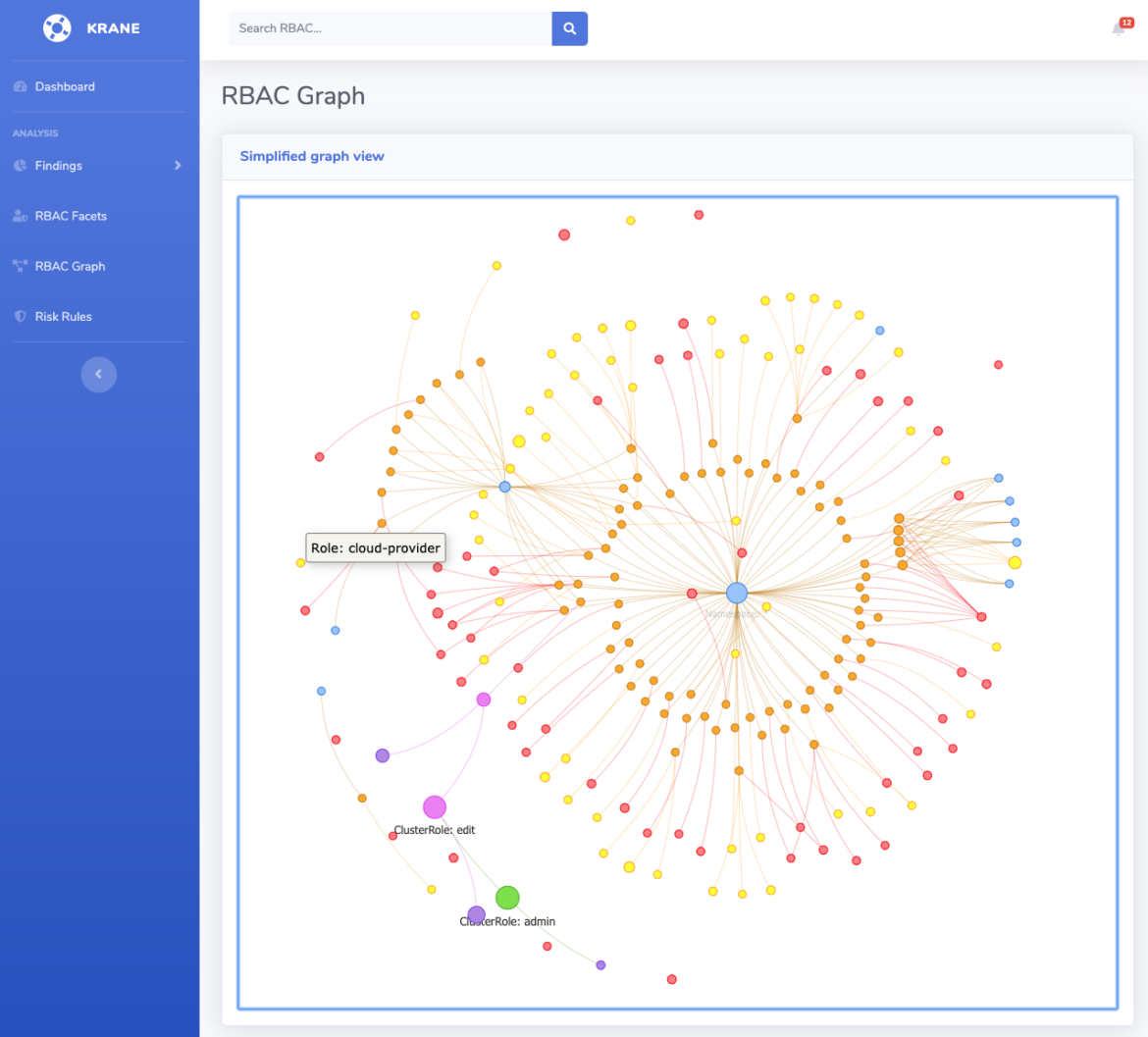
Krane
Krane はKubernetes RBACのための静的解析ツールです。Kubiscanと同様に、K8sのRBAC設計における潜在的なセキュリティリスクを特定し、それを軽減する方法を提案します。
これらのツールの大きな違いは、Kraneがクラスターの現在のRBACセキュリティポスチャーのダッシュボードを提供し、その定義を通してナビゲートできることです。
実行中のクラスターに対してRBACレポートを実行したい場合、以下のようにkubectlコンテキストを提供する必要があります:
krane report -k <kubectl-context>
RBACの設計を上記のようなツリーデザインで、ネットワークトポロジーグラフと最新のレポート結果を表示したい場合は、以下のコマンドでダッシュボードサーバーを起動する必要があります:
krane dashboard -c nigel-eks-cluster
-c 機能フラグは、お使いの環境でのクラスター名を指します。すべてのクラスターのダッシュボードが必要な場合は、上記のコマンドから-cの参照を削除するだけです。
ネットワークセグメンテーションコントロールの欠落
Kubernetesはデフォルトで、「
フラットネットワーク 」設計として知られているものを定義しています。
これにより、ワークロードは事前の設定なしに互いに自由に通信することができます。しかも、何の制限もなくこれを行うことができます。もし攻撃者が実行中のワークロードを悪用することができれば、彼らは本質的に、クラスター内の他のすべてのPodに対してデータ漏洩を実行するためのアクセス権を持つことになります。組織内のゼロトラストアーキテクチャに重点を置いているクラスター運用者は、Kubernetesネットワークポリシーを詳しく見て、サービスが適切に制限されていることを確認することをお勧めします。
Kubernetesは、ネットワーク・セグメンテーション・コントロールの正しい構成に対処するためのソリューションを提供しています。ここでは、そのうちの2つを紹介します。
Istioによるサービスメッシュ
Istio は、サービスメッシュソリューションを提供します。これにより、セキュリティとネットワークのチームは、マイクロサービスに出入りするネットワークトラフィックにマイクロセグメンテーションを実施するために、マイクロサービス間のトラフィックフローの管理、ポリシーの適用、テレメトリーデータの集約を行うことができます。
執筆時点では、このサービスは、クラスター内の各マイクロサービスへのサイドカー・プロキシー一式の実装に依存しています。しかし、Istioプロジェクトは、今年中に
サイドカーレスのアプローチに移りたい と考えています。
サイドカー技術は「Envoy」と呼ばれています。クラスター内のサービス間のingress/egressトラフィックや、サービスからサービスメッシュアーキテクチャー内の外部サービスへのトラフィックを処理するためにEnvoyに依存しています。プロキシを使う明確な利点は、安全なマイクロサービスメッシュを提供し、トラフィックミラーリング、ディスカバリ、豊富なレイヤー7トラフィックルーティング、サーキットブレーカー、ポリシー強制、テレメトリ記録/レポート機能、そして最も重要なことですが、自動証明ローテーションですべての通信に自動mTLSを提供することです!プロキシを使用すると、トラフィックミラーリング、ディスカバリ、レイヤー7トラフィックルーティングを提供することができます。
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
Metadata:
name: httpbin
namespace: default
Spec:
action: DENY
Rules:
- from:
- source:
namespaces: ["prod"]
To:
- operation:
methods: ["POST"]
上記の
Istio AuthorizationPolicy は、「prod」本番環境ネームスペースから「default」ネームスペースのすべてのワークロードの「POST」メソッドへのすべてのリクエストに対して、アクションを「DENY」に設定しています。
このポリシーは非常に便利です。L3/L4(ネットワーク層)で IP アドレスとポートに基づいてのみトラフィックをドロップできる Calico ネットワークポリシーとは異なり、認可ポリシーは L7(アプリケーション層)で POST/GET などの HTTP/S verbsに基づいてトラフィックを拒否しているのです。これは、Web Application Firewall (WAF) を実装する際に重要です。
Istioの監視が、Istioのサービスが良好な状態にあることを保証するのに役立つ ことをご覧ください。
CNI
Mutual TLS (mTLS) によるワークロード間のトラフィックの暗号化や、HTTP/s トラフィック制御など、サービスメッシュには大きなメリットがありますが、サービスメッシュの管理には複雑な点もあることは知っておく必要があります。各ワークロードの横にサイドカーを使用すると、クラスタのオーバーヘッドが増えるだけでなく、本番環境でサイドカーに問題が発生したときにトラブルシューティングが必要になるなど、望ましくない問題が発生します。
多くの組織では、デフォルトでContainer Network Interface (CNI)のみを実装することにしています。CNIは、その名が示すように、クラスターのネットワーキングインターフェイスです。
Project Calico や
Cilium のようなCNIには、独自のポリシーエンフォースメントが付属しています。IstioがL7トラフィックに対してトラフィック制御を行うのに対し、CNIはネットワーク層のトラフィック(L3/L4)により重点を置く傾向があります。
次の
CiliumNetworkPolicy は、例として、app=frontend というラベルを持つすべてのエンドポイントが、ポート 80 の TCP を使用して、任意のレイヤー 3 の宛先にパケットを送信できることのみを制限しています:
apiVersion: "cilium.io/v2"
kind: CiliumNetworkPolicy
Metadata:
name: "l4-rule"
Spec:
endpointSelector:
matchLabels:
app: frontend
Egress:
- toPorts:
- ports:
- port: "80"
protocol: TCP
Istio AuthorizationPolicyを使用して、L7/アプリケーション層でWAFのような機能を提供することを述べました。しかし、敵対者が過剰なTCP/UDPトラフィックでPod/エンドポイントをフラッディングした場合、ネットワーク層でDDoS(
Distributed Denial-of-Service )攻撃が起こる可能性もあります。同様に、固定IPとポートに基づく既知の/悪意のあるC2サーバーに、感染したワークロードが話しかけるのを防御するために使用することも可能です。
もっと詳しく知りたいですか?
CalicoとFalcoを使用してKubernetesでDDoS攻撃を防御する方法 についてもっと学びましょう。
可視性の欠如
不十分なロギングと監視
Kubernetesはデフォルトで監査ロギング機能を提供しています。
監査ログ は、セキュリティに関連するさまざまなイベントを時系列で表示します。これらのアクティビティは、ユーザー、Kubernetes APIを使用するアプリケーション、またはControl Plane自体によって生成される可能性があります。
しかし、Kubernetes Audit Logsに限らず、注目すべきログソースは他にもあります。それらは、ホスト固有のOSログ、ネットワークアクティビティログ(
KubernetesアドオンのCoreDNSを監視できるDNSなど )、Kubernetesクラウドの基盤としても機能するクラウドプロバイダーなどです。
これらの無数に存在するログソースをすべて一元管理するツールがなければ、侵入された場合に利用するのは難しいでしょう。そこで、PrometheusやGrafana、Falcoのようなツールが役に立ちます。
Prometheus
Prometheus は、モダンなクラウドネイティブアプリケーションとKubernetesを監視するための、オープンソースでコミュニティ主導のプロジェクトです。CNCFのグラデュエーションメンバーであり、活発な開発者とユーザーコミュニティを持っています。
Grafana
Prometheusと同様に、
Grafana も大きなコミュニティのバックアップを受けたオープンソースのツーリングです。Grafanaは、メトリクスがどこに保存されていても、クエリー、可視化、アラート、および理解を可能にします。ユーザーは、ダッシュボードを作成し、探索し、チームと共有することができます。
Falco(ランタイム検出)
クラウドネイティブのランタイムセキュリティプロジェクトであるFalcoは、Kubernetesの脅威検出のデファクトスタンダードです。Falcoは、アプリケーションやコンテナの挙動を観察することで、ランタイムで脅威を検出します。Falcoは、Falco Pluginsにより、クラウド環境全体に脅威の検知を拡張します。
Falcoは、インキュベーションレベルのプロジェクトとしてCNCFに参加した最初のランタイムセキュリティプロジェクトです。Falcoはセキュリティカメラとして機能し、すべてのKubernetes環境において予期せぬ動作、侵入、データの盗難をリアルタイムで検出します。Falco v.0.13では、サポートするイベントソースのリストに
Kubernetes Audit Events を追加しました。これは、既存のシステムコールイベントのサポートに追加されたものです。監査イベントの改良された実装がKubernetes v1.11で導入され、kube-apiserverへのリクエストとレスポンスのログが提供されるようになりました。
ほぼすべてのクラスター管理タスクはAPIサーバーを介して実行されるため、監査ログはクラスターに加えられた変更を効果的に追跡することができます。
その例としては、以下が挙げられます:
Pod、サービス、デプロイメント、デーモンセットなどの作成と破棄
ConfigMapまたはシークレットの作成、更新、および削除
任意のエンドポイントに導入された変更のサブスクライブ
一元化されたポリシー適用の欠如
マルチクラスターやマルチクラウドの環境でルールを適用する必要がある場合、セキュリティポリシーを適用するのは難しい作業になります。デフォルトでは、セキュリティチームは、これらの異種環境全体にわたって個別にリスクを管理する必要があります。
設定ミスを集中的に検出、修正、および防止するためのデフォルトの方法がないため、クラスターが危険にさらされる可能性があります。
アドミッションコントローラー
アドミッションコントローラー は、Kubernetes APIサーバーへのリクエストを永続化する前にインターセプトします。リクエストはまず認証と認可を受ける必要があり、その後、リクエストの実行を許可するかどうかが判断されます。例えば、以下のようなAdmissionコントローラーの設定を作成できます:
apiVersion: apiserver.config.k8s.io/v1
kind: AdmissionConfiguration
plugins:
- name: ImagePolicyWebhook
configuration:
imagePolicy:
kubeConfigFile: <path-to-kubeconfig-file>
allowTTL: 50
denyTTL: 50
retryBackoff: 500
defaultAllow: true
ImagePolicyWebhookの設定は、バックエンドへの接続を設定するkubeconfig形式のファイルを参照しています。このアドミッションコントローラーのポイントは、バックエンドがTLSで通信することを確認することです。
allowTTL: 50は承認をキャッシュする時間を秒単位で設定し、同様に、denyTTL: 50は拒否をキャッシュする時間を秒単位で設定します。アドミッションコントローラーは、オブジェクトの作成、削除、修正、またはプロキシへの接続のリクエストを制限するために使用できます。
残念ながら、AdmissionConfiguration リソースはまだ各クラスターで個別に管理する必要があります。もし、あるクラスターにこのファイルを適用するのを忘れると、このポリシー条件が失われてしまうのです。ありがたいことに、Open Policy Agent (OPA) の
Kube-Mgmt ツールのようなプロジェクトが、アドミッションコントローラーを個別に管理する代わりに、Kubernetes 内の OPA インスタンスのポリシーとデータの管理を支援してくれます。
Kube-mgmtツールは、KubernetesのConfigMapsに格納されたポリシーとJSONデータを自動的に検出し、OPAにロードします。ポリシーは機能フラグ
--enable-policy=falseで簡単に無効化でき、データも同様に
--enable-data=falseで無効化することができる。
アドミッションコントローラーは、Kubernetesのコンテキストを必要とするポリシーを適用し、クラスターの最後の防衛線を作るために、コンテナ・セキュリティ戦略の重要な要素です。このリサーチの後半でイメージスキャンについて触れますが、イメージスキャンはKubernetesアドミッションコントローラーを介して強制することもできることを知っておいてください。
ランタイム検出
同じ構成をミラーリングする場合、すべてのクラスターへのセキュリティポリシー構成のデプロイを標準化する必要があります。根本的に異なるクラスター構成の場合、独自に設計したセキュリティポリシーが必要になるかもしれません。いずれの場合も、どのセキュリティポリシーが各クラスター環境にデプロイされたかをどうやって知ることができるのでしょうか?そこで、Falcoの出番となるわけです。
クラスターがkube-mgmtを使用しておらず、これらのアドミッションコントローラーを管理する集中的な方法がないと仮定してみましょう。あるユーザーが誤って、ConfigMapマニフェスト内で公開されたプライベートな認証情報を持つConfigMapを作成しました。残念ながら、この動作を防御するために新しく作成されたクラスターにアドミッションコントローラーは設定されていませんでした。一つのルールで、Falcoはまさにこの挙動が発生したときに管理者に警告することができます。
- rule: Create/Modify Configmap With Private Credentials
desc: >
Detect creating/modifying a configmap containing a private credential
condition: kevt and configmap and kmodify and contains_private_credentials
output: >-
K8s configmap with private credential (user=%ka.user.name verb=%ka.verb
configmap=%ka.req.configmap.name namespace=%ka.target.namespace)
priority: warning
source: k8s_audit
append: false
exceptions:
- name: configmaps
fields:
- ka.target.namespace
- ka.req.configmap.name
上記のFalcoのルールでは、Kubernetesの監査ログをソースとして、任意のネームスペースのConfigMapsで公開される可能性のあるプライベートクレデンシャルの例を示しています。プライベートクレデンシャルは、以下のいずれかの条件として定義されます。
condition: (ka.req.configmap.obj contains "aws_access_key_id" or
ka.req.configmap.obj contains "aws-access-key-id" or
ka.req.configmap.obj contains "aws_s3_access_key_id" or
ka.req.configmap.obj contains "aws-s3-access-key-id" or
ka.req.configmap.obj contains "password" or
ka.req.configmap.obj contains "passphrase")
シークレット管理の失敗
Kubernetesでは、
Secret はパスワードやトークンなどの機密データを保持するために設計されたオブジェクトです。この種の機密データをアプリケーションのコードに入れないようにするには、Podの
specification でK8sのシークレットを参照するだけでよいのです。これにより、エンジニアは、Podマニフェストやコンテナイメージに直接、資格情報や機密データをハードコードするのを避けることができます。
この設計にかかわらず、K8sシークレットはまだ侵害される可能性があります。K8sのネイティブなシークレットメカニズムは本質的に抽象化されたもので、データは依然として前述のetcdデータベースに格納され、ずっと亀の子になっています。そのため、企業にとって重要なのは、広範なシークレット管理戦略の一環として、K8s シークレットにどのように認証情報とキーが保存され、アクセスされるかを評価することです。K8sは、保存された状態におけるデータの暗号化、アクセスコントロール、ロギングなど、その他のセキュリティコントロールも提供します。
保存された状態におけるシークレット情報の暗号化
Kubernetesで使用されるetcdデータベースの大きな弱点の1つは、Kubernetes APIを介してアクセス可能なすべてのデータが含まれているため、攻撃者がシークレットを広く可視化できる可能性があることです。そのため、シークレットを暗号化することは非常に重要です。
v.1.7で、
Kubernetesはencryption at restをサポート しました。このオプションは、etcdのシークレットリソースを暗号化し、etcdのバックアップにアクセスした当事者がシークレットの内容を見ることを防ぎます。この機能は現在ベータ版であり、デフォルトでは有効ではありませんが、バックアップが暗号化されていない場合や攻撃者がetcdに読み取りアクセスした場合に、追加レベルの防御を提供します。
以下は、EncryptionConfigurationカスタムリソースを作成する例です:
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
Keys:
- name: key1
secret: <BASE 64 ENCODED SECRET>
- identity: {}
セキュリティの設定ミスに対処する
シークレットが保存された状態で暗号化されていることを保証することは別として、シークレットが間違った人の手に渡るのを防ぐ必要があります。脆弱性管理、イメージスキャン、ネットワークポリシーの強制が、どのようにアプリケーションを危険から守るために使われるかを説明しました。しかし、シークレット(機密情報)の漏洩を防ぐには、可能な限りRBACをロックダウンする必要があります。
すべてのサービスアカウントとユーザーアクセスは
最小限の特権 にとどめる。ユーザーが「クレデンシャル共有」するようなシナリオ、つまり本質的に「admin」や「default」のようなサービスアカウントを使用するようなシナリオはあってはなりません。各ユーザーは、「Nigel」「William」「Douglas」などの明確に定義されたサービスアカウント名を持つべきです。このシナリオでは、Service Accountが本来行うべきでないことを行っている場合、アカウントのアクティビティを簡単に監査し、および/またはクラスターにインストールされているサードパーティプラグインとソフトウェアのRBAC設定を監査して、完全な昇格管理権限を必要としない「Nigel」のようなユーザーに不必要にKubernetes シークレットへのアクセスが許可されないようにすることが可能です。
以下のシナリオでは、’test’ ネームスペースにあるシークレットへの読み取りアクセスを許可するために使用される ClusterRole を作成します。この場合、このクラスターロールに割り当てられたユーザは、このおかしなネームスペースの外にあるシークレットにはアクセスできません。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
Metadata:
name: secret-reader
namespace: test
Rules:
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "watch", "list"]
ロギングと監査が確実に実施されていること
アプリケーションログは、開発者とセキュリティチームが、アプリケーションの内部で何が起こっているかをよりよく理解するのに役立ちま す。開発者のための主要なユースケースは、アプリケーションのパフォーマンスに影響を与える問題のデバッグを支援することです。多くの場合、ログは Grafana や Prometheus などの監視ソリューションに送られ、可用性やパフォーマンスの問題など、クラスターイベントへの対応時間を改善します。コンテナエンジンを含むほとんどのモダンなアプリケーションは、デフォルトでサポートされている何らかのロギング機構を持っています。
コンテナ型アプリケーションで最も簡単かつ最も採用されているロギング方法は、標準出力(stdout)および標準エラーストリームへの書き込みです。以下のFalcoの例では、各アラートに対して1行が出力されます。
stdout_output:
enabled: true
イベントから発生する潜在的なセキュリティ問題を特定するために、Kubernetesの管理者は、クラウド監査ログや一般的なホストのシステムコールなどのイベントデータをFalco脅威検出エンジンに単純にストリーミングすることができます。
Falcoセキュリティエンジンからの標準出力(stdout)を
Fluentd または
Logstash にストリーミングすることで、プラットフォームエンジニアリングやセキュリティオペレーションなどの追加チームは、クラウドやコンテナ環境からイベントデータを簡単にキャプチャーすることができます。組織は、単なる生のイベントデータとは対照的に、より有用なセキュリティシグナルを
Elasticsearch や他のSIEMソリューションに保存することができます。
また、ダッシュボードを作成してセキュリティイベントを可視化し、インシデント対応チームに警告することも可能です:
10:20:22.408091526: File created below /dev by untrusted program (user=nigel.douglas command=%proc.cmdline file=%fd.name)
脆弱性管理
サプライチェーンにおける脆弱性
設定ミスに起因する4つのリスクに続いて、脆弱性に関連するリスクについて詳しく説明します。
SolarWinds社 の情報漏えいに見られるように、
サプライチェーンへの攻撃 は増加傾向にあります。SolarWindsのソフトウェアソリューション「Orion」は、ロシアの脅威グループ
APT29 (通称Cozy Bear)によって侵害されました。これは長期間にわたって行われた
ゼロデイ 攻撃であり、Orionを環境で稼働させていたSolarWindsのお客様は、この侵害に気づかなかったということです。APT29の敵対者は、このSolarWindsの悪用により、エアギャップがないOrionインスタンスにアクセスできる可能性があります。
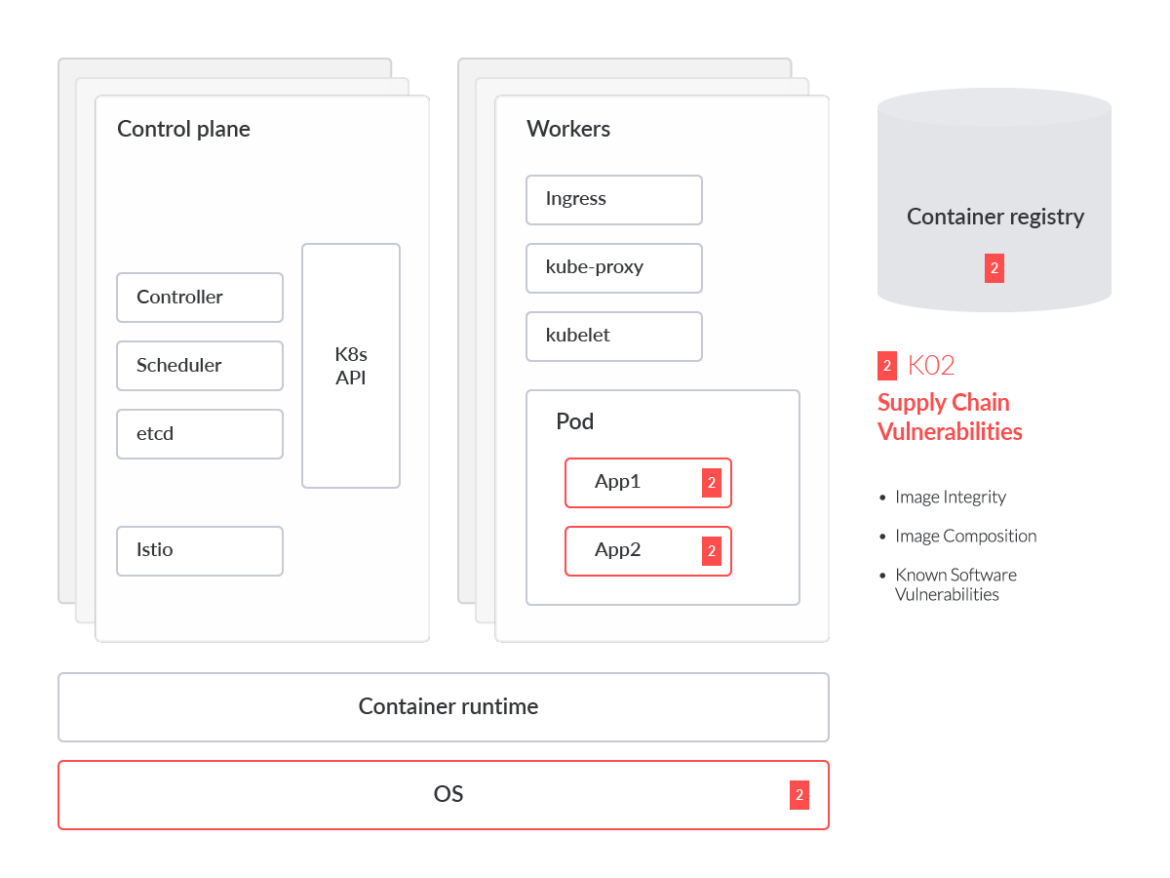
SolarWindsは、企業のセキュリティスタック内で侵害されたソリューションの一例に過ぎません。Kubernetesの場合、1つのコンテナ化されたワークロードだけでも、何百ものサードパーティコンポーネントや依存関係に依存することがあり、各段階での起源の信頼性を確保することが極めて困難になっています。これらの課題には、イメージの整合性、イメージの構成、既知のソフトウェアの脆弱性などが含まれますが、これらに限定されるものではありません。
それぞれについて詳しく見ていきましょう。
イメージ
コンテナイメージ は、アプリケーションとそのソフトウェアの依存関係をすべてカプセル化したバイナリデータを表します。コンテナイメージは、スタンドアロンで実行可能なソフトウェアバンドルであり(実行中のコンテナにインスタンス化されると)、その実行環境について非常によく定義された仮定を持っています。
Sysdig脅威リサーチチームは、Docker Hub上のコンテナイメージにどのような悪意のあるペイロードが隠れているかを理解するために、25万以上のLinuxイメージの
分析 を実施しました。
Sysdig TRTは、上図のようにいくつかのカテゴリに基づいて悪意のあるイメージを収集しました。この分析では、悪意のあるIPアドレスやドメイン、およびシークレットの2つの主要なカテゴリーに焦点を当てました。どちらも、Docker Hubのようなパブリックレジストリで利用可能なイメージをダウンロードしてデプロイする人々にとって脅威となり、その環境を高いリスクにさらすことになります。
イメージスキャンに関する追加のガイダンスは、
12のイメージスキャンのベストプラクティス のリサーチから見つけることができます。このアドバイスは、本番環境でコンテナやKubernetesの運用を始めたばかりであっても、現在のDevOpsワークフローにさらなるセキュリティを組み込みたい場合であっても、役に立つでしょう。
依存関係
クラスターに多数のリソースがある場合、それらの間のすべての関係を簡単に見失ってしまうことがあります。「小さな」クラスターであっても、コンテナ化とオーケストレーションによって、予想以上に多くのサービスを持つことができます。すべてのサービス、リソース、依存関係を追跡することは、マルチクラスターやマルチクラウド環境上で分散チームを管理している場合は、さらに困難です。
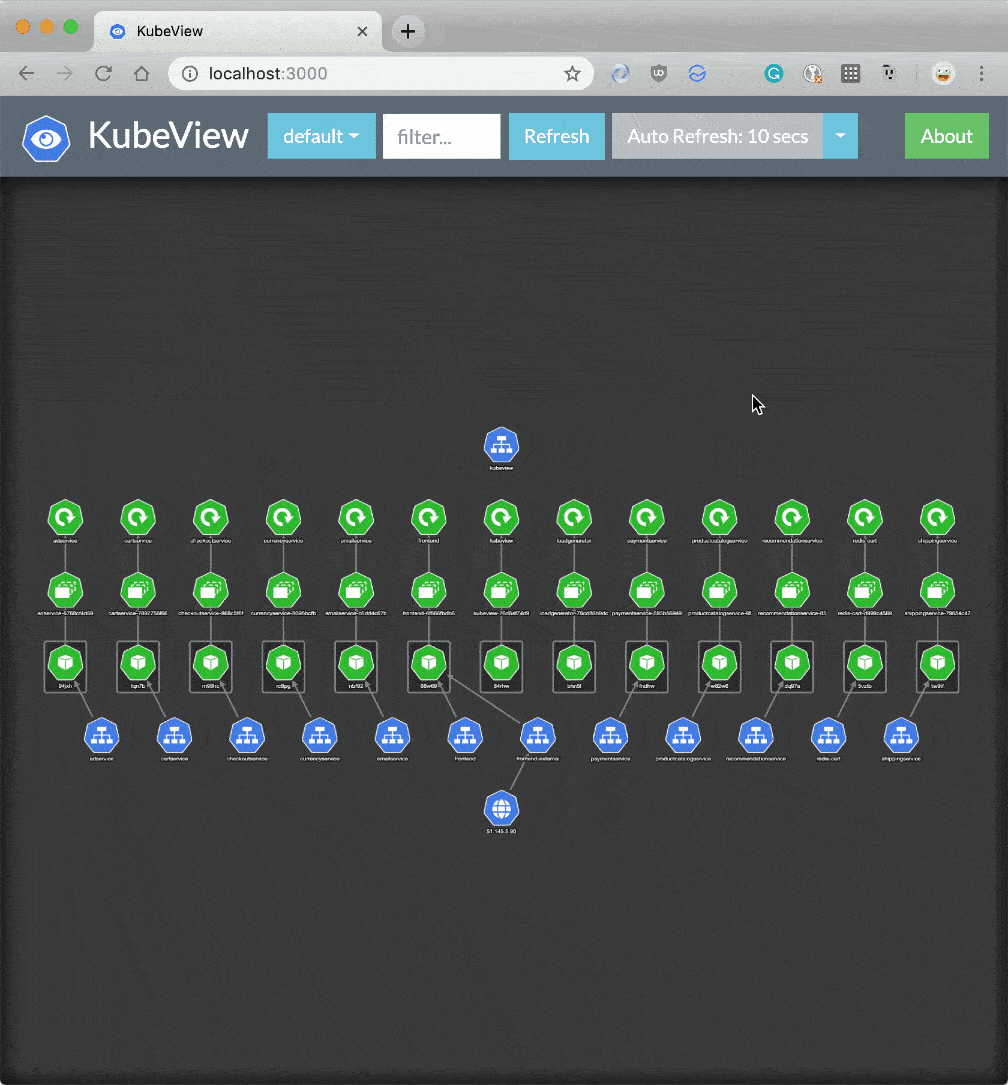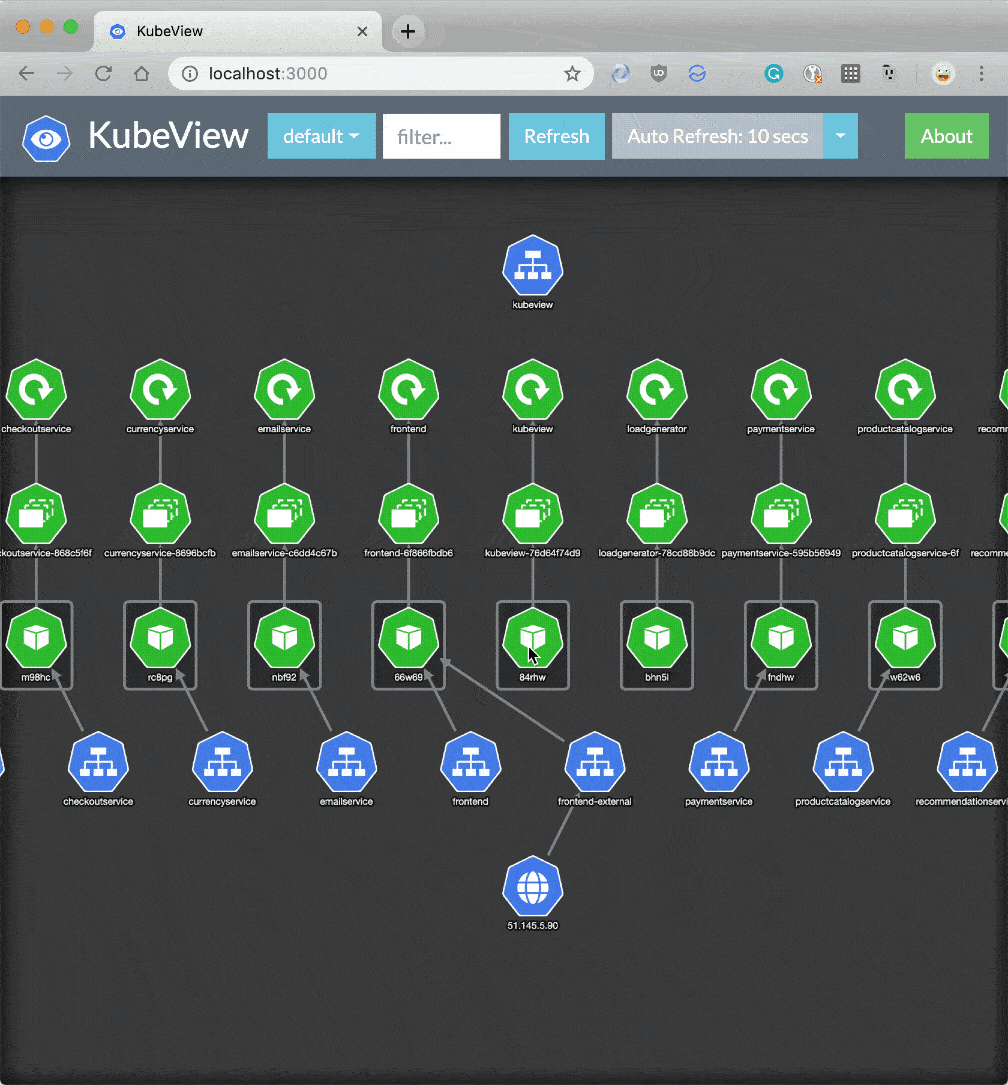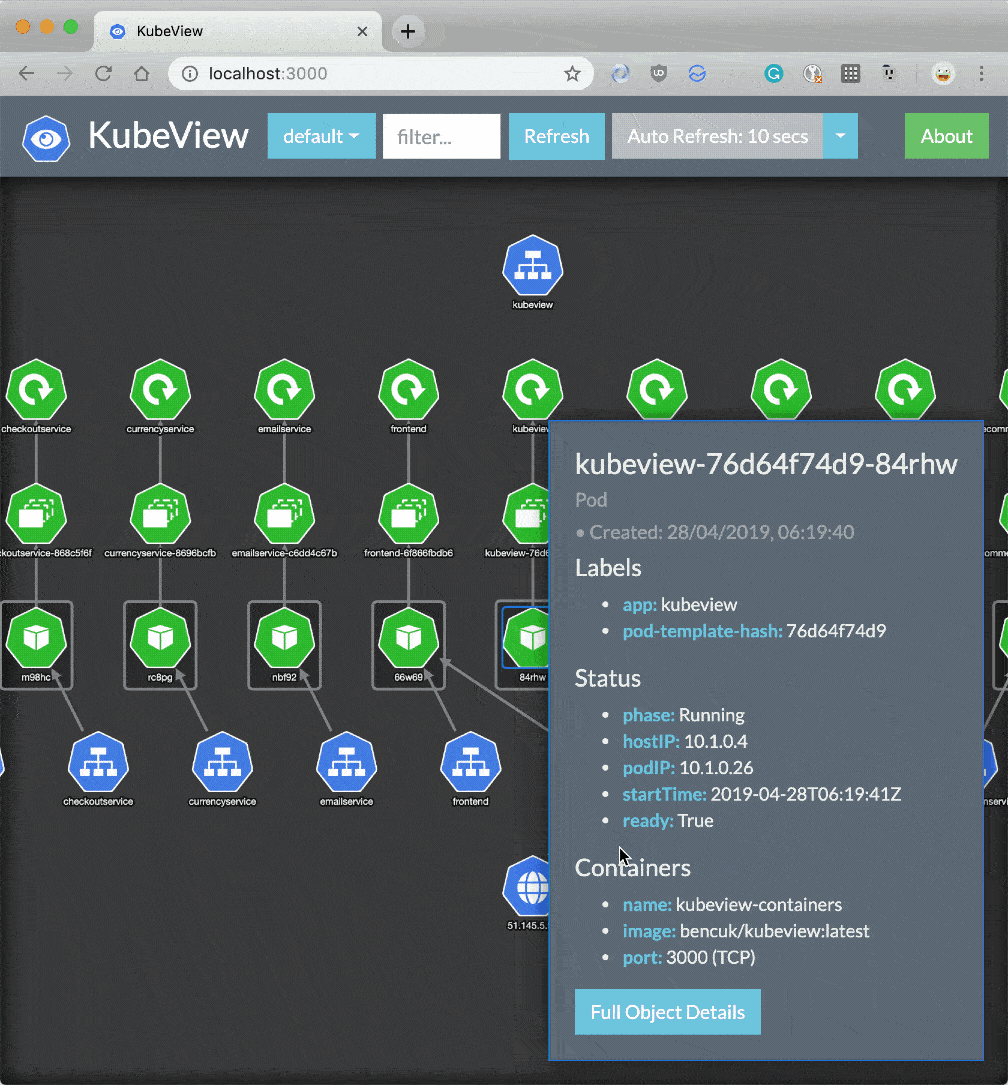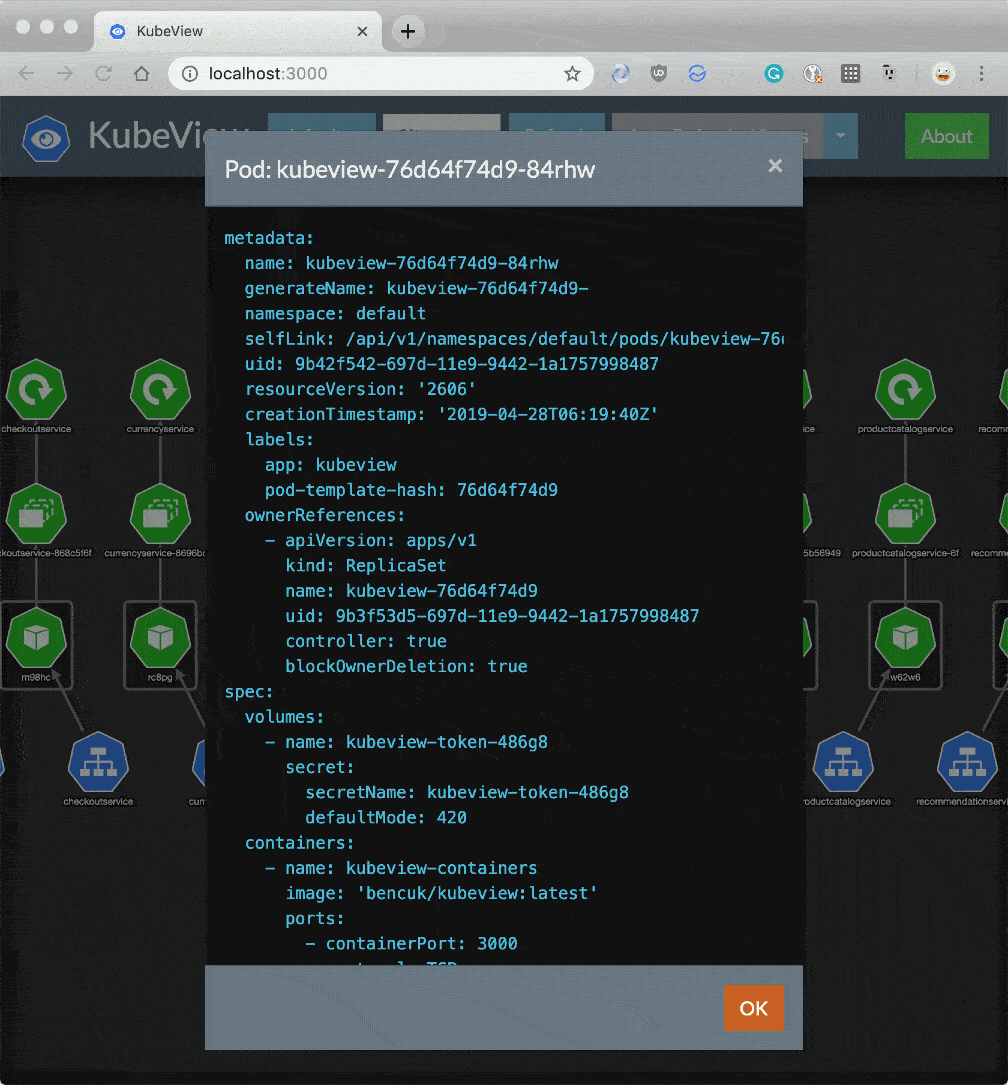
Kubernetesは、デプロイメント、サービス、Persistent Volume Claims(PVC)など間の依存関係を可視化するメカニズムをデフォルトで提供しません。
KubeView は、クラスター内の依存関係を表示および監査するための素晴らしいオープンソースツールです。これは、APIオブジェクトとそれらがどのように相互接続されているかをマッピングします。データはKubernetes APIからリアルタイムでフェッチされます。一部のオブジェクト(Pod、ReplicaSets、デプロイメント)の状態は、赤と緑に色分けされ、そのステータスと健全性を表しています。
レジストリ
レジストリはステートレスでスケーラブルなサーバーサイドアプリケーションで、コンテナイメージを保存し、配布することができます。
イメージを実装するKubernetesリソース(Pod、デプロイメントなど)は、imagePull シークレットを使用して、さまざまなイメージレジストリへの認証に必要なクレデンシャルを保持することになります。このセクションで説明した多くの問題と同様に、標準的なKubernetesデプロイメントでは、イメージの脆弱性をスキャンする固有の方法はありません。
しかし、プライベートな専用のイメージレジストリであっても、イメージの脆弱性をスキャンする必要があります。しかし、Kubernetesはこれを行うためのデフォルトで統合された方法をアウトオブボックスで提供しません。シフト・レフト・セキュリティのアプローチの一環として、イメージのビルドに使用されるCI/CDパイプラインでイメージをスキャンする必要があります。詳しくは、
Shift-leftとShield-rightの実践によるサイバーセキュリティの強化 のリサーチを参照してください。
Sysdigは、一般的なCI/CDサービスに対してそれを行う方法の例を示した詳細な技術ガイダンスを執筆し、あなたのパイプラインにおける脆弱性を防ぐためのセキュリティの別の層を提供しています。
もう1つのセキュリティ層は、レジストリやリポジトリに送信する
イメージに署名・検証を行う プロセスです。これは、真正性と統合性を確保することで、サプライチェーン攻撃を軽減します。Kubernetesの開発とデプロイを保護し、いつでも実行しているコンテナのインベントリをよりよく管理することができます。
壊れた認証メカニズム
Kubernetesクラスターにいかに安全にアクセスするかは優先すべきことであり、Kubernetesにおける適切な認証は、最初の攻撃フェーズでほとんどの脅威を回避するための鍵となります。K8s管理者は、K8s APIを通じて、あるいはK8sダッシュボードを通じて、直接クラスターと対話することができます。技術的に言えば、K8sダッシュボードは順番にAPIサーバーやKubelet APIなど、それらのAPIに通信します。認証を普遍的に実施することは、セキュリティのベストプラクティスとして重要です。
2019年に発生したTeslaのクリプトマイニングインシデント に見られるように、攻撃者はパスワードで保護されていないKubernetesダッシュボードに侵入しています。Kubernetesは高度に設定可能であるため、多くのコンポーネントが有効化されていなかったり、多くの異なる環境で動作できるように基本認証を使用していたりする始末です。このため、クラスターとクラウドのセキュリティの態勢を整える際に課題が生じます。
クラスターに対して認証を行おうとする人がいる場合、主な懸念事項は認証情報の管理です。最もありそうなケースは、偶発的なエラーによって、.kubeconfigなどの設定ファイルの1つで漏えいしてしまうことです。
Kubernetesクラスター内では、サービスとマシン間の
認証 はサービスアカウントに基づいて行われます。エンドユーザー認証に証明書を使ったり、クラスターの外からサービスアカウントトークンを使ったりすることは、リスクを高めることになるので避けることが重要です。したがって、誤って公開される可能性のあるシークレットや証明書を継続的にスキャンすることが推奨されます。
OWASPは、どのような認証メカニズムを選択した場合でも、人間に第二の認証方法を提供するよう強制することを推奨しています。例えば、クラウド IAM 機能を使用していて、2FA が有効になっていない場合、クラウドや Kubernetes 環境でランタイムに検出できるようにし、検出と対応を迅速化する必要があります。この目的のために、YAML形式のルールセットに従ってランタイムにアラートをトリガーするオープンソースの脅威検出エンジンである
Falco を使用することができます。
- rule: Console Login Without Multi Factor Authentication
desc: Detects a console login without using MFA.
condition: >-
aws.eventName="ConsoleLogin" and not aws.errorCode exists and
jevt.value[/userIdentity/type]!="AssumedRole" and
jevt.value[/responseElements/ConsoleLogin]="Success" and
jevt.value[/additionalEventData/MFAUsed]="No"
output: >-
Detected a console login without MFA (requesting user=%aws.user, requesting
IP=%aws.sourceIP, AWS region=%aws.region)
priority: critical
source: aws_cloudtrail
append: false
exceptions: []
Falcoは、安全でないログインが存在する場所を特定するのに役立ちます。この場合、
MFAなしでAWSコンソール にログインしていることになります。しかし、もし敵が追加の認証を必要とせずにクラウドコンソールにアクセスできたとしたら、その後CloudShell経由でAmazonのElastic Kubernetes Service(EKS)にアクセスできる可能性が高いでしょう。
そのため、クラスターへのアクセスだけでなく、GKE、EKS、AKS、IKSなど、クラスターを動かすマネージドサービスにもMFAを導入することが重要なのです。
しかし、Kubernetesへのアクセスを保護することだけが重要なのではありません。Kubernetesの上で他のツールを使って、例えばイベントの監視などを行う場合、それらも保護しなければなりません。KubeCon 2022で説明したように、
攻撃者は露出したPrometheusインスタンスを悪用し、Kubernetesクラスターを危険にさらす可能性があります。
時代遅れで脆弱なKubernetesコンポーネント
Kubernetesにおける効果的な脆弱性管理は困難です。しかし、
従うべき一連のベストプラクティス は存在します。
Kubernetesの管理者は、最新のCVEデータベースに従い、脆弱性の開示を監視し、該当する場合は関連するパッチを適用する必要があります。そうしないと、Kubernetesクラスターがこれらの既知の脆弱性にさらされ、攻撃者がインフラストラクチャーを完全に制御するためのテクニックを実行しやすくなり、クラスターをデプロイしているクラウドテナントにピボットする可能性があります。
Kubernetesには多数のオープンソースコンポーネントがあり、またプロジェクトのリリースサイクルがあるため、CVE管理は特に困難になっています。
Kubernetesのバージョン1.25 では、
Kubernetesのコンポーネントに影響を与えるCVEのリスト をグループ化して更新する、新しいセキュリティフィードがAlphaにリリースされました。
ここでは、最も有名なものをリストアップします:
これらの脆弱なコンポーネントを検出するには、
kubescape や
kubeclarity など、Kubernetesクラスターをチェックまたはスキャンするツールを使用するか、
Sysdig Secure などの商用プラットフォームに目を向ける必要があります。
今日、発表された脆弱性は、Linuxカーネルを直接対象としており、Kubernetesのコンポーネントそのものではなく、クラスター上で動作するコンテナに影響を与えるものです。それでも、新たに発見される脆弱性には常に目を配り、できるだけ早くリスクを軽減するための計画を立てる必要があります。
まとめ
OWASP Kubernetes Top 10は、セキュリティ実務者、システム管理者、ソフトウェア開発者が、Kubernetesエコシステム周辺のリスクに優先順位をつけることを目的としています。トップ10は、成熟度や複雑さが異なる組織から収集したデータに裏打ちされた、一般的なリスクの優先順位付けを行ったリストです。
私たちは、OWASP Kubernetes Top 10で概説されたギャップに対処するのに役立つ、多数のオープンソースプロジェクトを取り上げました。しかし、これらの無数に存在するツールのデプロイと運用は、効果的に管理するために大量のマンパワーと広範なスキルセットを必要とします。上記の機能すべてに対応する単一のソリューションはありませんが、Sysdig Secureは、ビルド、デリバリー、ランタイムにおいて脅威を検知・防御するための統一されたプラットフォームアプローチを提供します。
イメージ、コンテナレジストリ、またはKubernetesの依存関係内の既知の脆弱性を検出します。
Sysdig Secureプラットフォームに統合されたKubernetesアドミッションコントローラーにより、ユーザーは脆弱なワークロードがランタイムに入るのを受け入れたり、防いだりすることができます。
また、ネットワークポリシーを自動生成することで、ネットワーク関連の脅威の修復を自動化します。
最後に、管理されたPrometheusインスタンスを介して、すべてのクラスタアクティビティーの深い可視性を提供します。


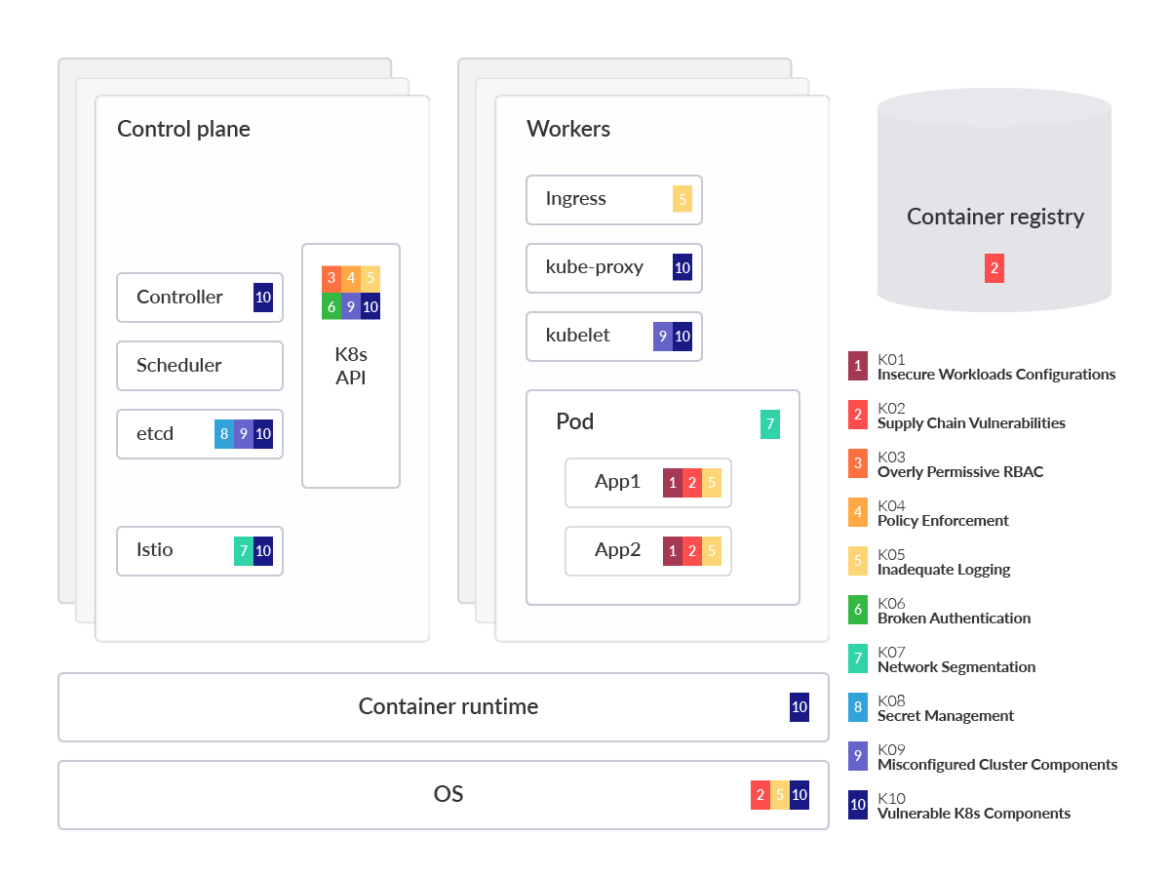 上記のビジュアルでは、理解を助けるために一般化されたKubernetes脅威モデルにマッピングされたOWASP Kubernetesに登場する各リスクによって影響を受けるコンポーネントまたはパーツにスポットライトを当てています。この分析では、各 OWASP リスクに深く入り込み、その脅威が顕著である理由や一般的な緩和策に関する技術的な詳細も提供します。また、リスクを3つのカテゴリーに分類し、可能性の高い順に並べることも有効です。リスクの分類は以下の通りです。
設定の誤り
上記のビジュアルでは、理解を助けるために一般化されたKubernetes脅威モデルにマッピングされたOWASP Kubernetesに登場する各リスクによって影響を受けるコンポーネントまたはパーツにスポットライトを当てています。この分析では、各 OWASP リスクに深く入り込み、その脅威が顕著である理由や一般的な緩和策に関する技術的な詳細も提供します。また、リスクを3つのカテゴリーに分類し、可能性の高い順に並べることも有効です。リスクの分類は以下の通りです。
設定の誤り
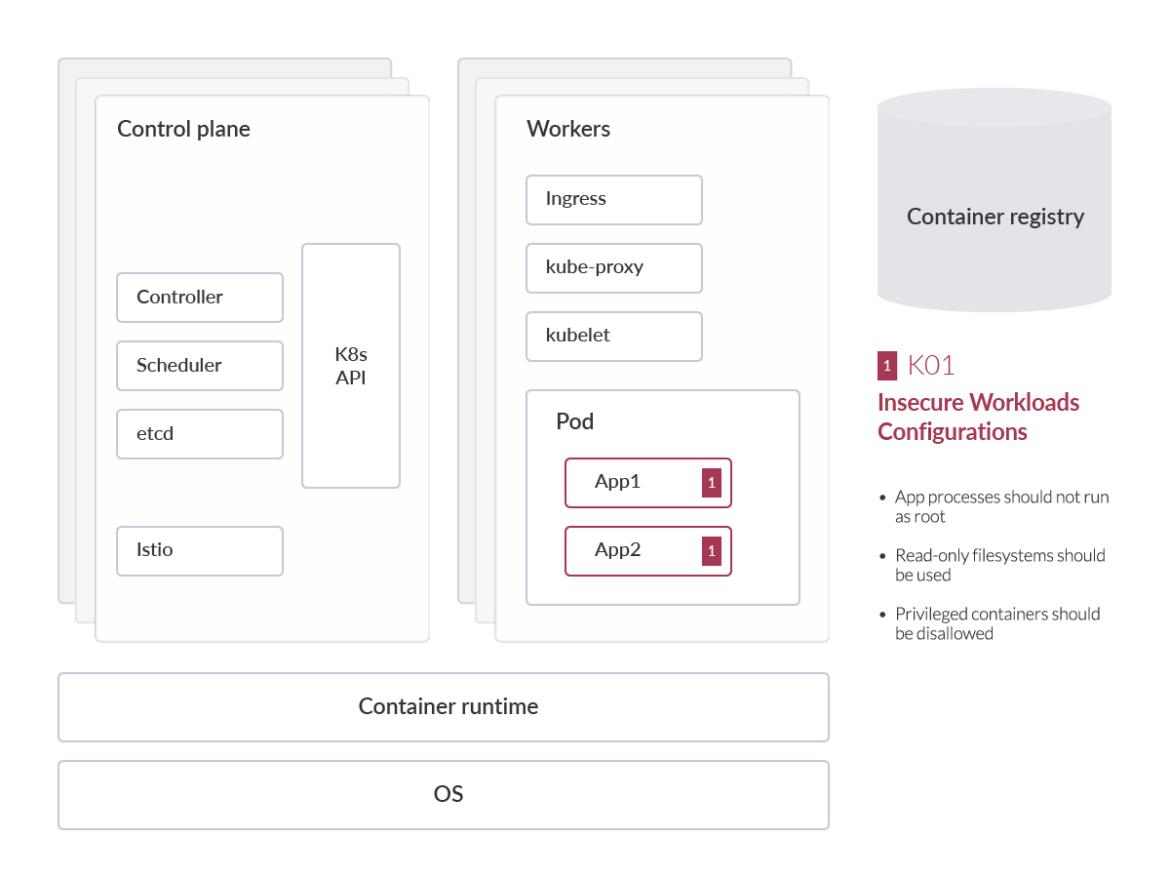 テナントの管理者は、最終的に、ワークロードが安全なイメージを使用していること、パッチが適用され更新されたオペレーティングシステム(OS)上で実行されていること、インフラストラクチャーの設定が継続的に監査され是正されていることを確認する必要があります。クラウドネイティブのワークロードの設定ミスを利用することは、敵対者がお客様の環境にアクセスするための最も一般的な方法の1つです。
テナントの管理者は、最終的に、ワークロードが安全なイメージを使用していること、パッチが適用され更新されたオペレーティングシステム(OS)上で実行されていること、インフラストラクチャーの設定が継続的に監査され是正されていることを確認する必要があります。クラウドネイティブのワークロードの設定ミスを利用することは、敵対者がお客様の環境にアクセスするための最も一般的な方法の1つです。
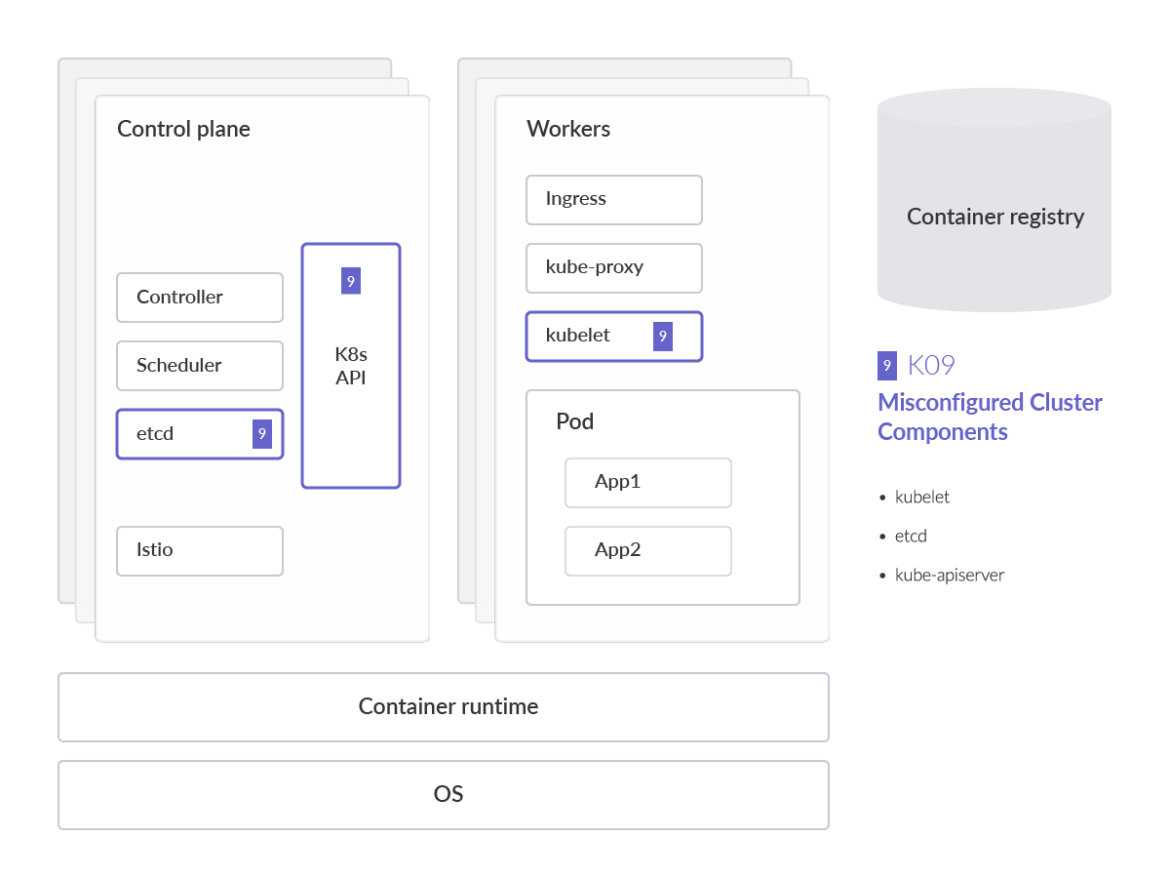 最も危険な設定ミスの1つは、KubeletのAnonymous Authentication設定で、Kubeletへの非認証のリクエストを許可してしまうことです。Kubeletの設定を確認し、以下に説明するフラグがfalseに設定されていることを確認することが強く推奨されます。
ワークロードを監査する場合、アプリケーションをデプロイするさまざまな方法があることを念頭に置くことが重要です。さまざまなクラスターコンポーネントの設定ファイルを使用すると、それらのコンポーネントに対して特定の読み取り/書き込み権限を認可できます。Kubeletの場合、デフォルトでは、他の設定された認証方法で拒否されなかったkubeletのHTTPSエンドポイントへのすべてのリクエストは、匿名リクエストとして扱われ、
最も危険な設定ミスの1つは、KubeletのAnonymous Authentication設定で、Kubeletへの非認証のリクエストを許可してしまうことです。Kubeletの設定を確認し、以下に説明するフラグがfalseに設定されていることを確認することが強く推奨されます。
ワークロードを監査する場合、アプリケーションをデプロイするさまざまな方法があることを念頭に置くことが重要です。さまざまなクラスターコンポーネントの設定ファイルを使用すると、それらのコンポーネントに対して特定の読み取り/書き込み権限を認可できます。Kubeletの場合、デフォルトでは、他の設定された認証方法で拒否されなかったkubeletのHTTPSエンドポイントへのすべてのリクエストは、匿名リクエストとして扱われ、 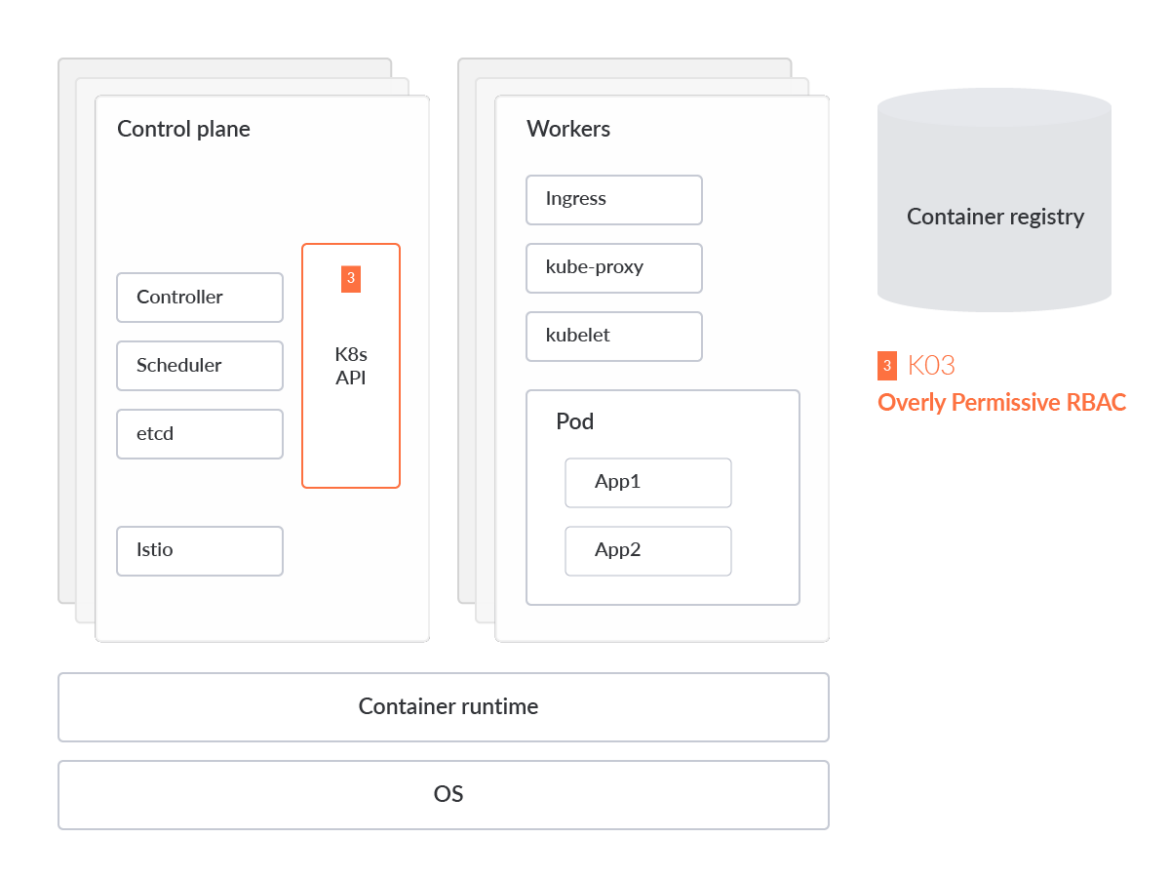 RBACルールの作成は、比較的簡単です。たとえば、Kubernetesクラスターの「default」ネームスペースにあるPodに対して読み取り専用のCRUDアクション(get, watch, listなど)を許可し、それらのPodに対するCreate、Updated、Deleteアクションを禁止する寛容なポリシーを作成するには、次のようになります。
RBACルールの作成は、比較的簡単です。たとえば、Kubernetesクラスターの「default」ネームスペースにあるPodに対して読み取り専用のCRUDアクション(get, watch, listなど)を許可し、それらのPodに対するCreate、Updated、Deleteアクションを禁止する寛容なポリシーを作成するには、次のようになります。
 実行中のクラスターに対してRBACレポートを実行したい場合、以下のようにkubectlコンテキストを提供する必要があります:
実行中のクラスターに対してRBACレポートを実行したい場合、以下のようにkubectlコンテキストを提供する必要があります:
 Kubernetesは、ネットワーク・セグメンテーション・コントロールの正しい構成に対処するためのソリューションを提供しています。ここでは、そのうちの2つを紹介します。
Kubernetesは、ネットワーク・セグメンテーション・コントロールの正しい構成に対処するためのソリューションを提供しています。ここでは、そのうちの2つを紹介します。
 しかし、Kubernetes Audit Logsに限らず、注目すべきログソースは他にもあります。それらは、ホスト固有のOSログ、ネットワークアクティビティログ(KubernetesアドオンのCoreDNSを監視できるDNSなど)、Kubernetesクラウドの基盤としても機能するクラウドプロバイダーなどです。
これらの無数に存在するログソースをすべて一元管理するツールがなければ、侵入された場合に利用するのは難しいでしょう。そこで、PrometheusやGrafana、Falcoのようなツールが役に立ちます。
しかし、Kubernetes Audit Logsに限らず、注目すべきログソースは他にもあります。それらは、ホスト固有のOSログ、ネットワークアクティビティログ(KubernetesアドオンのCoreDNSを監視できるDNSなど)、Kubernetesクラウドの基盤としても機能するクラウドプロバイダーなどです。
これらの無数に存在するログソースをすべて一元管理するツールがなければ、侵入された場合に利用するのは難しいでしょう。そこで、PrometheusやGrafana、Falcoのようなツールが役に立ちます。
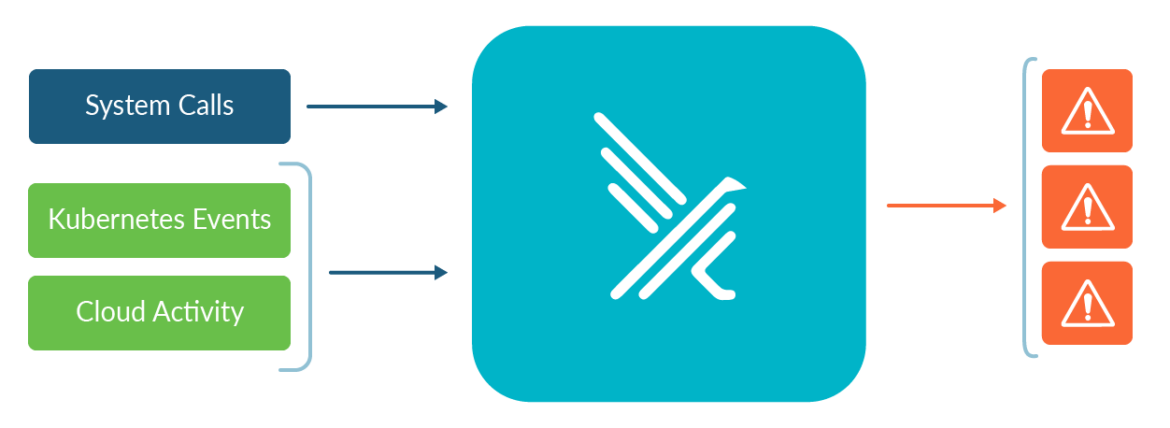 Falcoは、インキュベーションレベルのプロジェクトとしてCNCFに参加した最初のランタイムセキュリティプロジェクトです。Falcoはセキュリティカメラとして機能し、すべてのKubernetes環境において予期せぬ動作、侵入、データの盗難をリアルタイムで検出します。Falco v.0.13では、サポートするイベントソースのリストにKubernetes Audit Eventsを追加しました。これは、既存のシステムコールイベントのサポートに追加されたものです。監査イベントの改良された実装がKubernetes v1.11で導入され、kube-apiserverへのリクエストとレスポンスのログが提供されるようになりました。
ほぼすべてのクラスター管理タスクはAPIサーバーを介して実行されるため、監査ログはクラスターに加えられた変更を効果的に追跡することができます。
その例としては、以下が挙げられます:
Falcoは、インキュベーションレベルのプロジェクトとしてCNCFに参加した最初のランタイムセキュリティプロジェクトです。Falcoはセキュリティカメラとして機能し、すべてのKubernetes環境において予期せぬ動作、侵入、データの盗難をリアルタイムで検出します。Falco v.0.13では、サポートするイベントソースのリストにKubernetes Audit Eventsを追加しました。これは、既存のシステムコールイベントのサポートに追加されたものです。監査イベントの改良された実装がKubernetes v1.11で導入され、kube-apiserverへのリクエストとレスポンスのログが提供されるようになりました。
ほぼすべてのクラスター管理タスクはAPIサーバーを介して実行されるため、監査ログはクラスターに加えられた変更を効果的に追跡することができます。
その例としては、以下が挙げられます:
 設定ミスを集中的に検出、修正、および防止するためのデフォルトの方法がないため、クラスターが危険にさらされる可能性があります。
設定ミスを集中的に検出、修正、および防止するためのデフォルトの方法がないため、クラスターが危険にさらされる可能性があります。
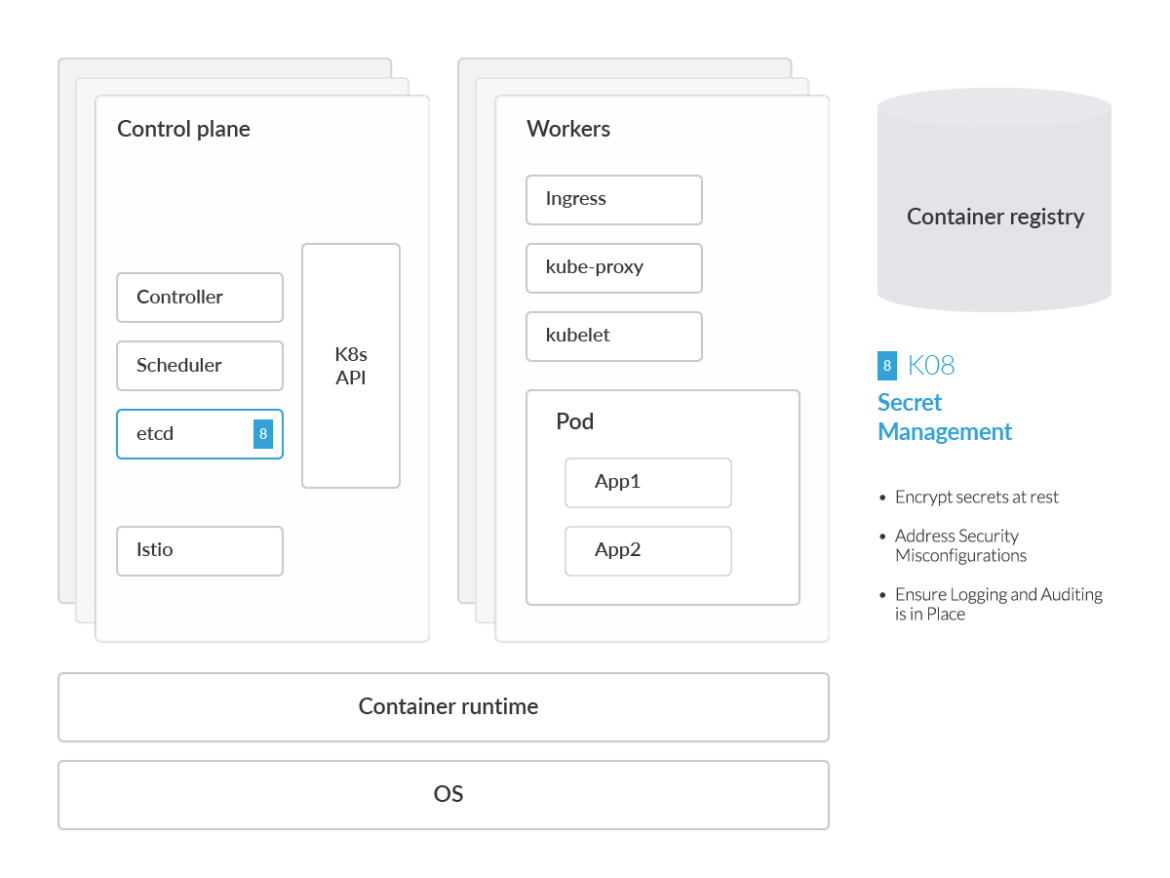 この設計にかかわらず、K8sシークレットはまだ侵害される可能性があります。K8sのネイティブなシークレットメカニズムは本質的に抽象化されたもので、データは依然として前述のetcdデータベースに格納され、ずっと亀の子になっています。そのため、企業にとって重要なのは、広範なシークレット管理戦略の一環として、K8s シークレットにどのように認証情報とキーが保存され、アクセスされるかを評価することです。K8sは、保存された状態におけるデータの暗号化、アクセスコントロール、ロギングなど、その他のセキュリティコントロールも提供します。
この設計にかかわらず、K8sシークレットはまだ侵害される可能性があります。K8sのネイティブなシークレットメカニズムは本質的に抽象化されたもので、データは依然として前述のetcdデータベースに格納され、ずっと亀の子になっています。そのため、企業にとって重要なのは、広範なシークレット管理戦略の一環として、K8s シークレットにどのように認証情報とキーが保存され、アクセスされるかを評価することです。K8sは、保存された状態におけるデータの暗号化、アクセスコントロール、ロギングなど、その他のセキュリティコントロールも提供します。
 SolarWinds社の情報漏えいに見られるように、サプライチェーンへの攻撃は増加傾向にあります。SolarWindsのソフトウェアソリューション「Orion」は、ロシアの脅威グループAPT29(通称Cozy Bear)によって侵害されました。これは長期間にわたって行われたゼロデイ攻撃であり、Orionを環境で稼働させていたSolarWindsのお客様は、この侵害に気づかなかったということです。APT29の敵対者は、このSolarWindsの悪用により、エアギャップがないOrionインスタンスにアクセスできる可能性があります。
SolarWindsは、企業のセキュリティスタック内で侵害されたソリューションの一例に過ぎません。Kubernetesの場合、1つのコンテナ化されたワークロードだけでも、何百ものサードパーティコンポーネントや依存関係に依存することがあり、各段階での起源の信頼性を確保することが極めて困難になっています。これらの課題には、イメージの整合性、イメージの構成、既知のソフトウェアの脆弱性などが含まれますが、これらに限定されるものではありません。
それぞれについて詳しく見ていきましょう。
SolarWinds社の情報漏えいに見られるように、サプライチェーンへの攻撃は増加傾向にあります。SolarWindsのソフトウェアソリューション「Orion」は、ロシアの脅威グループAPT29(通称Cozy Bear)によって侵害されました。これは長期間にわたって行われたゼロデイ攻撃であり、Orionを環境で稼働させていたSolarWindsのお客様は、この侵害に気づかなかったということです。APT29の敵対者は、このSolarWindsの悪用により、エアギャップがないOrionインスタンスにアクセスできる可能性があります。
SolarWindsは、企業のセキュリティスタック内で侵害されたソリューションの一例に過ぎません。Kubernetesの場合、1つのコンテナ化されたワークロードだけでも、何百ものサードパーティコンポーネントや依存関係に依存することがあり、各段階での起源の信頼性を確保することが極めて困難になっています。これらの課題には、イメージの整合性、イメージの構成、既知のソフトウェアの脆弱性などが含まれますが、これらに限定されるものではありません。
それぞれについて詳しく見ていきましょう。
 Sysdig TRTは、上図のようにいくつかのカテゴリに基づいて悪意のあるイメージを収集しました。この分析では、悪意のあるIPアドレスやドメイン、およびシークレットの2つの主要なカテゴリーに焦点を当てました。どちらも、Docker Hubのようなパブリックレジストリで利用可能なイメージをダウンロードしてデプロイする人々にとって脅威となり、その環境を高いリスクにさらすことになります。
イメージスキャンに関する追加のガイダンスは、12のイメージスキャンのベストプラクティスのリサーチから見つけることができます。このアドバイスは、本番環境でコンテナやKubernetesの運用を始めたばかりであっても、現在のDevOpsワークフローにさらなるセキュリティを組み込みたい場合であっても、役に立つでしょう。
Sysdig TRTは、上図のようにいくつかのカテゴリに基づいて悪意のあるイメージを収集しました。この分析では、悪意のあるIPアドレスやドメイン、およびシークレットの2つの主要なカテゴリーに焦点を当てました。どちらも、Docker Hubのようなパブリックレジストリで利用可能なイメージをダウンロードしてデプロイする人々にとって脅威となり、その環境を高いリスクにさらすことになります。
イメージスキャンに関する追加のガイダンスは、12のイメージスキャンのベストプラクティスのリサーチから見つけることができます。このアドバイスは、本番環境でコンテナやKubernetesの運用を始めたばかりであっても、現在のDevOpsワークフローにさらなるセキュリティを組み込みたい場合であっても、役に立つでしょう。
 クラスターに対して認証を行おうとする人がいる場合、主な懸念事項は認証情報の管理です。最もありそうなケースは、偶発的なエラーによって、.kubeconfigなどの設定ファイルの1つで漏えいしてしまうことです。
Kubernetesクラスター内では、サービスとマシン間の認証はサービスアカウントに基づいて行われます。エンドユーザー認証に証明書を使ったり、クラスターの外からサービスアカウントトークンを使ったりすることは、リスクを高めることになるので避けることが重要です。したがって、誤って公開される可能性のあるシークレットや証明書を継続的にスキャンすることが推奨されます。
OWASPは、どのような認証メカニズムを選択した場合でも、人間に第二の認証方法を提供するよう強制することを推奨しています。例えば、クラウド IAM 機能を使用していて、2FA が有効になっていない場合、クラウドや Kubernetes 環境でランタイムに検出できるようにし、検出と対応を迅速化する必要があります。この目的のために、YAML形式のルールセットに従ってランタイムにアラートをトリガーするオープンソースの脅威検出エンジンであるFalcoを使用することができます。
クラスターに対して認証を行おうとする人がいる場合、主な懸念事項は認証情報の管理です。最もありそうなケースは、偶発的なエラーによって、.kubeconfigなどの設定ファイルの1つで漏えいしてしまうことです。
Kubernetesクラスター内では、サービスとマシン間の認証はサービスアカウントに基づいて行われます。エンドユーザー認証に証明書を使ったり、クラスターの外からサービスアカウントトークンを使ったりすることは、リスクを高めることになるので避けることが重要です。したがって、誤って公開される可能性のあるシークレットや証明書を継続的にスキャンすることが推奨されます。
OWASPは、どのような認証メカニズムを選択した場合でも、人間に第二の認証方法を提供するよう強制することを推奨しています。例えば、クラウド IAM 機能を使用していて、2FA が有効になっていない場合、クラウドや Kubernetes 環境でランタイムに検出できるようにし、検出と対応を迅速化する必要があります。この目的のために、YAML形式のルールセットに従ってランタイムにアラートをトリガーするオープンソースの脅威検出エンジンであるFalcoを使用することができます。
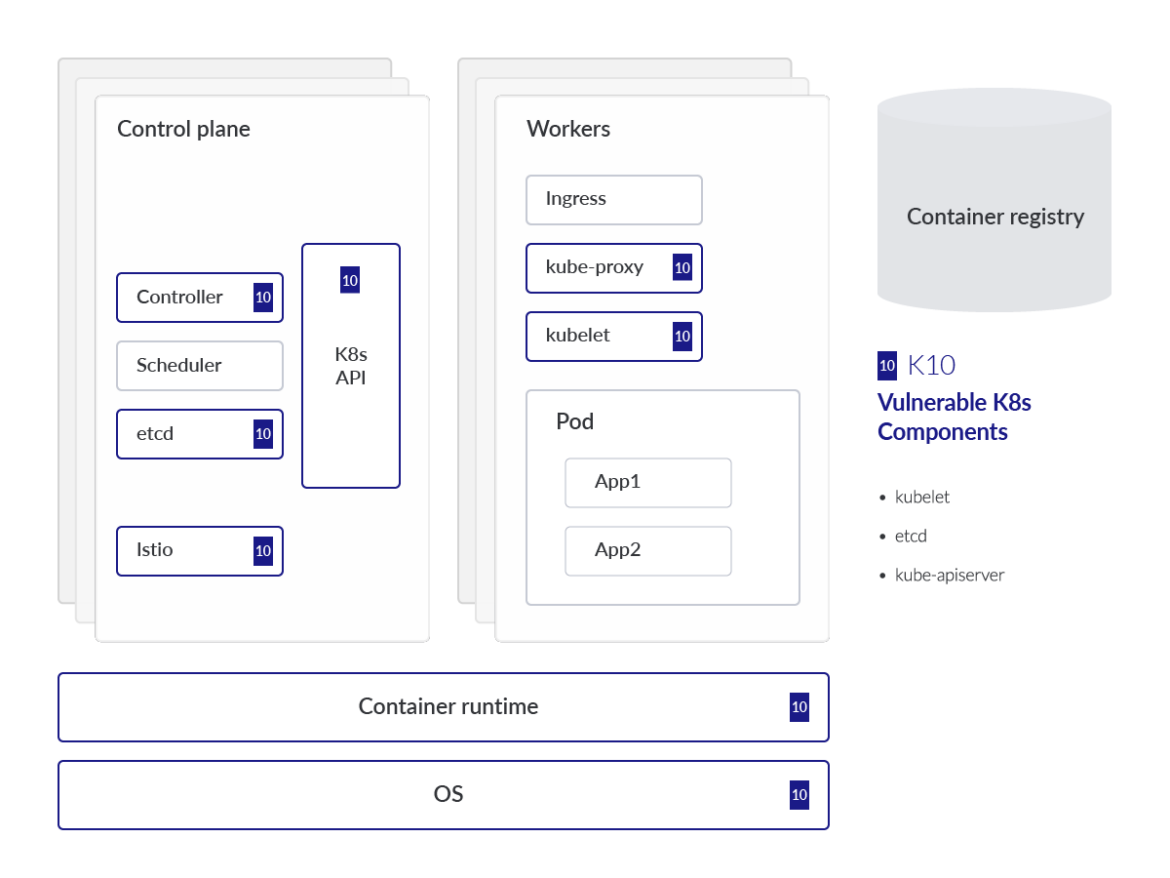 Kubernetesの管理者は、最新のCVEデータベースに従い、脆弱性の開示を監視し、該当する場合は関連するパッチを適用する必要があります。そうしないと、Kubernetesクラスターがこれらの既知の脆弱性にさらされ、攻撃者がインフラストラクチャーを完全に制御するためのテクニックを実行しやすくなり、クラスターをデプロイしているクラウドテナントにピボットする可能性があります。
Kubernetesには多数のオープンソースコンポーネントがあり、またプロジェクトのリリースサイクルがあるため、CVE管理は特に困難になっています。Kubernetesのバージョン1.25では、Kubernetesのコンポーネントに影響を与えるCVEのリストをグループ化して更新する、新しいセキュリティフィードがAlphaにリリースされました。
ここでは、最も有名なものをリストアップします:
Kubernetesの管理者は、最新のCVEデータベースに従い、脆弱性の開示を監視し、該当する場合は関連するパッチを適用する必要があります。そうしないと、Kubernetesクラスターがこれらの既知の脆弱性にさらされ、攻撃者がインフラストラクチャーを完全に制御するためのテクニックを実行しやすくなり、クラスターをデプロイしているクラウドテナントにピボットする可能性があります。
Kubernetesには多数のオープンソースコンポーネントがあり、またプロジェクトのリリースサイクルがあるため、CVE管理は特に困難になっています。Kubernetesのバージョン1.25では、Kubernetesのコンポーネントに影響を与えるCVEのリストをグループ化して更新する、新しいセキュリティフィードがAlphaにリリースされました。
ここでは、最も有名なものをリストアップします: