

本文の内容は、2023年2月15日にEMANUELA ZACCONE が投稿したブログ(https://sysdig.com/blog/cloud-monitoring-journey)を元に日本語に翻訳・再構成した内容となっております。
監視はゴールではなく、旅路です。プロジェクトの成熟度に応じて、クラウド監視における旅路の6つのステップのいずれかに分類されます。これらすべてのベストプラクティスを見つけ、企業がそれぞれから何を得ることができるかを検証します。
古典的な仮想マシンから大規模なKubernetesクラスター、さらにはサーバーレスアーキテクチャーまで、企業はオンラインサービスを提供する主流の方法としてクラウドを採用してきました。ビジネス戦略の一環として、クラウド監視はこれらの企業がサービス品質(QoS)を確保し、問題を解決し、最終的にはコスト効率を得るために役立っています。
しかし、クラウド監視を実施する企業の数は多いため、そのアプローチも多岐にわたります。クラウド監視がどこまで深化するかは、各社が提供するサービスと技術部門の経験・成熟度の双方によって決まっていきます。
本記事では、監視の成熟度について6つのステップを説明します。
- 🧑🚒 ファイアファイター::監視を全く行わず、問題に対して事後的に対応する。
- 🛎️ 受付係:アプリケーションのブラックボックス監視。
- 🌱 庭師:CPU、メモリ、ディスクなどのリソースを監視する。
- 🩺 医者:サードパーティアプリケーションの内部を監視し、問題を調整・予測する。
- 🧑🔬 エンジニア: ビジネスや社内アプリケーションで独自のメトリクスを作成する。
- 💲 ストラテジスト:メトリクスを財務や法務などの他部門で使用する。
ファイアファイターフェーズ
クラウドに移りましょうというとき、多くの企業はクラウドの監視を全くしない状態から始めます。これは、明確な監視戦略がなく、可用性、ダウンタイム、サービス品質におけるインシデントがエンジニアリング部門の行動の主な原動力となる最初の段階です。
この段階では、企業は新しい技術を採用し、経験を積み、次のステップとクラウド監視に使用するツールを計画する機会を得ます。
このフェーズのベストプラクティスをいくつか紹介します:

- ダウンタイムを最小限に抑えるために、しっかりとしたバックアップとディザスタリカバリー戦略に投資する。
- 新しいバージョンやアプリケーションを本番環境に近い状態でテストするためのステージング環境を用意し、サービスの中断の可能性を最小にする。
- テストを自動化し、テストカバレッジと統合テストを増やして、新リリースでの誤動作やエラーを防止する。
しかし、この最初の段階の主な欠点は、障害やダウンタイムが自動的にエンジニアリング部門に報告されないことです。営業時間内であれば簡単に発見できますが、週末や夜間に誰も報告しない場合、長期間使用できない可能性があります。
また、サービスの低下や障害を迅速に検知できないため、カナリアデプロイやレッドブルーデプロイといった戦略をとることができません。このため、開発サイクルが長くなり、よりアジャイルで迅速なアプローチよりも保守的な戦略を強いられることになり得ます。
受付係フェーズ
クラウド監視の最初のフェーズで、何らかの監視が行われている状態です。この段階での監視はブラックボックス的なアプローチで、インフラストラクチャー、サービス、アプリケーションを外側から見ます。ビジネスの可用性に直接影響するダウンタイム、障害、問題に対して警告することに重点が置かれています。
この段階でのベストプラクティスには、仮想マシンの可用性、オープンポート、応答時間、接続エラーなどを追跡するための監視サービスの設定が含まれます。この情報をもとに、エンジニアリング部門は問題が発生した際にアラートを受け取ることができるようになりました。また、エンジニアリング・チームは、ゴールデン・シグナルのフレームワークを使用して、導入するクラウド監視システムで何を確認すべきかを定義しようとします。
同社は、IT部門を整理し、DevOpsの思想に近いものに進化させることができるようになります。チームはオンコールローテーションサイクルを調整することができ、たとえそれがまだリアクティブな戦略であったとしても、会社が提供するサービスの可用性と信頼性は大きく改善されます。
新しいクラウド監視により、開発エンジニアとサイト信頼性エンジニア(SRE)は、サービス全体の可用性に影響を与えることなく、新機能をテストするためのカナリアリリースで、より速い開発サイクルを実行できるようになります。これは、より速く、より安全に新機能を提供できるようになった会社全体へのビジネスインパクトとなります。
植物の場合、リソースとは光、水、土であり、クラウドデプロイの場合、リソースとは通常、CPU、メモリ、ディスク、ネットワークです。

この段階では、アプリケーションやサービスはまだブラックボックスと見なされているが、アウトプットだけでなく、それらが受け取るインプットも監視することで、より早く、より良いトラブルシューティングを行うことができます。また、ディスクの容量不足、マシンの低容量、サービスの適正サイズなど、潜在する問題を予測・予防することもできます。
このフェーズでは、クラウドアーキテクトやソリューションアーキテクトの役割が登場し、新しいクラウドモニタリング機能がブロックしない2つのベストプラクティスがあります。1つはキャパシティ・プランニングで、ユーザー数、使用量、その他のパラメータに基づいて、将来必要となるキャパシティを正しく定義し、予見するために使用されます。
このステージで利用できる2つ目の新しい手法は、リソースの動的サイジングです。これは、使用状況に応じてインスタンスを作成または破棄する仮想マシン群から、Kubernetesクラスターにおける水平ポッドオートスケーリング(HPA)戦略まで、さまざまなレイヤーのクラウド技術で利用可能です。
アプリケーションとサービスはもはやブラックボックスではなく、エンジニアリングチームは、医師がX線を使って体の内部を見るのと同じように、それらからカスタムメトリクスを収集し始めるのです。
 アプリケーションのカスタムメトリクスは、SREチームの専門性を高め、データベース、キャッシュ、ウェブサーバなどのサービスをチューニングして、パフォーマンスを向上させ、障害を防ぐことができるようになります。
アプリケーションのカスタムメトリクスは、SREチームの専門性を高め、データベース、キャッシュ、ウェブサーバなどのサービスをチューニングして、パフォーマンスを向上させ、障害を防ぐことができるようになります。
サービスのサチュレーション状態を推測しようとしていたクラウド監視ソリューションが、サービスの内部を見て、キャッシュやバッファのヒット率、利用可能な接続、その他の内部メトリクスをチェックし、問題がお客様とビジネスに影響を与える前にSREに警告することができるようになります。
このフェーズのエンジニアは、カスタムメトリクスで社内アプリケーションを計測し、DIYメトリクスの利点を生かして、自分たちのアプリケーションの改良、調整、トラブルシューティングを行うことができます。
 環境とアプリケーションの健康状態を一目で把握し、根本原因をよりよく特定し、システム全体の効率を監視し、行動を起こすことができるようになります。そのために、PrometheusやOpenTelemetryなど、さまざまなテクノロジーでコードをインスツルメンテーションするためのさまざまなライブラリを活用します。
環境とアプリケーションの健康状態を一目で把握し、根本原因をよりよく特定し、システム全体の効率を監視し、行動を起こすことができるようになります。そのために、PrometheusやOpenTelemetryなど、さまざまなテクノロジーでコードをインスツルメンテーションするためのさまざまなライブラリを活用します。
このフェーズで採用すべきベストプラクティスは、新しい機能やモジュールの設計の一部として、メトリクスをインストルメント化することです。アプリケーションが公開するメトリクスを定義する際に、アプリケーションの保守とトラブルシューティングを行うSREが関与します。このようにして、設計チームと本番環境チームが、企業の観測可能性戦略の一部となるのです。
ストラテジストフェーズでは、技術インフラストラクチャーは、すべての組織レベルに影響を与えるFinOps効率化マシンに変換されます。

FinOpsチームは、より良い監視がいかにコストの最適化をもたらすかを知ることができます。インフラストラクチャーとアプリケーションの可視性が不十分な状態では、情報に基づいた意思決定を行うことができません。長期的に見ると、改善できる分野、問題を発生させるプロセス、接続されたアプリケーションの効率性などが本当のところわからないということになります。
法務部門の側でも、サービスレベルアグリーメントを作成し、その達成度を把握することで、お客様の満足度にも影響を与えることができます。SLA契約は、お客様やユーザーに透明性を与える成熟した監視システムがあって初めて可能になります。
この最終ステージでわかるように、財務や法務など、より多くの部門が監視を積極的に利用し、活用するようになります。これは、彼らが企業の監視戦略に関与し、何をどのように監視するかという決定に参加する必要があることを意味します。
よりディープな監視と適切なツールに支えられた戦略的アプローチにより、コストの最適化やメトリクスを実用的なインサイトに変換して効率を向上させることができるなど、企業全体にとってのメリットを実現することができます。
Cost Advisorを使えば、Kubernetesのリソースの無駄を最大40%削減することができます。
また、アウトオブボックスのKubernetesダッシュボードを利用すれば、数回のクリックで十分に活用されていないリソースを発見することができます。
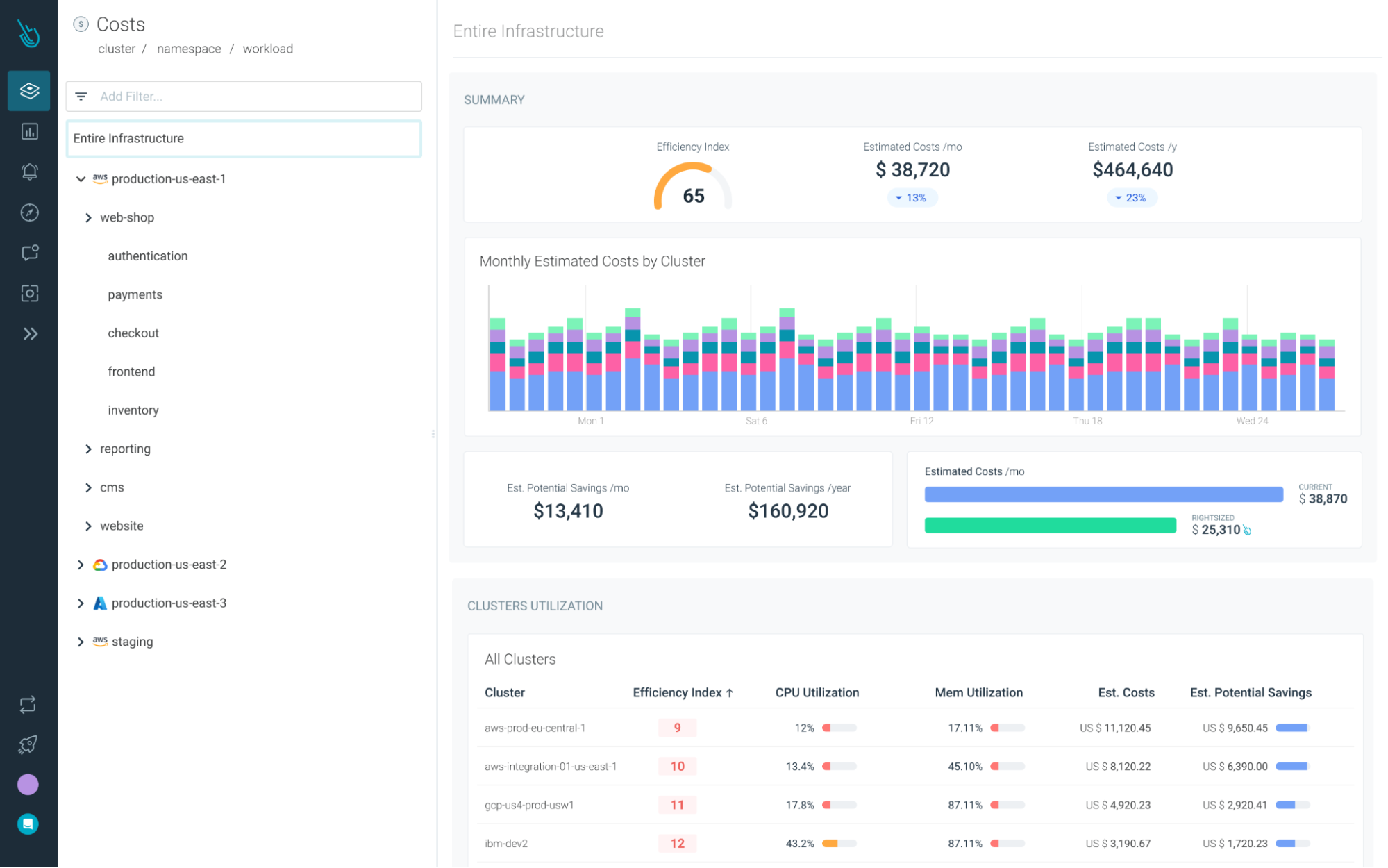
Sysdig Monitorでkubernetesのコストを最適化しましょう!
30日間無料でお試しください!
同社は、IT部門を整理し、DevOpsの思想に近いものに進化させることができるようになります。チームはオンコールローテーションサイクルを調整することができ、たとえそれがまだリアクティブな戦略であったとしても、会社が提供するサービスの可用性と信頼性は大きく改善されます。
新しいクラウド監視により、開発エンジニアとサイト信頼性エンジニア(SRE)は、サービス全体の可用性に影響を与えることなく、新機能をテストするためのカナリアリリースで、より速い開発サイクルを実行できるようになります。これは、より速く、より安全に新機能を提供できるようになった会社全体へのビジネスインパクトとなります。
庭師フェーズ
クラウド監視の旅における庭師フェーズは、前フェーズの自然な進化です。マシン、サービス、アプリケーションの可用性の問題を解決しなければならないエンジニアリング・チームは、それらを植物のように見るようになります。「十分なリソースがあれば、大丈夫だろう」と。植物の場合、リソースとは光、水、土であり、クラウドデプロイの場合、リソースとは通常、CPU、メモリ、ディスク、ネットワークです。
この段階では、アプリケーションやサービスはまだブラックボックスと見なされているが、アウトプットだけでなく、それらが受け取るインプットも監視することで、より早く、より良いトラブルシューティングを行うことができます。また、ディスクの容量不足、マシンの低容量、サービスの適正サイズなど、潜在する問題を予測・予防することもできます。
このフェーズでは、クラウドアーキテクトやソリューションアーキテクトの役割が登場し、新しいクラウドモニタリング機能がブロックしない2つのベストプラクティスがあります。1つはキャパシティ・プランニングで、ユーザー数、使用量、その他のパラメータに基づいて、将来必要となるキャパシティを正しく定義し、予見するために使用されます。
このステージで利用できる2つ目の新しい手法は、リソースの動的サイジングです。これは、使用状況に応じてインスタンスを作成または破棄する仮想マシン群から、Kubernetesクラスターにおける水平ポッドオートスケーリング(HPA)戦略まで、さまざまなレイヤーのクラウド技術で利用可能です。
医師フェーズ
このフェーズは、クラウド監視の哲学の根本的な変化を意味します。アプリケーションとサービスはもはやブラックボックスではなく、エンジニアリングチームは、医師がX線を使って体の内部を見るのと同じように、それらからカスタムメトリクスを収集し始めるのです。
アプリケーションのカスタムメトリクスは、SREチームの専門性を高め、データベース、キャッシュ、ウェブサーバなどのサービスをチューニングして、パフォーマンスを向上させ、障害を防ぐことができるようになります。サービスのサチュレーション状態を推測しようとしていたクラウド監視ソリューションが、サービスの内部を見て、キャッシュやバッファのヒット率、利用可能な接続、その他の内部メトリクスをチェックし、問題がお客様とビジネスに影響を与える前にSREに警告することができるようになります。
エンジニアフェーズ
サードパーティアプリケーションのカスタムメトリクスをしばらく使っていると、エンジニアチームは自分たちのアプリケーションにこの透明性が欠けていることを知り始めます。このフェーズのエンジニアは、カスタムメトリクスで社内アプリケーションを計測し、DIYメトリクスの利点を生かして、自分たちのアプリケーションの改良、調整、トラブルシューティングを行うことができます。
環境とアプリケーションの健康状態を一目で把握し、根本原因をよりよく特定し、システム全体の効率を監視し、行動を起こすことができるようになります。そのために、PrometheusやOpenTelemetryなど、さまざまなテクノロジーでコードをインスツルメンテーションするためのさまざまなライブラリを活用します。このフェーズで採用すべきベストプラクティスは、新しい機能やモジュールの設計の一部として、メトリクスをインストルメント化することです。アプリケーションが公開するメトリクスを定義する際に、アプリケーションの保守とトラブルシューティングを行うSREが関与します。このようにして、設計チームと本番環境チームが、企業の観測可能性戦略の一部となるのです。
ストラテジストフェーズ
インフラストラクチャーとアプリケーションの全容を把握できることは、会社全体にとってのメリットになります。さらに、この可視性にコストの可視性が伴い、それと相関関係があれば、魔法が起きます。ストラテジストフェーズでは、技術インフラストラクチャーは、すべての組織レベルに影響を与えるFinOps効率化マシンに変換されます。
FinOpsチームは、より良い監視がいかにコストの最適化をもたらすかを知ることができます。インフラストラクチャーとアプリケーションの可視性が不十分な状態では、情報に基づいた意思決定を行うことができません。長期的に見ると、改善できる分野、問題を発生させるプロセス、接続されたアプリケーションの効率性などが本当のところわからないということになります。
法務部門の側でも、サービスレベルアグリーメントを作成し、その達成度を把握することで、お客様の満足度にも影響を与えることができます。SLA契約は、お客様やユーザーに透明性を与える成熟した監視システムがあって初めて可能になります。
この最終ステージでわかるように、財務や法務など、より多くの部門が監視を積極的に利用し、活用するようになります。これは、彼らが企業の監視戦略に関与し、何をどのように監視するかという決定に参加する必要があることを意味します。
まとめ
クラウドネイティブなインフラストラクチャーとアプリケーションの採用が進んだことで、インフラストラクチャーとアプリケーションを可視化する必要性が叫ばれています。よりディープな監視と適切なツールに支えられた戦略的アプローチにより、コストの最適化やメトリクスを実用的なインサイトに変換して効率を向上させることができるなど、企業全体にとってのメリットを実現することができます。
Sysdig MonitorでKubernetesのコストを削減する
Sysdig Monitorは、監視の旅における次のステップへの到達を支援します。Cost Advisorを使えば、Kubernetesのリソースの無駄を最大40%削減することができます。
また、アウトオブボックスのKubernetesダッシュボードを利用すれば、数回のクリックで十分に活用されていないリソースを発見することができます。
Sysdig Monitorでkubernetesのコストを最適化しましょう!
30日間無料でお試しください!