

本文の内容は、2023年11月24日に JOSEPH YOSTOS が投稿したブログ(https://sysdig.com/blog/library-based-vulnerability-detection/)を元に日本語に翻訳・再構成した内容となっております。
発見される脆弱性の数は毎年増え続けており、これらのリスクに対処し、優先順位を付けるために脆弱性管理ツールが急速に進化しています。しかし、脆弱性管理は依然としてサイバーセキュリティにおいて圧倒的に時間のかかる分野の 1 つです。特に誤ったアラートを減らし、本物の脅威を優先するという点で、改善の余地がまだ多くあります。
脆弱性スキャンプロセスは、以下の 4 つの段階に分けることができます。
- 資産の取得:資産のコンテンツにアクセスしてスキャンする
- 分析: SBOM (ソフトウェア部品表)の抽出
- 脆弱性のマッチング:脆弱性を SBOM に合わせて調整する
- ポリシーの評価とリスクの受容:特定された脆弱性のリスクレベルの決定
各段階には改善の余地がありますが、このブログでは第 3 段階である脆弱性のマッチングと、Sysdig によって最近導入されたイノベーションに焦点を当てます。
脆弱性検出における課題
- ソフトウェアと影響を受けるライブラリの検出:脆弱性検出における重大な課題は、影響を受けるパッケージ、特に非 OS パッケージの特定が不正確であることから発生します。たとえば、NVD ( National Vulnerability Database ) を含む多くの CVE データ ソースは、パッケージ レベル (org.apache.logging.log4j.LogManager など) ではなくソフトウェア レベル ( Log4jなど) で検出情報を提供することがあります。アプリケーション内のすべてのパッケージが脆弱であるとは限らないため、この不一致は誤検知につながる可能性があります。
以下に例を示します。log4j 脆弱性 (CVE-2021-44228) の NVD ページには、影響を受けるソフトウェアのみがリストされており、脆弱なライブラリは特定されていません。
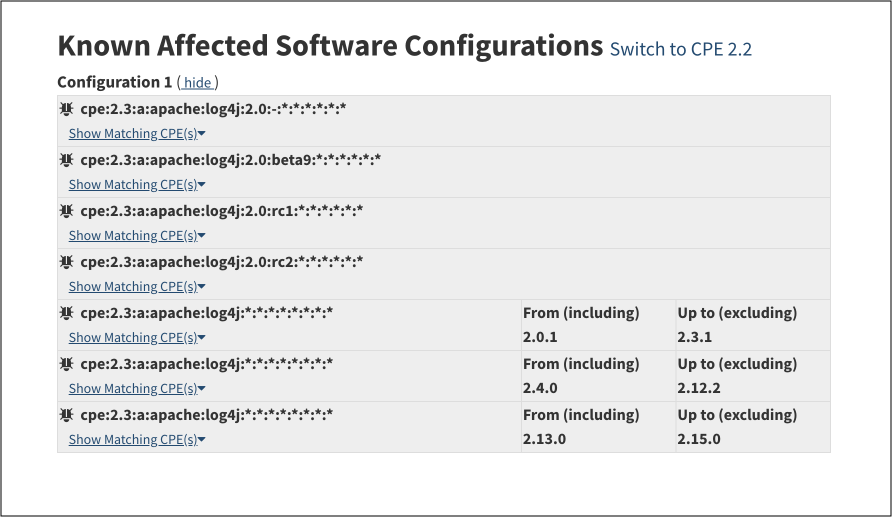
対照的に、GitHub アドバイザリーデータベースなどの他のデータ ソースは、影響を受ける唯一のパッケージが ”org.apache.logging.log4j:log4j-core” であることを正確に特定します。
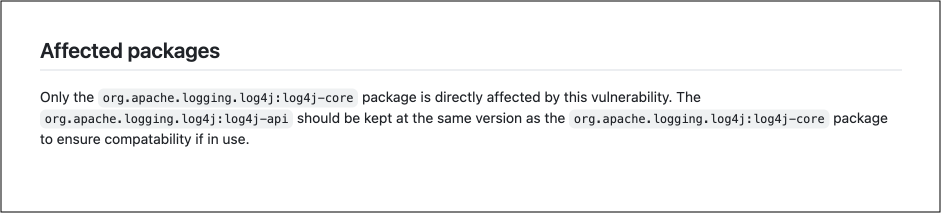
- バージョン管理と名前付けの不一致:多くのデータ ソースは、たとえば、v2.4.1 以下のものは脆弱であると述べて、さまざまな脆弱なアプリケーションやパッケージを提供しています。ただし、各メーカーが異なる命名スキーマとバージョン管理スキーマに従っているため、これは複雑になります。たとえば、あるメーカーは 4 桁 (または 4 レベル) のバージョン番号を使用し、別のメーカーは「セマンティック バージョニング」または「SemVer」として知られる 3 つのピリオド区切り記号を採用しています。このバージョン管理と命名の不一致には多くのキュレーションが必要であり、場合によっては誤った一致シナリオが発生することがあります。
OS以外の脆弱性検出の強化
Sysdig は、パッケージマッチングの忠実度を向上させるためにいくつかの手順を取っています。
GitHub + GitLab の統合
Sysdig は GitLab オープンソース、および、GitHub セキュリティアドバイザリーデータベースからのセキュリティフィードを組み込むことにより、非 OS パッケージの影響を受けるライブラリに基づいて統合した検出を行います。通常、2 つのアドバイザリーデータベースには、脆弱な各ライブラリに関する詳細情報が含まれており、定期的に更新されます。情報は、多くの場合、より広範なセキュリティ コミュニティからの意見をもとに厳選され、信頼性と透明性のレベルが確保されています。
とは言っても、弊社は引き続き VulnDB データセットを使用して脆弱性メタデータを補完します。たとえば、特定の脆弱性が発見され公開された日付を取得し、データ、スコア、概要/説明を活用します。
複数のソースからの結果のキュレーション
Sysdig は、10 を超える検出ソースからの結果を統合します。GitHub および GitLab アドバイザリーデータベースを超えて、Sysdig は最近、Ruby、Python、および PHP からのセキュリティフィードを組み込み始めました。
複数のデータ ソースから報告された脆弱性を相互参照することは、その信頼性と重大度を検証するのに役立ちます。さらに、一部のフィードは、潜在的な緩和策、悪用の可能性、現実世界への影響など、脆弱性に関するより豊富なコンテキスト情報を提供する場合があります。複数のフィードを使用すると、これらの詳細なコンテキストが存在する場合に確実に情報を取得できます。
プロアクティブな脆弱性の検出と特定
Sysdig は、以前のデータセットや業界のオープンソースベンチマークに対する再現率、精度、および F1 スコアを監視するための検出用の自動テストハーネスを実装しました。これにより、検出の差異を積極的に特定できるようになります。
結果
より広範なソフトウェアカテゴリではなく、影響を受けるライブラリに焦点を当てるという Sysdig のアプローチは、具体的な結果を示しています。GitHub や GitLab などの信頼できるソースからのデータを優先し、他の多様なデータ ソースを統合することにより、検出精度が顕著に向上し、誤検知が大幅に減少しました。例えば:
- Log4shell: 影響を受けるライブラリは 3 つになり、以前の 101 から減少しました。
- SpringShell: 影響を受けるライブラリは 7 つになり、以前の 21 から減少しました。
- CVE-2017-16026: 影響を受けるライブラリは 1 つになり、以前の 13 から減少しました。
- CVE-2015-9251: 影響を受けるライブラリは 2 つになり、以前の 11 から減少しました。
まとめ
脆弱性管理の領域は複雑であり、常に進化しています。サイバー脅威がより巧妙になるにつれて、脆弱性検出ツールが一歩先を行くことが不可欠です。脆弱性照合の改良における Sysdig の最近の進歩は、精度と包括的なデータソーシングの重要性を強調しています。Sysdig は、影響を受けるライブラリにアプローチを集中させ、データ ソースを多様化することで、検出精度を向上させるだけでなく、脆弱性管理プロセスに大きな信頼をもたらします。サイバーセキュリティの状況が進化し続ける中、このようなイノベーションは継続的な適応と完璧さの絶え間ない追求の重要性を示しています。