Kubernetes のノードとは?概要と操作方法を解説
SHARE:

ノードはKubernetes における重要な要素のひとつですが、単独でできることは、そう多くありません。Kubernetesクラスターと連携してこそ、ワークロードを分散できるのです。
その際、たとえば、ノードが停止してもすべてを実行した状態で維持したり、過負荷になっているノードやノードのハードウェアの特性といった複数の特徴を考慮したりできます。
この記事では初心者の方へ向けて、Kubernetesにおけるノードの概要として機能や利用できる管理オプションなどを説明したうえで、基本的な操作方法、新しいノードの追加方法などについても取り上げます。
関 連 記 事
| Kubernetesとは? | Kubernetesセキュリティ の基礎とベストプラクティス | Kubernetesアーキテクチャの 設計方法 |
| AWSのEKS (Elastic Kubernetes Service) | Kubernetesの クラスターとは? | Kubernetes のノードとは? |
| KubernetesのPodとは? | KubernetesのHelmとは? | クラウドセキュリティと ランタイムインサイト |
Kubernetesノードとは?
Kubernetes ノードとは、それぞれが相互接続され、Kubernetes クラスターとして連携するマシン(物理マシンまたは仮想マシン)のことです。各 Kubernetes ワークロードのすべてとコントロールプレーンコンポーネントが格納されています。
概念を説明すると、ノードは Pod やそのコンテナなど、Kubernetes のワークロードが実行される実際の環境を抽象化したものです。Kubernetes のノードは物理マシン(ハードウェアデバイス、サーバー、コンピュータ、エッジにある組み込みデバイスなど)の場合もあれば、コンピュータまたはクラウド上の仮想マシンの場合もあります。

Kubernetes ノードのコンポーネント
Kubernetes の各クラスターは、Kubernetes ワーカーノードと呼ばれるホストで形成されます。これらは 1 つまたは複数の専用ノードで実行されるコントロールプレーンのコンポーネントによって調整されます。
こうした観点から見ると、Kubernetes のノードには 2 つの主要な役割があります:
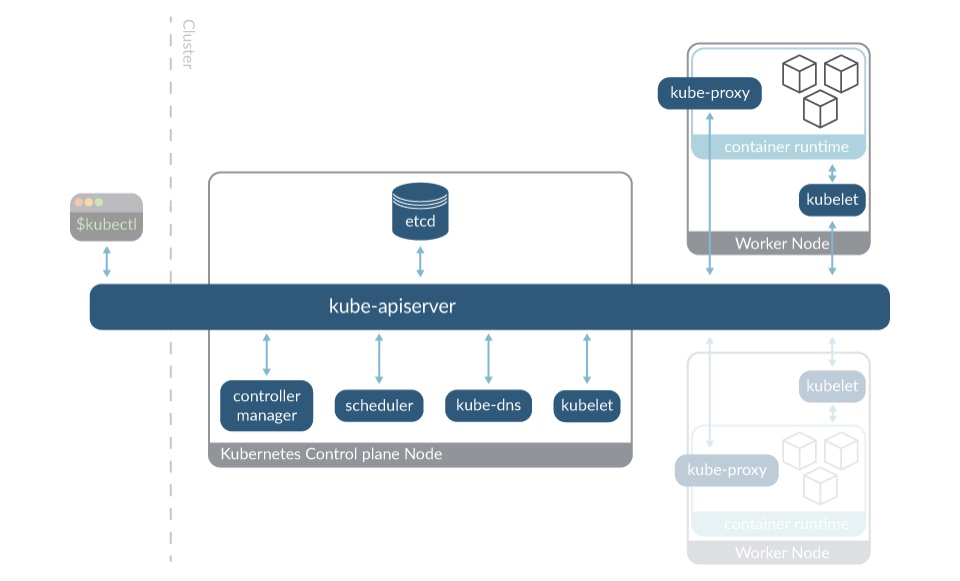
- ワーカーノード: 主な目的は、ワークロード、つまり、ユーザーのアプリケーションの実行です。また、以下のような、Kubernetes のコントロールプレーンコンポーネントの一部も実行します:
- kubelet: ワークロードが想定どおりに実行されるようにし、新しいノードを API サーバーに登録する Kubernetes のエージェント。 kubelet は各ノードで実行されます。
- kube-proxy: クラスターコンポーネント間でのネットワーク通信のために、ノード上でネットワークルールを保持するネットワークプロキシ。kube-proxy も各ノードで実行されます。
- コントロールプレーンノード: 以下に挙げるコントロールプレーンの大半のコンポーネントが実行される専用のノードです:
- kube-apiserver: Kubernetes API サーバーの主要な実装。クラスターのコンポーネントとノード間で通信するための主要なメカニズムです。
- etcd: Kubernetes のバッキングストア。一貫性と可用性の高いキーと値のストアで、クラスターの運用データのすべてが保管されます。
- kube-controller-manager: ノードコントローラ、ジョブコントローラ、エンドポイントコントローラなど、コントローラプロセスを実行します。
- kube-scheduler: 新しく作成された Pod を検出し、その Pod が実行されるノードを選択します。
- kube-dns: Pod とサービスの DNS 名の定義と、コンテナの IP アドレスに対する DNS 名前解決をサポートします。
- kubelet(ワーカーノードとコントロールプレーンの両方で稼働): ワークロードが想定どおりに実行され、新しいノードを apiserver に登録する Kubernetes のエージェント。kubelet は各ノードで実行されます。
コントロールプレーンノードは Kubernetes v1.24 [stable] まではマスターノードと呼ばれていました。このマスターという用語はレガシーになっており、コントロールプレーンという用語に置き換えられています。このレガシー名は kubeadm など一部のプロビジョニングツールでは引き続き使用されている場合があります。
環境の要件に応じて各ノードのロールを定義するのはクラスター管理者の役割です。使用するロールを増やすことによって、特定のノードを差別化できます。詳細については、推奨されるプラクティスについてのセクションを参照してください。
また、Sysdig ブログの各記事では、コントロールプレーンの各種コンポーネントの監視方法について詳しく取り上げています:
- How to monitor Kubernetes apiserver(Kubernetes の apiserver の監視方法)
- How to monitor kubelet(kubelet の監視方法)
- How to monitor etcd(etcd の監視方法)
- How to monitor controller-manager(controller-manager の監視方法)
- How to monitor kube-proxy(kube-proxy の監視方法)
- How to monitor core-dns(core-dns の監視方法)
Kubernetes のノードの操作方法
ノードとクラスターを構成したら、それらを運用しなければなりません。そのために使用するのが kubectl です。kubectl は Kubernetes に用意されたコマンドラインツールであり、Kubernetes API 経由で Kubernetes クラスターのコントロールプレーンと通信します。よく使用する kubectl コマンドを以下に説明します:
ノードを取得する

ノードが嬉しそうに見えるのは、kubectl セレクタによって選択されているためです。
以下のコマンドを実行すると、デフォルトのネームスペースにあるすべてのノードを一覧表示できます。
kubectl get nodes [-o wide] [--all-namespaces] [--selector='[!]<label>[=<value>]']Code language: CSS (css)- -o wide: 内部 IP や外部 IP といった追加情報を表示します。
- –All-namespaces:: ネームスペースごとに各ノードを表示します。
- [–selector=‘[!]<label>[=<value>]’]: 指定したラベルと値に一致するノードを一覧表示します。! を指定した場合はラベルと値に一致しないノードを一覧表示します。
> kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 Ready control-plane 11d v1.24.0
node02 Ready <none> 11d v1.24.0
node03 Ready <none> 11d v1.24.0
> kubectl get nodes -o wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node01 Ready control-plane 11d v1.24.0 172.30.1.2 <none> Ubuntu 20.04.3 LTS 5.4.0-88-generic containerd://1.5.9
node02 Ready worker 11d v1.24.0 172.30.2.2 <none> Ubuntu 20.04.3 LTS 5.4.0-88-generic containerd://1.5.9
node03 Ready worker 11d v1.24.0 172.30.3.2 <none> Ubuntu 20.04.3 LTS 5.4.0-88-generic containerd://1.5.9
> kubectl get node --selector='node-role.kubernetes.io/worker'
NAME STATUS ROLES AGE VERSION
node02 Ready worker 11d v1.24.0
node03 Ready worker 11d v1.24.0Code language: HTML, XML (xml)ノードのステータスを確認する
ノードの詳細情報を出力します:
kubectl describe node [<node-name> | -l <label>[=<value>]Code language: HTML, XML (xml)例:
> kubectl describe node node01
Name: node01
Roles: control-plane
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=node01
kubernetes.io/os=linux
node-role.kubernetes.io/control-plane=
node.kubernetes.io/exclude-from-external-load-balancers=
Annotations: flannel.alpha.coreos.com/backend-data: {"VNI":1,"VtepMAC":"f2:6e:b4:e0:b1:1b"}
flannel.alpha.coreos.com/backend-type: vxlan
flannel.alpha.coreos.com/kube-subnet-manager: true
flannel.alpha.coreos.com/public-ip: 172.30.1.2
kubeadm.alpha.kubernetes.io/cri-socket: unix:///var/run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl: 0
projectcalico.org/IPv4Address: 172.30.1.2/24
projectcalico.org/IPv4IPIPTunnelAddr: 192.168.0.1
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Fri, 12 Aug 2022 15:08:41 +0000
Taints: <none>
Unschedulable: false
<...>Code language: PHP (php)ノードにインタラクティブなデバッグセッションを作成する
kubectl debug node/<node-name> -it --image=<image>Code language: HTML, XML (xml)ノードのリソース使用状況を表示する
すべてのノードまたは特定のノードの CPU/メモリの使用状況を表示します:
kubectl top node [<node-name> | -l <label>=[<value>]]Code language: HTML, XML (xml)
ノードをスケジュール不可とマークします。これは Kubernetes の用語で cordon と呼ばれ、新しい Pod を当該ノードにスケジュールしないことを意味します:
kubectl cordon <node-name>Code language: HTML, XML (xml)例:
> kubectl cordon node01
node/node01 cordoned
> kubectl get nodes
NAME STATUS ROLES AGE VERSION
node01 Ready,SchedulingDisabled control-plane 11d v1.24.0
node02 Ready worker 11d v1.24.0
node03 Ready worker 11d v1.24.0Code language: JavaScript (javascript)ノードをスケジュール可とマークする
新しい Pod をノードに再スケジュールすることを許可します:
kubectl uncordon <node-name>Code language: HTML, XML (xml)例:
> kubectl uncordon node01
node/node01 uncordonedノードをドレインする
ノードを cordon し、実行中のすべての Pod をそのノードから削除します:
kubectl drain <node-name> [--force] [--grace-period <sec>] [--ignore-daemonsets]Code language: CSS (css)- –Force:: コントローラを宣言していない Pod があっても強制的に処理します。
- –grace-period <sec>: 各 Pod が終了するまでの期間(秒数)を指定します。
- –ignore-daemonsets: Pod を削除する際に、DaemonSet の Pod を無視します。
例:
> kubectl drain node01 --ignore-daemonsets
node/node01 cordoned
WARNING: ignoring DaemonSet-managed Pods: kube-system/canal-ss6xh, kube-system/kube-proxy-g4smn
evicting pod kube-system/coredns-7f6d6547b-w2855
evicting pod default/example-pod-59d75644df-m65p2
pod/example-pod-59d75644df-m65p2 evicted
pod/coredns-7f6d6547b-w2855 evicted
node/node01 drainedCode language: JavaScript (javascript)Kubernetes ノードの追加方法
新しい Kubernetes ノードの作成方法は、使用しているディストリビューションと実際のノードがホストされている場所によって常に異なります。とはいえ、大半のシナリオで、直感的にわかりやすい新しい Kubernetes ノードの追加方法を以下に示します:
- コンピュータまたはサーバー(物理または仮想マシン)を設定します。
- ノードに kubelet をインストールします。
- クラスターにノードを追加します。–register-node フラグおよび、コントロールプレーンを検出してそこに追加するために必要な情報を指定すると、kubelet によりコントロールプレーンにノードを自己登録できます。または、kubeadm CLI ツールを使用してノードをクラスターに手動で追加することもできます。
Amazon Elastic Kubernetes Service(EKS)
各クラウドサービスでは、新しいノードを追加するプロセスをシンプルにする独自のソリューションを提供しています。たとえば Amazon Elastic Kubernetes Service(EKS)では eksctl CLI ツールを実装し、クラスターではなくサブクラスターをグループ化したノードグループという概念に基づいて、クラスター自体をエスカレーションします:
1. 新しいノードグループを作成します:
eksctl create nodegroup --cluster=<clusterName> [--name=<nodegroupName>]Code language: HTML, XML (xml)2. ノードグループを拡張します:
eksctl scale nodegroup --cluster=<clusterName> --nodes=<desiredCount> --name=<nodegroupName> [--nodes-min=<minSize>] [--nodes-max=<maxSize>]Code language: HTML, XML (xml)この場合、EKS は Amazon クラウド内に自動でノードを作成し、—cluster フラグで指定されたクラスターに追加します。クラスターのエスカレーション方法については、Amazon EKS と eksctl の正式な資料を参照してください。
MicroK8s
同様に、Canonical の軽量の Kubernetes ディストリビューションである MicroK8s を使用している場合は、以下のコマンドを実行して自動で新しいノードを作成し、実行中のクラスターに追加できます:
microk8s add-nodeこのコマンドを実行すると、MicroK8s クラスターをホストしているマシンにノードを新たに構成して当該クラスターに追加します。
Pod のスケジュール
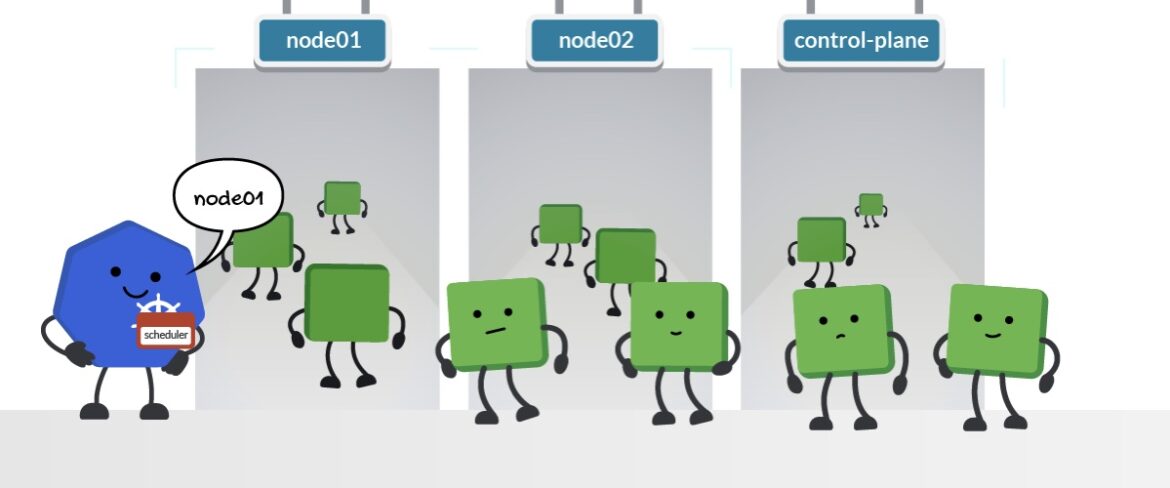
Kubernetes には、Pod をクラスターのノードに割り当てる方法を決定するメカニズムが用意されています:
- ノードのラベルと nodeSelector: 独自のタグまたは Kubernetes のデフォルトのタグを使用してノードにラベルを付け、nodeSelector オプションを使用して、そのラベルを付けたノードに Pod をスケジュールします。
- ノード名と nodeName セレクタ: ノードに名前を付け、Pod 仕様でnodeName オプションを定義し、その名前を付けたノードに Pod をスケジュールします。
- Node アフィニティとアンチアフィニティ: nodeAffinity で requiredDuringSchedulingIgnoredDuringExecution オプションや preferredDuringSchedulingIgnoredDuringExecution オプションを使用して、ノードに対してさらに複雑かつ詳細な制約を定義し、それらのノードでの Pod のスケジュール方法を指定します。
- Taint と Toleration: Taint を定義して、ノードに Pod がスケジュールされないように Pod を拒否する方法を宣言します。Pod 仕様に Toleration を指定して、特定の Pod がノードにスケジュールされることを許可します。
ノードに対する Pod のスケジュール処理を行うのが、Kubernetes のスケジューラです。
Kubernetes のノード操作に関するベストプラクティス

専用のノードでコントロールプレーンのコンポーネントを実行する
コントロールプレーンは、クラスターを管理します。その他のプロセスと同様に、コントロールプレーンのコンポーネントを実行するにはリソースが必要です。コンポーネントが実行されないという状況は回避する必要があります。
コントロールプレーンがなければクラスターの動作を予測できず、障害が発生した場合にワークロードを管理できなくなります。コントロールプレーンのコンポーネントとワークロードをローカルの学習環境などと同じノードに配置しても構いませんが、これはベストプラクティスではありません。
コントロールプレーン専用のノードを 1 つ以上用意すれば可用性が高くなり、障害が発生してもその他のワークロードによるリソースの枯渇を回避できます。
複雑な環境やパフォーマンスを優先する場合はこの方針を継続し、コントロールプレーンのすべてのコンポーネントを同じノードに配置しないようにします。たとえば、非常に大規模なクラスターの場合は、etcd を分離することをお勧めします。
物理ノードと仮想ノードを戦略的に使用する

ノードの構成時には、「物理ノードと仮想ノードのどちらにすべきか?」という点を考えなければなりません。当初は、ベアメタルサーバーを使っていれば間違いはなかったのですが、仮想マシンの最適化が進むにつれてその使用が一般的に普及するようになり、ベアメタルサーバーを利用する以上のメリットを得られるようになっています。
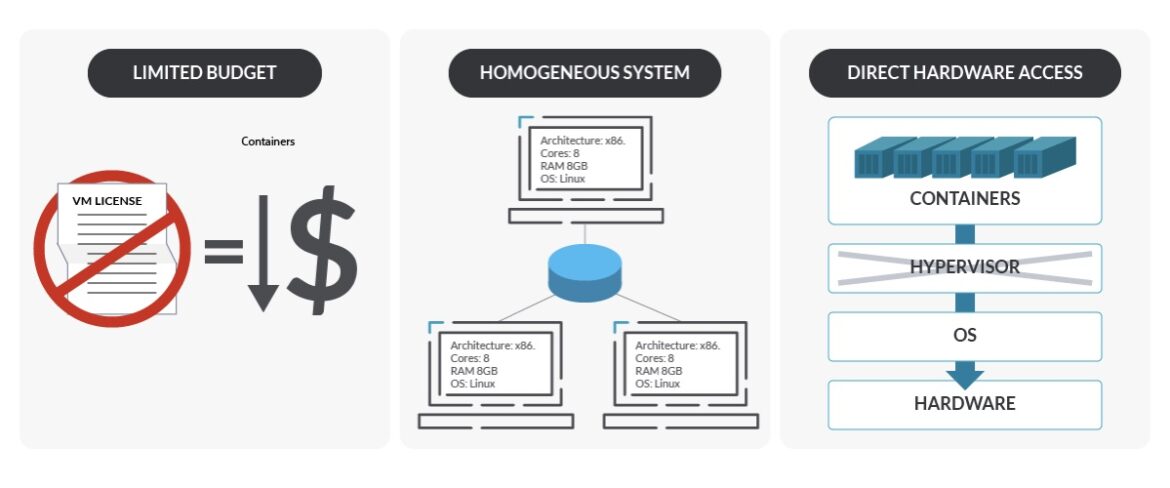
以下のような場合には、物理マシンを選択します:
- 予算が限られている。VM は仮想化ソフトウェア、追加の OS(物理マシン上の VM 用)、ライセンスの点でコストが高くなる場合があります。
- 大規模なデータセンターの管理運営を、一貫性のある環境で行う必要がある。
- ワークロードを詳細に制御する必要がある。ベアメタルでは、Pod レベルに至るまで、より細密な制御が可能です。
- 仮想化層をはさまずに、基盤のハードウェアにアクセスする必要がある。仮想化層がないことで、以下がシンプルになる可能性があります。
- トラブルシューティング。ベアメタルの監視は難しい場合がありますが、階層を追加するとさらに難しくなる可能性があります。ただし、監視機能の進化により、このギャップは解消されつつあります。
- ネットワークなどの構成、あるいはストレージの読み書きといったハードウェアにおける直接のプロセスの実行。
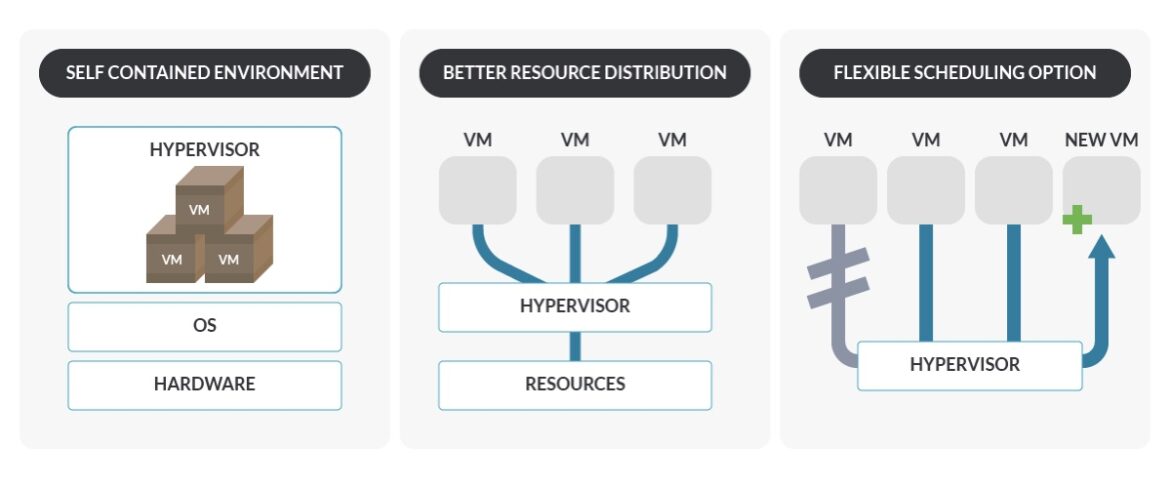
以下の場合には、仮想化を選択します:
- 移植可能で独立した環境が必要である。ハイパーバイザは VM 周辺にブラックボックスを作り、実行されるハードウェアから VM を独立させます。
- 新しい/更新されたパッケージ、ドライバ、またはライブラリの重大な脆弱性をテストする必要がある。問題が発生した場合、VM ではスナップショットを使用してマシンの状態を元に戻すことができます。この機能はベアメタル OS も備えていますが、より操作が困難となります。
- 開発環境を簡単かつ速やかに構成する必要がある。VM はベアメタルよりも構築が簡単です。
- さまざまな機能を異機種環境に統合する必要がある。
- ノードを簡単にプロビジョニングする必要がある。ハイパーバイザでは新しいノードを簡単に作成でき、各種サイズを設定し、デフォルト構成のための VM テンプレート(事前インストールされた LinuxOS)も使用できます。
- リソースの割り当てを改善する必要がある。VM では複数のサービスでリソースを簡単に共有できます。少数のサーバーで大量のワークロードを処理する場合に大きなメリットを得られます。ハイパーバイザでは通常、環境全体のリソースを適切に管理できます。
- より柔軟な拡張オプションが必要である。ハイパーバイザを使用すると異なる物理ノード間で VM を移動し、障害が発生した場合は別の VM のホストを自動的に素早く起動できます。
|
すべての VM を 1 つのホストノードに配置するのは危険であることに留意してください。ベアメタルアーキテクチャで稼働するノードが停止しても大きな問題には至らないかもしれませんが、VM 上のノードが停止するとシステム全体が停止します。 |
ノードの設定を検証する
システムのノードすべての準備ができたら、適切な検証を実行してノードが正しく設定されているかどうか確認することをお勧めします。ノードの適合テストが実施されるのは次のような場合です。

ノードの適合テストはコンテナ型のテストフレームワークです。このテストでは、ノードが Kubernetes の最小要件に適合しているかどうかを検証してから、ノードを Kubernetes クラスターに追加します。
ノードの自動スケーリングを使用する(利用できる場合)
クラウドベースの Kubernetes サービスの大半は拡張機能を備えています。この機能を使用すれば、全体的なワークロードの需要に応じてノードの作成と削除を自動的に行えます。自動スケーリングは、利用するノードの数を適正に保つのに便利な手段です。また、不要なノードにかかる無駄な費用を削減できます。
オンプレミスや自己管理型のインフラ環境で稼働する Kubernetes では、自動スケーリングを構築することはできても、すぐに利用することができません。
ノードの攻撃対象領域を減らす
一般的に、各ノードで実行するソフトウェアは少ないにこしたことはありません。ノードをプロビジョニングする際には、不要なプロセスを実行してセキュリティリスクやリソースの浪費を招かないよう、フル機能を実装した Linux ではなく軽量のディストリビューションの使用を検討してください。
Kubernetes のノードになれるものとは
皆さんは「これで Kubernetes のノードと、クラスターでのノードの役割を理解できた」と考えているかもしれません。それでは、ここで考え方を少し変えてみましょう。ノードは機能が充実したコンピュータでなくても構わないと考えたことはあるでしょうか。
VM、パーソナルコンピュータ、Raspberry、冷蔵庫、はては Windows マシンまで、どれも Kubernetes のノードにすることができます。CPU、メモリ、最小のオペレーティングシステムを備え、他のデバイスと少なくとも一方向の通信ができるのであれば、それはノードになりえるのです。

たとえば、Raspberry Pi を使用して Kubernetes クラスターを設定 し、MicroK8s を実行することがかなり一般的になっています。
MicroK8s、2 台の Raspberry Pi、16.04 LTS Ubuntu デスクトップ、Ubuntu Server イメージを書き込む microSD カードを Pi ごとに用意すれば、完全な Kubernetes クラスターを設定できます。正規の Ubuntu チュートリアルには豊富な教材や公式ドキュメントが揃っているので参照してください。
また、F-16 などの軍用機にも Kubernetes が組み込まれていることが話題になっています。
Kubernetes の意外な使用事例としては、エッジデバイスがあります。エッジデバイスとは、センサや工場機器などが搭載された小型のコンピュータです。このような事例では、Kubernetes をソフトウェアの配布、デバイスの構成、システム全体の信頼性の確保に役立てています。
まとめ
Kubernetes ノードの機能、管理オプション、新規ノードの追加方法について取り上げました。
ノード単独でできることは、そう多くありません。Kubernetes クラスターと連携してこそ、ノードでワークロードを分散できるのです。
ワークロードを実行する環境で、Kubernetes のノードは非常に重要な役割を果たします。